 1.2MB數據如何吃掉10GB內存
1.2MB數據如何吃掉10GB內存

以下文章來源于阿里云開發者,作者竹一
導讀
一個特殊請求引發服務器內存用量暴漲進而導致進程 OOM 的慘案。
問題背景
埋點網關是螞蟻基于 nginx 開發的接入網關應用,作為應用接入層網關負責移動端埋點數據采集,從去年年底開始有偶現的進程 crash 問題。
好在 nginx 設計中 worker 進程閃退后 master 進程會重新拉起新的進程處理請求,埋點客戶端也有重試機制,偶現閃退沒有造成大的影響。
初步分析
說實話作為 C 語言應用,crash 也沒什么好奇怪的 :),第一反應當然是業務代碼有問題,查看機器內存的占用也沒有大的起伏。
所以先排除了內存泄漏最終 OOM 導致進程閃退。大概率是內存沒用好,內存越界訪問導致的。這種問題排查起來也挺簡單,找部分機器開啟 core-dump,拿到 core 文件一看就知道是哪里跪了。說干就干,線上找了部分機器開啟開關,等問題復現后登錄,就遇到了第一個難題:沒有生成核心轉儲文件。
反復檢查 core-dump 開關確認已經正確打開,再回頭檢查了一遍最近的代碼變更,也沒看出什么疑點,這時候就有點一籌莫展了。
如果不是
在走迷宮時,如果發現前面無路可走,就得回頭思考前面哪一步是不是走錯了。
一開始排除了內存泄漏導致的 OOM 問題,是因為從監控上看內存占用水位只有 40% 不到,并沒有上漲到內存用完。然而這里的監控是分鐘級的,如果內存在短時間內暴漲,秒級尖刺體現到分鐘級監控上很可能被平均值抹平。
再結合沒有產生 core-dump 文件的現象,如果是內存耗盡導致進程被 oom-killer 進程殺死是說得通的。因為oom-killer 進程使用SIGKILL信號強制殺死進程,查看 Linux 信號手冊,根據 POSIX.1-1990 標準,SIGKILL信號意味著進程被強制結束并且不進行核心轉儲。
Signal Standard Action Comment ──────────────────────────────────────────────────────────────────────── ... SIGIOT - Core IOT trap. A synonym for SIGABRT SIGKILL P1990 Term Kill signal SIGLOST - Term File lock lost (unused) ...瞌睡遇上枕頭,剛好發現監控平臺上線了單機秒級監控(感謝平臺工具給力),再找到發生 crash 的機器和時間點,發現推測是對的,在幾秒內其中一個 worker 進程內存占用飆升,從幾百 MB 一路暴漲到十幾 GB,在 8C16G 規格的機器上很快就因為內存耗盡被內核殺掉。
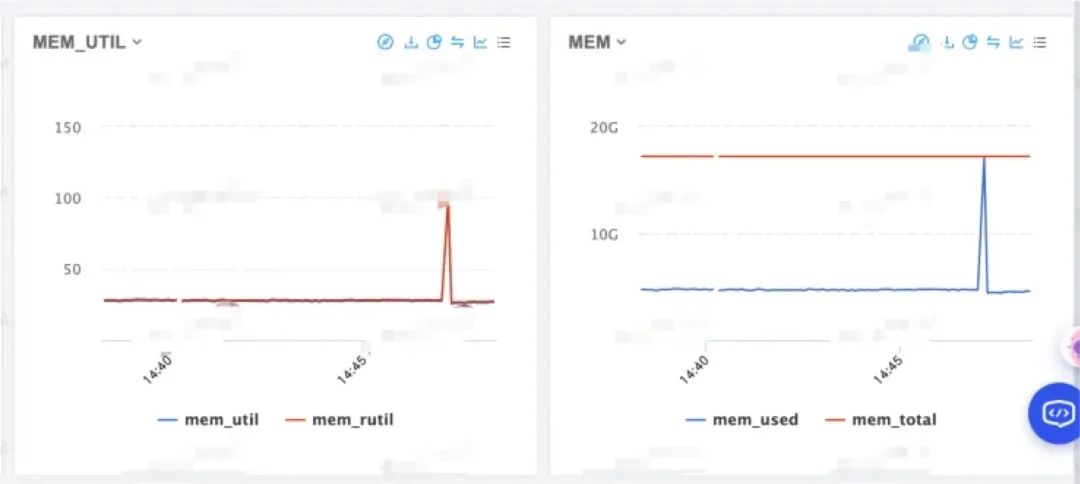
問題查到這里,好消息是排查方向總算對了,壞消息是 OOM 進程閃退只是問題的表現,而導致內存飆升的根本原因還是沒什么頭緒。
懷疑有異常的攻擊流量,然而查看閃退前后該機器的網絡流量,inbytes 和 outbytes 并沒有波動,所以也基本排除了被突發流量攻擊;懷疑是網關上 ip geo 信息查詢的二分查找邏輯有死循環,經過代碼檢查和測試也沒發現這里有問題;甚至懷疑系統跑久了有內存碎片,但經過排查也排除了這種可能,今年之前也沒出現這種問題。
所以目前的情況就是在沒有任何外部攻擊的情況下,系統內存突然就爆了。這還真是見了鬼,排查了這么多問題,如此詭異的情況也是少見。
core-dump!
