") k-means算法原理解析
k-means算法原理解析

K-MEANS算法
K-MEANS算法是輸入聚類個(gè)數(shù)k,以及包含 n個(gè)數(shù)據(jù)對(duì)象的數(shù)據(jù)庫(kù),輸出滿足方差最小標(biāo)準(zhǔn)k個(gè)聚類的一種算法。k-means 算法接受輸入量 k ;然后將n個(gè)數(shù)據(jù)對(duì)象劃分為 k個(gè)聚類以便使得所獲得的聚類滿足:同一聚類中的對(duì)象相似度較高;而不同聚類中的對(duì)象相似度較小。
聚類相似度是利用各聚類中對(duì)象的均值所獲得一個(gè)“中心對(duì)象”(引力中心)來進(jìn)行計(jì)算的。
K-Means聚類算法原理
K-Means算法是無監(jiān)督的聚類算法,它實(shí)現(xiàn)起來比較簡(jiǎn)單,聚類效果也不錯(cuò),因此應(yīng)用很廣泛。K-Means算法有大量的變體,本文就從最傳統(tǒng)的K-Means算法講起,在其基礎(chǔ)上講述K-Means的優(yōu)化變體方法。包括初始化優(yōu)化K-Means++, 距離計(jì)算優(yōu)化elkan K-Means算法和大數(shù)據(jù)情況下的優(yōu)化Mini Batch K-Means算法。
1. K-Means原理初探
K-Means算法的思想很簡(jiǎn)單,對(duì)于給定的樣本集,按照樣本之間的距離大小,將樣本集劃分為K個(gè)簇。讓簇內(nèi)的點(diǎn)盡量緊密的連在一起,而讓簇間的距離盡量的大。
如果用數(shù)據(jù)表達(dá)式表示,假設(shè)簇劃分之間的隨機(jī)數(shù)為(C1,C2,。。.Ck),則我們的目標(biāo)是最小化平方誤差E:
E=∑i=1k∑x∈Ci||x?μi||22E=∑i=1k∑x∈Ci||x?μi||22
其中μi是簇Ci的均值向量,有時(shí)也稱為質(zhì)心,表達(dá)式為:
μi=1|Ci|∑x∈Cixμi=1|Ci|∑x∈Cix
如果我們想直接求上式的最小值并不容易,這是一個(gè)NP難的問題,因此只能采用啟發(fā)式的迭代方法。K-Means采用的啟發(fā)式方式很簡(jiǎn)單,用下面一組圖就可以形象的描述。
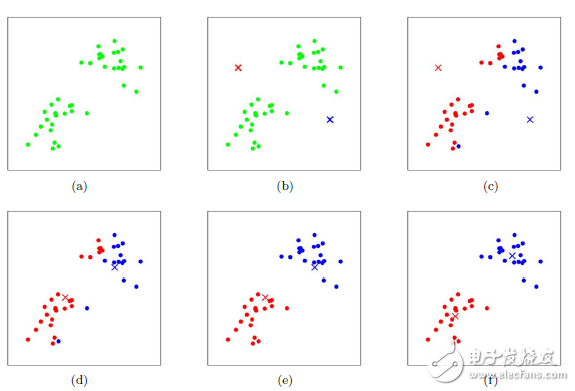
上圖a表達(dá)了初始的數(shù)據(jù)集,假設(shè)k=2。在圖b中,我們隨機(jī)選擇了兩個(gè)k類所對(duì)應(yīng)的類別質(zhì)心,即圖中的紅色質(zhì)心和藍(lán)色質(zhì)心,然后分別求樣本中所有點(diǎn)到這兩個(gè)質(zhì)心的距離,并標(biāo)記每個(gè)樣本的類別為和該樣本距離最小的質(zhì)心的類別,如圖c所示,經(jīng)過計(jì)算樣本和紅色質(zhì)心和藍(lán)色質(zhì)心的距離,我們得到了所有樣本點(diǎn)的第一輪迭代后的類別。此時(shí)我們對(duì)我們當(dāng)前標(biāo)記為紅色和藍(lán)色的點(diǎn)分別求其新的質(zhì)心,如圖4所示,新的紅色質(zhì)心和藍(lán)色質(zhì)心的位置已經(jīng)發(fā)生了變動(dòng)。圖e和圖f重復(fù)了我們?cè)趫Dc和圖d的過程,即將所有點(diǎn)的類別標(biāo)記為距離最近的質(zhì)心的類別并求新的質(zhì)心。最終我們得到的兩個(gè)類別如圖f。當(dāng)然在實(shí)際K-Mean算法中,我們一般會(huì)多次運(yùn)行圖c和圖d,才能達(dá)到最終的比較優(yōu)的類別。
