") NVIDIA Ollama助力增強(qiáng)Brave瀏覽器用戶體驗(yàn)
NVIDIA Ollama助力增強(qiáng)Brave瀏覽器用戶體驗(yàn)

從游戲和內(nèi)容創(chuàng)作應(yīng)用,再到軟件開發(fā)和生產(chǎn)力工具,AI 正越來越多地集成到應(yīng)用中,以增強(qiáng)用戶體驗(yàn)和提高效率。
這些效率提升將延伸到日常任務(wù),如網(wǎng)頁瀏覽。作為一款致力于保護(hù)隱私的網(wǎng)絡(luò)瀏覽器,Brave 推出了一款名為 Leo AI 的智能 AI 助手,除提供搜索結(jié)果之外,該助手還可以幫助用戶總結(jié)文章和視頻,從文檔中獲取見解,回答問題等。
Leo AI 將幫助用戶總結(jié)文章和視頻,從文檔中獲取見解,回答問題等。
Brave 和其他 AI 賦能工具背后的技術(shù)組合了硬件、軟件開發(fā)庫和生態(tài)系統(tǒng)軟件,這類軟件經(jīng)過優(yōu)化,可滿足 AI 的獨(dú)特需求。
為什么軟件至關(guān)重要
從數(shù)據(jù)中心到 PC,NVIDIA GPU 構(gòu)建了世界的 AI。它們包含 Tensor 核心,這些核心經(jīng)過專門設(shè)計(jì),可通過大規(guī)模的并行運(yùn)算來加速 Leo AI 這類 AI 應(yīng)用—— 快速同步處理 AI 所需的大量運(yùn)算,而不是逐次運(yùn)算。
但只有當(dāng)應(yīng)用能夠高效利用強(qiáng)大的硬件時(shí),這些硬件才有意義。在 GPU 上運(yùn)行的軟件對于提供最快速和最具交互性的 AI 體驗(yàn)同樣至關(guān)重要。
第一層是 AI 推理庫,它充當(dāng)轉(zhuǎn)換器,用于接收常見的 AI 任務(wù)請求,然后將其轉(zhuǎn)換為特定指令以便硬件運(yùn)行。熱門推理庫包括 NVIDIA TensorRT、Microsoft 的 DirectML,以及 Brave 和 Leo AI 通過 Ollama 使用的名為 llama.cpp 的推理庫。
Llama.cpp 是一個(gè)開源軟件開發(fā)庫和框架。CUDA 是 NVIDIA 的軟件應(yīng)用編程接口,可幫助開發(fā)者為 GeForce RTX 和 NVIDIA RTX GPU 進(jìn)行優(yōu)化,通過 CUDA 可為數(shù)百個(gè)模型提供 Tensor 核心加速,包括熱門的大語言模型(LLM),如 Gemma、Llama 3、Mistral 和 Phi。
除推理庫以外,應(yīng)用通常還使用本地推理服務(wù)器來簡化集成。推理服務(wù)器負(fù)責(zé)處理下載和配置特定 AI 模型等任務(wù),以便減輕推理庫的負(fù)擔(dān)。
Ollama 是一個(gè)開放源代碼項(xiàng)目,它構(gòu)建于 llama.cpp 之上,提供對軟件開發(fā)庫功能特性的訪問。它支持提供本地 AI 功能的應(yīng)用生態(tài)系統(tǒng)。在整個(gè)技術(shù)棧中,NVIDIA 致力于優(yōu)化 Ollama 等工具,以便在 RTX 硬件上提供更快、響應(yīng)速度更出色的 AI 體驗(yàn)。