core-dump 文件是進程閃退前最后的“遺照”,類似尸檢之于法醫,對于查問題能提供非常多線索。拿不到轉儲文件真是兩眼一抹黑 —— 全靠猜。所以痛定思痛,決定想辦法把 core-dump 文件拿到。
既然閃退是因為內存占用過高,而被 oom-killer 殺死又不會進行核心轉儲,總不能到 Linux 內核里修改 oom-killer 發送的信號。在跟師兄討論時,師兄提出一個思路:在用戶態實現一個 oom-killer(青春版),當然沒有復雜的打分邏輯,只需要檢測目標進程的內存用量,到閾值之后發送一個可以產生內核轉儲行為的信號來殺死進程,通過主動殺死進程的方式產生 core-dump 文件。
后面師兄抽空幫忙寫了一個 nginx 輔助進程,邏輯是每秒檢測一次所有 worker 進程的內存用量,如果超過一定閾值就發送SIGABORT信號主動殺死對應進程。當然為了防止工具誤殺導致更嚴重的問題,限制在應用重啟后的生命周期內最多只會觸發一次。
找了部分機器部署之后,還真給拿到了 core-dump 文件,不過還有個小插曲,第一次拿到的文件過大發生了截斷,后續又將單進程的內存閾值從 8GB 調整為 4GB,終于拿到了完整可用的 core-dump!
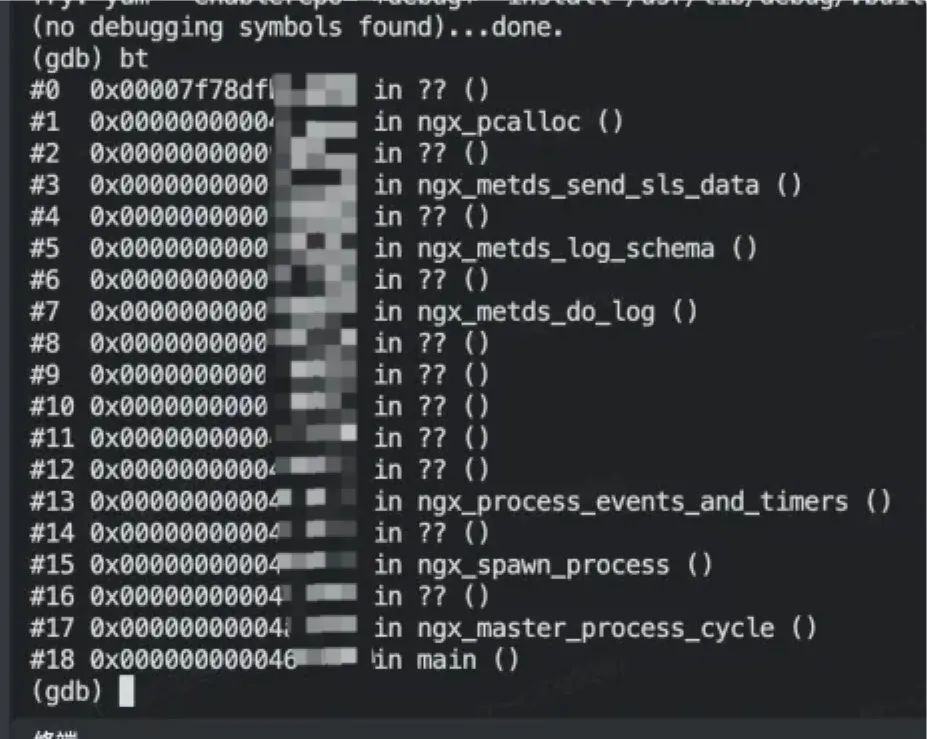
如上圖可以看到程序的堆棧,這種通過自殺產生的內核堆棧不像內存越界的堆棧直接指向了程序崩潰點,當前的堆棧只能反應程序在異常時執行的代碼,不一定是準確的問題點,但也能提供非常多的線索。從堆棧結合代碼可以看出程序正在進行數據攢批寫出, 再往前是 schema 埋點數據的拆分,攢批寫出時恰好在調用 ngx_pcalloc 函數從內存池中申請內存,所以很可能是在 schema 埋點數據拆分之后的攢批發送時內存分配出了問題。
合理猜測
在繼續分析之前插入一個我們的業務流程,大致可以分為請求接收、數據處理、數據攢批、數據發送幾個階段,為了保護埋點網關,在這些階段分別設置了數據大小限制:
數據解壓前的 body 大小限制 4MB 以內;
解壓后的數據限制 32MB 以內;