讀者可以通過下面這個(gè)動(dòng)態(tài)圖來形象的了解算法的實(shí)現(xiàn)過程
在上一節(jié)我們對(duì)K-Means的原理做了初步的探討,這里我們對(duì)K-Means的算法做一個(gè)總結(jié)。
首先我們看看K-Means算法的一些要點(diǎn)。
1)對(duì)于K-Means算法,首先要注意的是k值的選擇,一般來說,我們會(huì)根據(jù)對(duì)數(shù)據(jù)的先驗(yàn)經(jīng)驗(yàn)選擇一個(gè)合適的k值,如果沒有什么先驗(yàn)知識(shí),則可以通過交叉驗(yàn)證選擇一個(gè)合適的k值。
2)在確定了k的個(gè)數(shù)后,我們需要選擇k個(gè)初始化的質(zhì)心,就像上圖b中的隨機(jī)質(zhì)心。由于我們是啟發(fā)式方法,k個(gè)初始化的質(zhì)心的位置選擇對(duì)最后的聚類結(jié)果和運(yùn)行時(shí)間都有很大的影響,因此需要選擇合適的k個(gè)質(zhì)心,最好這些質(zhì)心不能太近。
好了,現(xiàn)在我們來總結(jié)下傳統(tǒng)的K-Means算法流程。
輸入是樣本集D={x1,x2,。..xm}D={x1,x2,。..xm},聚類的簇樹k,最大迭代次數(shù)N
輸出是簇劃分C={C1,C2,。..Ck}C={C1,C2,。..Ck}
1) 從數(shù)據(jù)集D中隨機(jī)選擇k個(gè)樣本作為初始的k個(gè)質(zhì)心向量: {μ1,μ2,。..,μk}{μ1,μ2,。..,μk}
2)對(duì)于n=1,2,。..,N
a) 將簇劃分C初始化為Ct=?t=1,2.。.kCt=?t=1,2.。.k
b) 對(duì)于i=1,2.。.m,計(jì)算樣本xixi和各個(gè)質(zhì)心向量μj(j=1,2,。..k)μj(j=1,2,。..k)的距離:dij=||xi?μj||22dij=||xi?μj||22,將xixi標(biāo)記最小的為dijdij所對(duì)應(yīng)的類別λiλi。此時(shí)更新Cλi=Cλi∪{xi}Cλi=Cλi∪{xi}
c) 對(duì)于j=1,2,。..,k,對(duì)CjCj中所有的樣本點(diǎn)重新計(jì)算新的質(zhì)心μj=1|Cj|∑x∈Cjxμj=1|Cj|∑x∈Cjx
e) 如果所有的k個(gè)質(zhì)心向量都沒有發(fā)生變化,則轉(zhuǎn)到步驟3)
3) 輸出簇劃分C={C1,C2,。..Ck}C={C1,C2,。..Ck}
3. K-Means初始化優(yōu)化K-Means++
在上節(jié)我們提到,k個(gè)初始化的質(zhì)心的位置選擇對(duì)最后的聚類結(jié)果和運(yùn)行時(shí)間都有很大的影響,因此需要選擇合適的k個(gè)質(zhì)心。如果僅僅是完全隨機(jī)的選擇,有可能導(dǎo)致算法收斂很慢。K-Means++算法就是對(duì)K-Means隨機(jī)初始化質(zhì)心的方法的優(yōu)化。
關(guān)于這里,原作者博客寫的有點(diǎn)兒含糊,網(wǎng)上有幾篇博客寫的不是很清楚,這里把他們總結(jié)在一起,特別對(duì)有問題的地方用紅色字體解釋和說明:
k-means++算法選擇初始seeds的基本思想就是:初始的聚類中心之間的相互距離要盡可能的遠(yuǎn)。wiki上對(duì)該算法的描述是如下:
1,從輸入的數(shù)據(jù)點(diǎn)集合中隨機(jī)選擇一個(gè)點(diǎn)作為第一個(gè)聚類中心
