 傳DeepSeek自研芯片,廠商們要把AI成本打下來
傳DeepSeek自研芯片,廠商們要把AI成本打下來
電子發燒友網報道(文/黃晶晶)日前業界消息稱,DeepSeek正廣泛招募芯片設計人才,加速自研芯片布局,其芯片應用于端側或云側尚不明朗。不少科技巨頭已有自研芯片的動作,一方面是自研芯片能夠節省外購芯片的成本,掌握供應鏈主動權,另一方面隨著AI推理應用的爆發,AI推理芯片有機會被重新定義。
DeepSeek不完全依賴英偉達
去年12月底發布的DeepSeek-V3模型,整個訓練使用2048塊英偉達H800 GPU。H800是英偉達特供中國顯卡,相較于它的旗艦芯片H100降低了部分性能。也就是說DeepSeek-V3模型的訓練并不需要追求使用最尖端的GPU。
DeepSeek在訓練過程中采用了多種方法來優化硬件利用效率。例如,通過繞過CUDA編程框架,直接使用英偉達的中間指令集框架Parallel Thread Execution (PTX),DeepSeek能夠更高效地利用硬件資源,提供更細粒度的操作控制,從而避免由于CUDA的通用性導致的訓練靈活性損失。這種做法使得DeepSeek能夠在五天內完成其他模型需要十天才能完成的訓練任務,極大地提高了訓練效率。
DeepSeek的V3和R1大模型得到了不少芯片廠商的適配。如1月25日AMD宣布將DeepSeek-V3模型集成到其Instinct MI300X GPU上。而適配DeepSeek-R1大模型的廠商包括英偉達、英特爾以及國內廠商昇騰、龍芯、摩爾線程、海光信息等等。而采用這些芯片所獲得的DeepSeek-R1模型推理性能不亞于英偉達GPU的效果。
DeepSeek有著對架構更深層次的理解,如若自研芯片,發揮其軟硬件結合的能力,那么研發更具性價比的訓練或推理芯片,進一步降低成本,或許將在更大程度上促進端側AI的應用爆發,以及帶動AI芯片的多樣性發展。
OpenAI 3nm 推理芯片
去年,OpenAI進行硬件戰略調整,旨在優化計算資源和降低成本。OpenAI將引入AMD的MI300系列芯片,并繼續使用英偉達的GPU。而其自研芯片也提上日程。去年10月,OpenAI與芯片制造商博通合作開發首款專注于推理的人工智能芯片。雙方還在與臺積電進行磋商,以推進這一項目。
據外媒最新報道OpenAI 將在未來幾個月內完成其首款內部芯片的設計,并計劃將其送往臺積電制造,臺積電將使用 3nm 技術制造 OpenAI 芯片,該芯片有望在 2025 年底進行測試以及在 2026 年開始大規模生產,預計該芯片將具有“高帶寬內存”和“廣泛的網絡功能”。
根據機構測算,到2028年人工智能的推理負載占比有望達到85%,考慮到云端和邊緣側巨大的推理需求,未來推理芯片的預期市場規模將是訓練芯片的4~6倍。OpenAI自研推理芯片正好趕上這波人工智能推理應用的全面爆發。
亞馬遜3nm制程Trainium3芯片
實際上,為了擺脫對英偉達GPU的依賴,亞馬遜、微軟和 Meta 等科技巨頭也開始自研芯片。
去年12月,亞馬遜 AWS 宣布,基于其內部團隊所開發 AI 訓練芯片 Trainium2 的 Trn2 實例廣泛可用,并推出了 Trn2 UltraServer 大型 AI 訓練系統,同時還發布了下代更先進的 3nm 制程 Trainium3 芯片。
單個 Trn2 實例包含 16 顆 Trainium2 芯片,各芯片間采用超高速高帶寬低延遲 NeuronLink 互聯,可提供 20.8 petaflops 的峰值算力,適合數 B 參數大小模型的訓練和部署。