而拆分后單條埋點大小限制根據業務類型動態調整,最大支持 2MB;
既然程序申請了這么多內存,也拿到了 core-dump,直接將內存 dump 出來看看里面都裝了些什么數據,根據數據的內容可以大概推測是哪個節點申請的內存。再將之前的 core-dump 文件翻出來尋找蛛絲馬跡,從內存中看到大量攢批完成準備發送的日志內容,說明很可能是數據攢批發送階段占用了大量內存。
數據從攢批到發送階段的內存管理使用了內存池,開始攢批時創建內存池,在攢批完成后會將數據打包為 HTTP 協議發送出去,期間會經過 ProtoBuf 序列化、壓縮、生成簽名等流程,最后數據寫出成功后將內存池整體釋放。
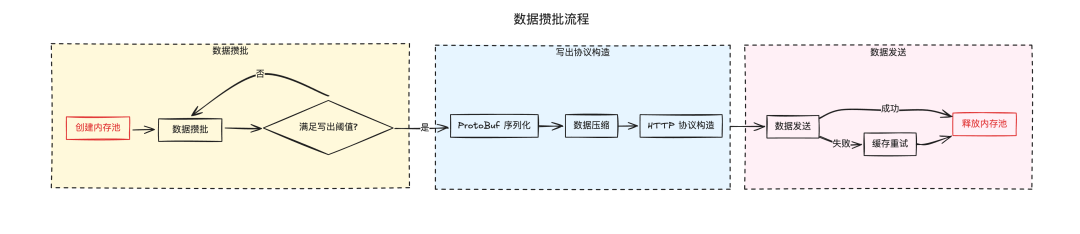
仔細分析這里內存相關的動作,有一個問題是內存的分配比較粗曠,因為有部分數據有單條超大埋點的需求,比如客戶端閃退堆棧數據,在數據攢批階段為了保證每次攢批至少能存放一條以上的數據,所以內存池創建時的最低大小設置為攢批閾值 + 單條埋點最大限制 + 部分協議元數據大小,最終這個值大約是 3MB,意味著創建一個寫出請求至少會申請 3MB 內存。但正常情況下數據發送相對數據流入的數量級會少很多,寫出請求的創建也會隨著請求流入和數據攢批打散,內存池在數據寫出完成后就會釋放,內存的輪轉速度非常快,所以網關的內存占用并不高,僅有 30% 左右。
將目光轉向內存池的釋放階段,該階段是在 HTTP 數據發送完成并收到響應后做的,沒有提前釋放是因為若數據寫出失敗,網關需要將數據暫存到內存或磁盤中,在后續進行重試,看起來好像也沒有什么地方會有發生急性內存泄漏。
但考慮極端情況,如果前面的數據攢批速度遠超數據寫出呢?會一瞬間創建大量寫出請求,而數據發送到下游,同機房的一個 rt 大約 20ms,如果從上海跨機房調用到河源,一個 rt 就需要 40ms 了,若數據還沒來得及寫出完成并釋放內存池,理論上有可能導致內存占用飆升。但從之前的分析看,問題機器上并沒有大量數據涌入,若是單個請求過大,對于單個請求還有 4MB 的數據大小限制,怎么才能一瞬間將整個內存超過 10GB 的空間打滿?