2,對(duì)于數(shù)據(jù)集中的每一個(gè)點(diǎn)x,計(jì)算它與最近聚類中心(指已選擇的聚類中心)的距離D(x)
3,選擇一個(gè)新的數(shù)據(jù)點(diǎn)作為新的聚類中心,選擇的原則是:D(x)較大的點(diǎn),被選取作為聚類中心的概率較大
4,重復(fù)2和3直到k個(gè)聚類中心被選出來
5,利用這k個(gè)初始的聚類中心來運(yùn)行標(biāo)準(zhǔn)的k-means算法
從上面的算法描述上可以看到,算法的關(guān)鍵是第3步,如何將D(x)反映到點(diǎn)被選擇的概率上,一種算法如下:
1,先從我們的數(shù)據(jù)庫(kù)隨機(jī)挑個(gè)隨機(jī)點(diǎn)當(dāng)“種子點(diǎn)”
2,對(duì)于每個(gè)點(diǎn),我們都計(jì)算其和最近的一個(gè)“種子點(diǎn)”的距離D(x)并保存在一個(gè)數(shù)組里,然后把這些距離加起來得到Sum(D(x))。
3,然后,再取一個(gè)隨機(jī)值,用權(quán)重的方式來取下一個(gè)“種子點(diǎn)”。
這個(gè)算法的實(shí)現(xiàn)是:先取一個(gè)能落在Sum(D(x))中的隨機(jī)值Random,然后用Random -= D(x),直到,Random《=0(注意,這個(gè)式子的意思是:在剛才保存的那個(gè)數(shù)組里,我們從頭開始遍歷每一個(gè)元素的D(x),直到減掉的Random小于0,此時(shí)停止),此時(shí)的點(diǎn)就是下一個(gè)“種子點(diǎn)”。
4,重復(fù)2和3直到k個(gè)聚類中心被選出來
5,利用這k個(gè)初始的聚類中心來運(yùn)行標(biāo)準(zhǔn)的k-means算法
可以看到算法的第三步選取新中心的方法,這樣就能保證距離D(x)較大的點(diǎn),會(huì)被選出來作為聚類中心了。至于為什么原因很簡(jiǎn)單,如下圖 所示:

假設(shè)A、B、C、D的D(x)如上圖所示,當(dāng)算法取值Sum(D(x))*random(原作者博客里這樣寫是因?yàn)樵?a target="_blank">編程語(yǔ)言中,random函數(shù)產(chǎn)生的是0-1之間的 隨機(jī)數(shù),所以他用Sum(D(x))*random來表示隨機(jī)生成一個(gè)位于[0-Sum(D(x))]之間的隨機(jī)數(shù)),該值會(huì)以較大的概率落入D(x)較大的區(qū)間內(nèi),所以對(duì)應(yīng)的點(diǎn)會(huì)以較大的概率被選中作為新的聚類中心。
4. K-Means距離計(jì)算優(yōu)化elkan K-Means
在傳統(tǒng)的K-Means算法中,我們?cè)诿枯喌鷷r(shí),要計(jì)算所有的樣本點(diǎn)到所有的質(zhì)心的距離,這樣會(huì)比較的耗時(shí)。那么,對(duì)于距離的計(jì)算有沒有能夠簡(jiǎn)化的地方呢?elkan K-Means算法就是從這塊入手加以改進(jìn)。它的目標(biāo)是減少不必要的距離的計(jì)算。那么哪些距離不需要計(jì)算呢?elkan K-Means利用了兩邊之和大于等于第三邊,以及兩邊之差小于第三邊的三角形性質(zhì),來減少距離的計(jì)算。
第一種規(guī)律是對(duì)于一個(gè)樣本點(diǎn)x和兩個(gè)質(zhì)心μj1,μj2。如果我們預(yù)先計(jì)算出了這兩個(gè)質(zhì)心之間的距離D(j1,j2),則如果計(jì)算發(fā)現(xiàn)2D(x,j1)≤D(j1,j2),我們立即就可以知道