Brave Leo AI 等應(yīng)用可以借助 RTX 驅(qū)動(dòng)的 AI 加速,以增強(qiáng)用戶體驗(yàn)。
NVIDIA 對優(yōu)化的專注涵蓋整個(gè)技術(shù)棧——從硬件到系統(tǒng)軟件,再到推理庫和工具,以幫助 RTX 上的應(yīng)用提供更快、響應(yīng)速度更出色的 AI 體驗(yàn)。
本地與云端對比
Brave 的 Leo AI 可以通過 Ollama 在云端或本地 PC 上運(yùn)行。
使用本地模型推理具有諸多優(yōu)勢。由于無需向外部服務(wù)器發(fā)送提示詞以進(jìn)行處理,因此可獲得專有且始終可用的體驗(yàn)。例如,Brave 用戶可以獲得有關(guān)財(cái)務(wù)或醫(yī)療問題的幫助,而無需向云端發(fā)送任何內(nèi)容。此外,在本地運(yùn)行也不需要為無限制的云訪問付費(fèi)。使用 Ollama,用戶可以利用比大多數(shù)托管服務(wù)更廣泛的開源模型,后者通常只支持同一 AI 模型的一或兩個(gè)變體。
用戶還可以與專業(yè)領(lǐng)域各不相同的模型進(jìn)行交互,例如雙語模型、緊湊型模型、代碼生成模型等。
在本地運(yùn)行 AI 時(shí),RTX 能夠提供快速、響應(yīng)速度較高的體驗(yàn)。使用 Llama 3 8B 模型配合 llama.cpp,用戶可體驗(yàn)高達(dá) 149 token/s(約等于每秒 110 個(gè)單詞)的響應(yīng)速度。將 Brave 與 Leo AI 和 Ollama 搭配使用時(shí),它能更迅速地回復(fù)問題、內(nèi)容摘要等請求。
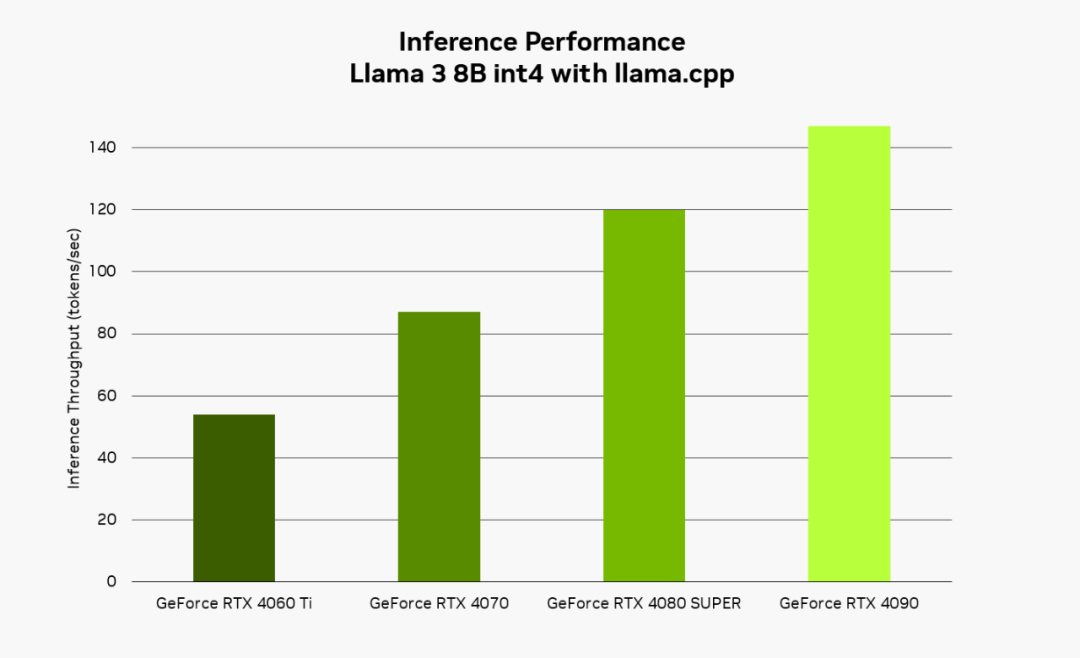
NVIDIA 內(nèi)部吞吐量性能測試:在 NVIDIA GeForce RTX GPU 上運(yùn)行 Llama 3 8B 模型,輸入序列長度為 100 個(gè) tokens,輸出為 100 個(gè) tokens。
開始使用 Brave 與 Leo AI 和 Ollama
安裝 Ollama 非常簡單——只需從項(xiàng)目網(wǎng)站下載安裝程序,然后在后臺運(yùn)行即可。用戶可以通過命令提示符下載并安裝一系列受支持的模型,然后從命令行與本地模型進(jìn)行交互。
有關(guān)如何通過 Ollama 添加本地 LLM 支持的簡單說明,請參閱該公司博客。配置好 Ollama 之后,Leo AI 將使用本地托管的 LLM 來處理用戶請求。用戶還可以隨時(shí)在云端和本地模型之間切換。
Leo AI 在 Ollama 上運(yùn)行并通過 RTX 加速,使用搭載該助手的 Brave 瀏覽器可獲得更出色的瀏覽體驗(yàn)。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5292瀏覽量
106150 -
服務(wù)器
+關(guān)注
關(guān)注
13文章
9767瀏覽量
87705 -
AI
+關(guān)注
關(guān)注
88文章
34909瀏覽量
277866
原文標(biāo)題:Brave 新世界:Leo AI 和 Ollama 為 Brave 瀏覽器用戶帶來 RTX 加速的本地 LLM
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
老電視如何安裝瀏覽器?
如何在Ollama中使用OpenVINO后端
edge瀏覽器識別 latex語法插件
在MAC mini4上安裝Ollama、Chatbox及模型交互指南
E2000 Speedometer測試瀏覽器性能
2024年12月瀏覽器市場份額報(bào)告:谷歌Chrome穩(wěn)居榜首
TMS320DM643x DMP增強(qiáng)型DMA(EDMA)控制器用戶指南

Chrome瀏覽器優(yōu)化Android性能,驍龍8至尊版表現(xiàn)突出
OpenAI醞釀創(chuàng)新:計(jì)劃開發(fā)集成聊天機(jī)器人的瀏覽器
AWTK 最新動(dòng)態(tài):支持瀏覽器控件

寫一個(gè)Chrome瀏覽器插件
不只是前端,后端、產(chǎn)品和測試也需要了解的瀏覽器知識(二)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論