四兩撥千斤
以上都是猜測,既然懷疑是這里,干脆就加監控指標發上去看看內存究竟申請了多少。上線后發現在問題機器閃退的時間點,創建寫出請求的數量確實出現了一個明顯尖刺,由于之前增加了進程內存限制,這里還沒有漲更高就因為觸發閾值被殺死。到這里問題的直接原因算是定位到了:短時間內創建了大量數據寫出請求,內存池來不及釋放,導致內存瞬間被打爆。
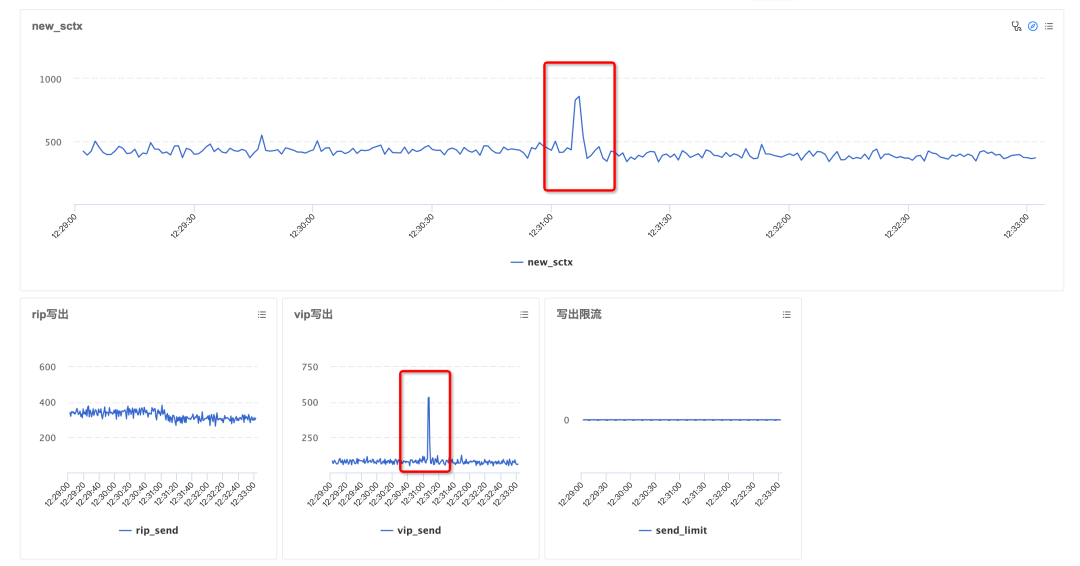
打破砂鍋問到底,又是什么場景下會集中創建寫出請求呢?兩種可能:
有大量上報請求流入。之前也提到過,從單機的網絡流量監控來看,問題時間點并沒有波動,并且這臺機器上的其他 worker 進程也沒有問題,所以基本可以排除第一種場景。
單次上報請求中攜帶了非常多數據。而對于單次請求,網關有設置 4MB 的原始數據限制,攜帶超過 4MB 的數據上報會被直接拒絕服務。難道這不到 4MB 的數據經過一系列處理和攢批,真就撬動了超 10GB 的內存消耗?
從之前的內存 dump 中又發現了可疑的地方,一個用戶的 uid 在內存里重復了 6 萬次!再細看重復的數據,大部分字段都是相同的,僅有 timestamp、startTime、endTime 等時間戳字段不同。到這里第一時間想到的是一種攻擊方式——壓縮炸彈。大量重復字符,意味著更高的數據壓縮率,因為不論是 LZ77 算法、哈夫曼編碼還是字典編碼,壓縮算法的核心都是利用各種手段減少重復數據占用的存儲空間。
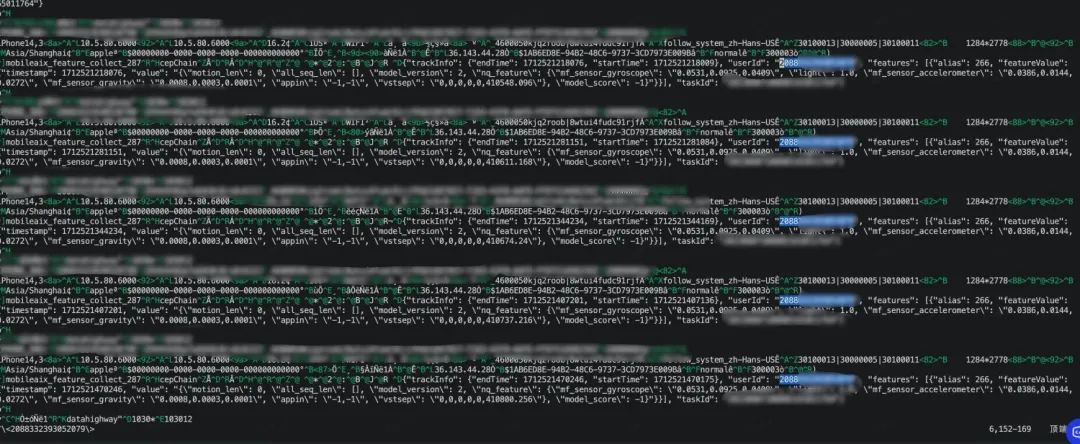
正常線上的請求壓縮率根據業務上報策略的差異平均會在 30% 左右,而如果數據大量重復,這個壓縮率則會非常高。根據 dump 出來的數據,簡單擼了個腳本手動構造出類似的測試數據,時間戳隨機遞增,其他耗時相關的字段取隨機數,剩余字段用固定 mock 值。
執行結果如下,單條埋點經過 ProtoBuf 序列化后為 3.47KB,一萬條埋點打包后原始數據有 34.7MB,壓縮后只剩 1.2MB,壓縮率達到恐怖的 3.5%,這就能解釋為何前面有 4MB 的 body 大小限制但沒能防住超大數據上報。