D(x,j1)≤D(x,j2)。此時(shí)我們不需要再計(jì)算D(x,j2),也就是說省了一步距離計(jì)算。
第二種規(guī)律是對(duì)于一個(gè)樣本點(diǎn)xx和兩個(gè)質(zhì)心μj1,μj2。我們可以得到D(x,j2)≥max{0,D(x,j1)?D(j1,j2)}這個(gè)從三角形的性質(zhì)也很容易得到。
利用上邊的兩個(gè)規(guī)律,elkan K-Means比起傳統(tǒng)的K-Means迭代速度有很大的提高。但是如果我們的樣本的特征是稀疏的,有缺失值的話,這個(gè)方法就不使用了,此時(shí)某些距離無法計(jì)算,則不能使用該算法。
5. 大樣本優(yōu)化Mini Batch K-Means
在傳統(tǒng)的K-Means算法中,要計(jì)算所有的樣本點(diǎn)到所有的質(zhì)心的距離。如果樣本量非常大,比如達(dá)到10萬以上,特征有100以上,此時(shí)用傳統(tǒng)的K-Means算法非常的耗時(shí),就算加上elkan K-Means優(yōu)化也依舊。在大數(shù)據(jù)時(shí)代,這樣的場(chǎng)景越來越多。此時(shí)Mini Batch K-Means應(yīng)運(yùn)而生。
顧名思義,Mini Batch,也就是用樣本集中的一部分的樣本來做傳統(tǒng)的K-Means,這樣可以避免樣本量太大時(shí)的計(jì)算難題,算法收斂速度大大加快。當(dāng)然此時(shí)的代價(jià)就是我們的聚類的精確度也會(huì)有一些降低。一般來說這個(gè)降低的幅度在可以接受的范圍之內(nèi)。
在Mini Batch K-Means中,我們會(huì)選擇一個(gè)合適的批樣本大小batch size,我們僅僅用batch size個(gè)樣本來做K-Means聚類。那么這batch size個(gè)樣本怎么來的?一般是通過無放回的隨機(jī)采樣得到的。
為了增加算法的準(zhǔn)確性,我們一般會(huì)多跑幾次Mini Batch K-Means算法,用得到不同的隨機(jī)采樣集來得到聚類簇,選擇其中最優(yōu)的聚類簇。
6. K-Means(K-近鄰學(xué)習(xí))與KNN(k-近鄰估計(jì))
初學(xué)者很容易把K-Means和KNN搞混,兩者其實(shí)差別還是很大的。
K-Means是無監(jiān)督學(xué)習(xí)的聚類算法,沒有樣本輸出;而KNN是監(jiān)督學(xué)習(xí)的分類算法,有對(duì)應(yīng)的類別輸出。KNN基本不需要訓(xùn)練,對(duì)測(cè)試集里面的點(diǎn),只需要找到在訓(xùn)練集中最近的k個(gè)點(diǎn),用這最近的k個(gè)點(diǎn)的類別來決定測(cè)試點(diǎn)的類別。而K-Means則有明顯的訓(xùn)練過程,找到k個(gè)類別的最佳質(zhì)心,從而決定樣本的簇類別。
當(dāng)然,兩者也有一些相似點(diǎn),兩個(gè)算法都包含一個(gè)過程,即找出和某一個(gè)點(diǎn)最近的點(diǎn)。兩者都利用了最近鄰(nearest neighbors)的思想。
7. K-Means小結(jié)
K-Means是個(gè)簡(jiǎn)單實(shí)用的聚類算法,這里對(duì)K-Means的優(yōu)缺點(diǎn)做一個(gè)總結(jié)。
K-Means的主要優(yōu)點(diǎn)有:
1)原理比較簡(jiǎn)單,實(shí)現(xiàn)也是很容易,收斂速度快。