而亞馬遜 AWS下代 Trainium3 AI 訓練芯片,是 AWS 首款采用 3nm 制程的芯片產品。亞馬遜表示基于 Trainium3 的 UltraServer 性能可達 Trn2 UltraServer 的 4 倍,首批基于 Trainium3 的實例預計將于2025年底推出。
LPU語言處理單元
在AI推理大潮下,Groq公司開發的語言處理單元(Language Processing Unit,即LPU),以其獨特的架構,帶來了極高的推理性能的表現。
Groq的芯片采用14nm制程,搭載了230MB SRAM以保證內存帶寬,片上內存帶寬達80TB/s。在算力方面,該芯片的整型(8位)運算速度為750TOPs,浮點(16位)運算速度為188TFLOPs。
在Llama 2-70B推理任務中,LPU系統實現每秒近300 token的吞吐量,相較英偉達H100實現10倍性能提升,單位推理成本降低達80%。在Llama 3.1-8B推理任務中,LPU系統實現每秒736 token的吞吐量。
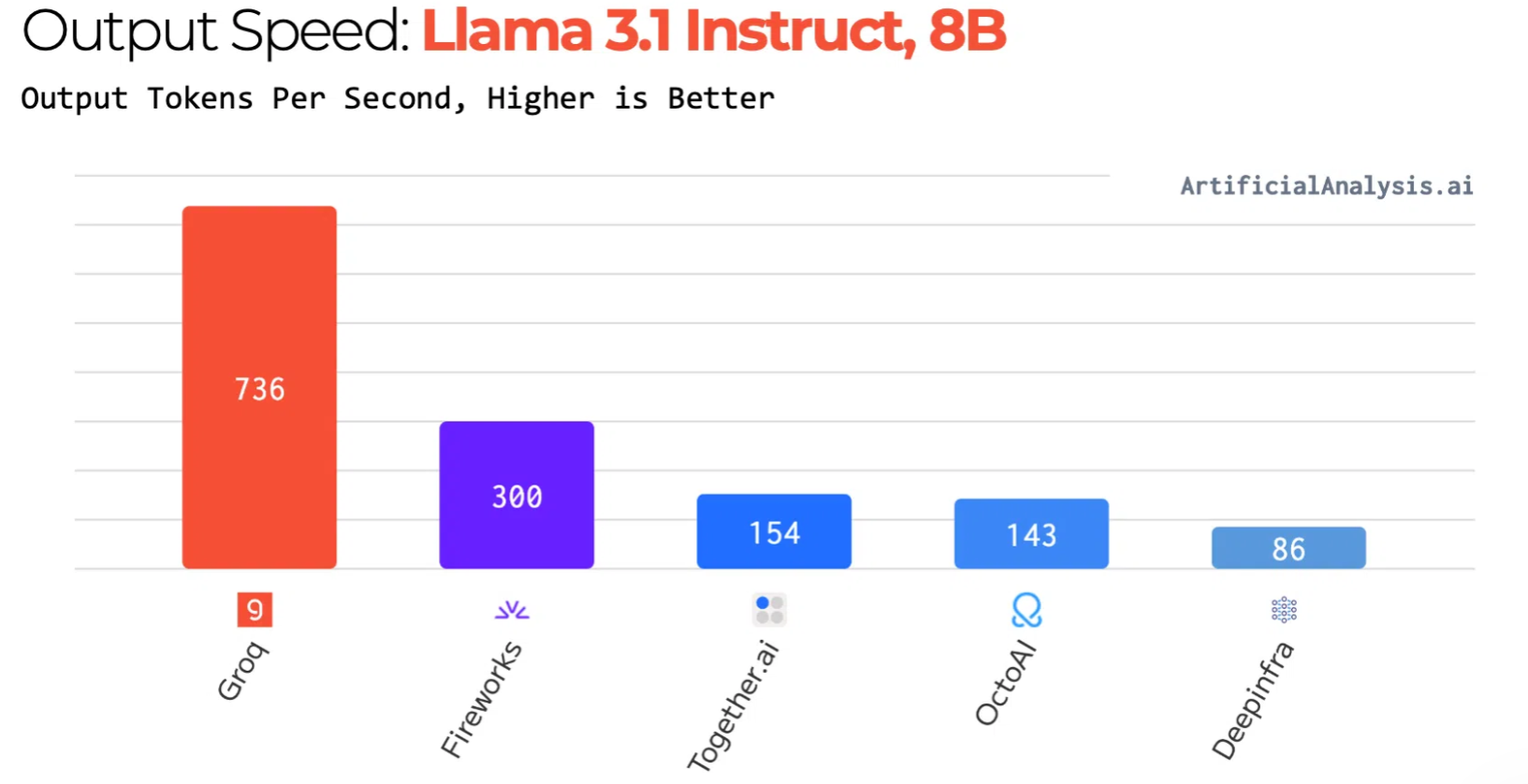
圖源:Groq官網
公開信息顯示,LPU的運作方式與GPU不同,它使用時序指令集計算機(Temporal Instruction Set Computer)架構,與GPU使用的SIMD(單指令,多數據)不同。這種設計可以讓芯片不必像GPU那樣頻繁地從HBM內存重載數據。并避免了HBM短缺的問題,從而降低成本。
在能效方面,LPU 通過減少多線程管理的開銷和避免核心資源的未充分利用,實現了更高的每瓦特計算性能,在執行推理任務時,從外部內存讀取的數據更少,消耗的電量也低于英偉達的GPU。
LPU的推出為AI推理芯片帶來了新的思路,但不得不說的是,Groq LPU芯片的成本相對較高,主要是購卡成本和運營成本。若以大模型運行吞吐量來計算,同等數據條件下,Groq LPU的硬件成本價格不菲。盡管這一芯片的性能表現突出,但對于成本優化還需要做出很多努力。希望隨著硬件技術、生產制造以及規模效應的逐步成熟,其應用成本有望得到改善。
DeepSeek的出現,以低成本特性降低了企業準入門檻,使更多企業能夠開展 AI 項目,推理端需求大幅增長。但這還不夠,要使AI訓練或推理成本進一步下探,不再局限于采用某一家的GPU,而是SoC、ASIC、FPGA等芯片都有機會,一些新的技術架構、不依賴先進工藝的芯片等有更多發展的空間,從而推動AI芯片的多元化發展。
-
DeepSeek
+關注
關注
1文章
783瀏覽量
1439
發布評論請先 登錄
Deepseek海思SD3403邊緣計算AI產品系統
科通技術推出DeepSeek+AI芯片全場景方案
HarmonyOS NEXT開發實戰:DevEco Studio中DeepSeek的使用
今日看點丨小鵬自研芯片或5月上車;安森美將在重組期間裁員2400人
DeepSeek、晶振在AI終端中的相關應用
研華發布昇騰AI Box及Deepseek R1模型部署流程
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
研華邊緣AI Box MIC-ATL3S部署Deepseek R1模型

研華WISE-AI Agent借助DeepSeek引領企業級AI全新范式

deepseek國產芯片加速 DeepSeek的國產AI芯片天團






 工商網監
工商網監
評論