origin data bytes: 34697723 compressed data bytes: 1214252
真相大白
將 mock 出的原始數據裁剪到 32MB 以內再發送到埋點網關,果然復現了內存暴漲并閃退的問題。埋點網關對于文本類埋點有單次請求最多攜帶的埋點條數限制,而對于 ProtoBuf 類型的 schema 埋點還沒有做限制。于是在生產環境先增加了對超量 schema 埋點上報的告警,發現確實存在零星攜帶超量埋點的請求,接著再對 schema 類型的埋點增加了條數限制后果然再沒有閃退,可以確認根本原因是這里了。
但話說回來,這次上報雖然日志條數非常多,就算有重復數據的壓縮率高問題,解壓后最多也就 32MB 的原始數據,又是如何放大到超過 10GB 呢?
答案也在 dump 出的數據內容中,可以看到大量重復數據的埋點業務碼,對應業務對數據的時效性要求非常高,所以數據攢批閾值設置得很小,每攢夠 25.6KB 即會觸發一次日志寫出。意味著一個 32MB 原始數據的請求上來,在數據攢批發送時會瞬間創建出大約 1250 個寫出請求,每個寫出請求的內存池至少 3MB,就會申請出總計 3.75GB 的內存。
話又說回來,3.75GB 離 10GB 還是差很遠,因為還沒完,端特征埋點因為有實時消費需求,所以網關會同時寫出三份數據,一份寫出到 SLS,還有兩份分別發送到不同的應用系統,每個寫出通道都有獨立的數據攢批發送流程,最終申請的內存大小就是 3.75GB * 3 = 11.25GB。
排查到這里,問題的原因鏈條就比較完整了:
單次請求攜帶大量埋點數據,因為重復字段多壓縮率足夠高,所以繞過了前面對請求 body 的尺寸限制;
埋點網關在數據攢批發送階段的內存池分配粗曠,默認按鏈路的最大閾值來分配內存,并且內存池釋放依賴請求寫出完成,內存釋放速度遠小于數據流入速度;
高時效、多份寫出的業務特性,更是讓原本粗曠的內存管理雪上加霜,這些因素疊加在一起,最終撬動了超過 10GB 的內存消耗;
話又又又說回來,以前為什么沒有出現這個情況?