2)聚類效果較優(yōu)。
3)算法的可解釋度比較強(qiáng)。
4)主要需要調(diào)參的參數(shù)僅僅是簇?cái)?shù)k。
K-Means的主要缺點(diǎn)有:
1)K值的選取不好把握
2)對(duì)于不是凸的數(shù)據(jù)集比較難收斂
3)如果各隱含類別的數(shù)據(jù)不平衡,比如各隱含類別的數(shù)據(jù)量嚴(yán)重失衡,或者各隱含類別的方差不同,則聚類效果不佳。
4) 采用迭代方法,得到的結(jié)果只是局部最優(yōu)。
5) 對(duì)噪音和異常點(diǎn)比較的敏感。
k-means聚類算法的應(yīng)用
聚類就是按照一定的標(biāo)準(zhǔn)將事物進(jìn)行區(qū)分和分類的過程,該過程是無監(jiān)督的,即事先并不知道關(guān)于類分的任何知識(shí)。聚類分析又稱為數(shù)據(jù)分割,它是指應(yīng)用數(shù)學(xué)的方法研究和處理給定對(duì)象的分類,使得每個(gè)組內(nèi)部對(duì)象之間的相關(guān)性比其他對(duì)象之間的相關(guān)性高,組間的相異性較高。
聚類算法被用于許多知識(shí)領(lǐng)域,這些領(lǐng)域通常要求找出特定數(shù)據(jù)中的“自然關(guān)聯(lián)”。自然關(guān)聯(lián)的定義取決于不同的領(lǐng)域和特定的應(yīng)用,可以具有多種形式。典型的應(yīng)用例如:
1. 商務(wù)上,幫助市場(chǎng)分析人員從客戶基本資料庫(kù)中發(fā)現(xiàn)不同的客戶群,并用購(gòu)買模式來刻畫不同客戶群的特征;
2. 聚類分析是細(xì)分市場(chǎng)的有效工具,同時(shí)也可用于研究消費(fèi)者行為,尋找新的潛在市場(chǎng)、選擇實(shí)驗(yàn)的市場(chǎng),并作為多元分析的預(yù)處理。
3. 生物學(xué)上,用于推導(dǎo)植物和動(dòng)物的分類,對(duì)基因進(jìn)行分類,獲得對(duì)種群固有結(jié)構(gòu)的認(rèn)識(shí);
4. 地理信息方面,在地球觀測(cè)數(shù)據(jù)庫(kù)中相似區(qū)域的確定、汽車保險(xiǎn)單持有者的分組,及根據(jù)房子的類型、價(jià)值和地理位置對(duì)一個(gè)城市中房屋的分組上可以發(fā)揮作用;
5. 聚類也能用于在網(wǎng)上進(jìn)行文檔歸類來修復(fù)信息;
6. 在電子商務(wù)網(wǎng)站建設(shè)數(shù)據(jù)挖掘中的應(yīng)用,通過分組聚類出具有相似瀏覽行為的客戶,并分析客戶的共同特征,可以更好的幫助電子商務(wù)的用戶了解自己的客戶,向客戶提供更合適的服務(wù)。
7. 聚類分析可以作為其它數(shù)據(jù)挖掘算法的預(yù)處理步驟,便于這些算法在生成的簇上進(jìn)行處理。
-
K-means
+關(guān)注
關(guān)注
0文章
28瀏覽量
11499 -
k-means算法
+關(guān)注
關(guān)注
0文章
1瀏覽量
1841
發(fā)布評(píng)論請(qǐng)先 登錄
改進(jìn)的k-means聚類算法在供電企業(yè)CRM中的應(yīng)用
Web文檔聚類中k-means算法的改進(jìn)
K-means+聚類算法研究綜述

基于密度的K-means算法在聚類數(shù)目中應(yīng)用
K-Means算法改進(jìn)及優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論