因為埋點網關的數據大小限制經歷了幾次調整,為了支持客戶端閃退這類超大埋點的上報,網關分別將數據大小限制從壓縮后 2MB、解壓后 16MB、單條埋點 256KB 調整到了當前的壓縮后 4MB、解壓后 32MB、單條埋點限制支持根據業務動態調整,也就間接達成了原因鏈條里的第二個因素。
解決方案
之前為 schema 埋點增加了單次請求最多攜帶的埋點條數限制,閃退問題雖然已經解決,但排查下來可以發現閃退是各種因素疊加在一起導致的結果,這些地方都還有優化空間,對于埋點網關這種百萬 QPS 的在線服務,性能和穩定性的優化非常有必要。
對于數據攢批發送,內存池很大一部分空間被原始數據占用,其實原始數據在經過 Protobuf 序列化及壓縮后就不再需要了,因為 HTTP 請求發送和后續的失敗緩存使用的都是壓縮后數據。原始數據使用的這塊內存可以提前到請求發送之前就釋放,不用等待請求結束才能釋放內存。而壓縮之后的數據量大約只有原始數據的十分之一,大幅提升內存的輪轉效率。
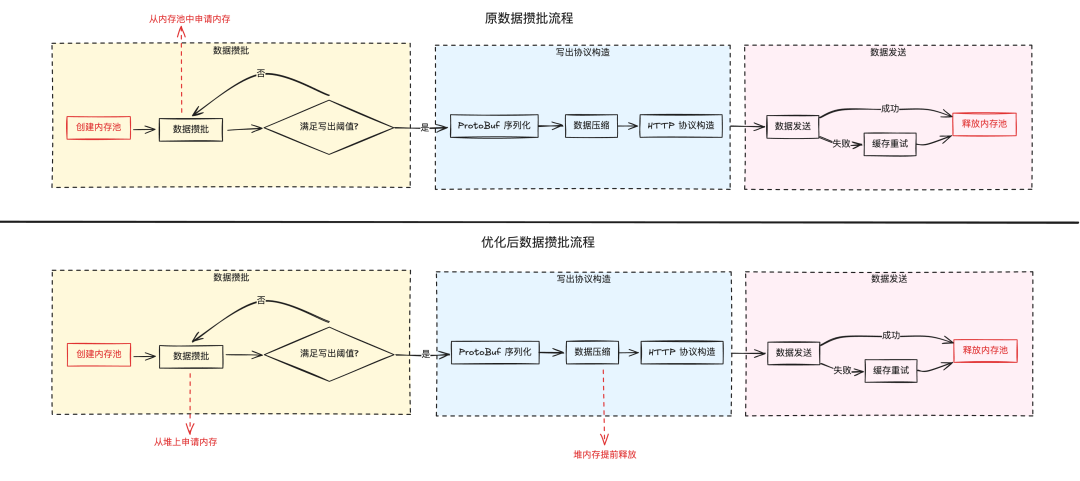
內存的分配其實也可以更精細,之前為每個寫出請求分配了 3MB 內存,是為了支持單條超大埋點,例如客戶端閃退埋點一條最大可能達到 2MB,為了保證攢批時至少能存一條埋點,并且網關的內存資源比較寬裕,這塊內存池創建得很大,實際使用中大部分業務攢批都用不到這么大的內存,可以改為根據攢批數據量動態擴容。
除了這些縫縫補補,我們也在探索使用內存安全的語言比如 Rust 來實現更多能力,這里不過多展開。
小結
歷時半年之久,經過反復猜測、修改、驗證,終于將網關上這個“定時炸彈”成功拆除,在成功復現并定位到根因后真是長舒一口氣,總結下來一點小小的心得(主要還是心理層面的,技術方面還需要一題一議,不具有普適參考價值):
堅信任何現象都有其背后的原因,在排查時苦于找不到方向,屢次道心破碎想過放棄,但線上的閃退告警時刻提醒著“革命尚未成功,同志仍需努力”。
沒有思路時可以拿出來和別人討論案情,思維碰撞中往往會有靈光乍現。
大膽假設,小心求證。通過現象推測可能的原因并一一驗證,同時要有將之前的假設都推翻重來的勇氣。
-
網關
+關注
關注
9文章
5631瀏覽量
52882 -
服務器
+關注
關注
13文章
9783瀏覽量
87818 -
內存
+關注
關注
8文章
3119瀏覽量
75204 -
C語言
+關注
關注
180文章
7632瀏覽量
141436
原文標題:“四兩撥千斤”——1.2MB數據如何吃掉10GB內存
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
做TYPE-C轉接需要達到傳輸數據10GB/s,該用什么設備儀器檢測?
10Gb以太網物理層接口的發展趨勢
10Gb子系統示例如何設計
10Gb/s時鐘數據恢復電路行為級模型研究
BLADE和Voltaire推出高密度10Gb以太網網絡方案
OPPO Find X,是世界上第一款擁有10GB運存的手機
OPPO Find X成為了世界上第一款用上了10GB內存的手機
一加6T邁凱倫定制版搭載10GB運行內存支持全新Warp閃充30
用10GB的vivoNEX雙屏版玩游戲怎么樣
Linux吃掉我的內存
華為 Mate 40/Pro系列搭載全新內存擴展技術:8GB等效10GB ,12GB等效14GB
10GB顯存容易在4K等游戲中爆顯存,是真的嗎
ADN2815:連續速率10 Mb/s至1.25 Gb/s時鐘和數據恢復IC數據表






 工商網監
工商網監
評論