 TECS OpenStack資源池虛機寫磁盤時延高告警的問題處理
TECS OpenStack資源池虛機寫磁盤時延高告警的問題處理

故障現象
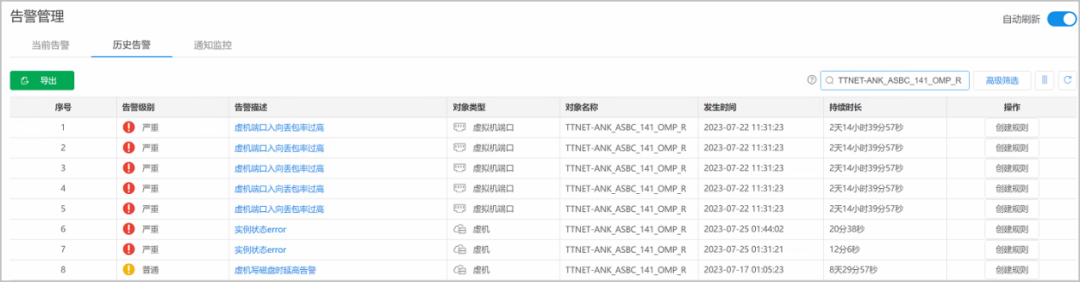
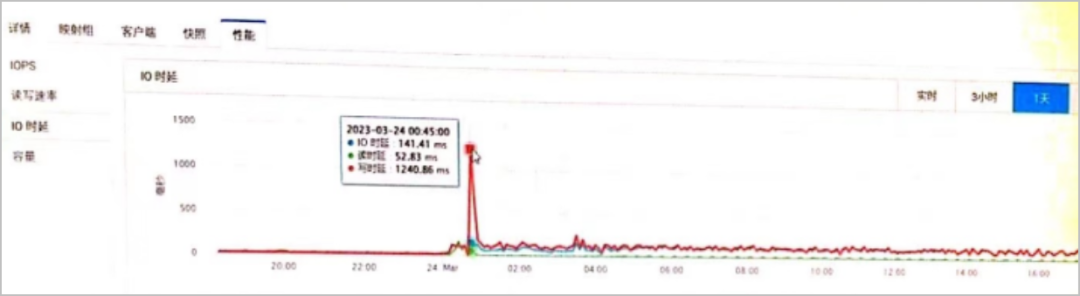
某運營商TECS資源池,在當前告警中顯示“虛機寫磁盤時延高告警”,如下圖所示。告警統計總體平均10分鐘左右自動恢復。
故障分析
結合現場環境和資源情況,分析問題產生的可能原因如下:
1. 虛擬機系統異常,操作系統只讀不可寫。
2. 計算節點訪問后端存儲異常。
3. 虛擬機讀寫性能不足,或者平臺QoS配置限定。
4. 虛擬機配置問題,或者虛機被攻擊,導致大量寫操作。
具體問題分析過程如下:
1. 登錄異常虛擬機操作系統,檢查虛擬機內部業務是否正常讀寫,以及操作系統狀態。
2. 虛機寫磁盤延時告警上報后,底層平臺和業務網元雙向檢查。
平臺檢查虛機運行正常,無其它異常告警。
業務網元檢查虛機正常,網元無異常告警。
確認虛機寫磁盤時延高告警僅觸發告警,無業務影響,如下圖所示。
3. 在TECS上通過告警找到對應虛機的節點,確定該節點只有一個虛機是NFV-P-***。再檢查虛機讀寫速率和虛機所在節點讀寫速率。
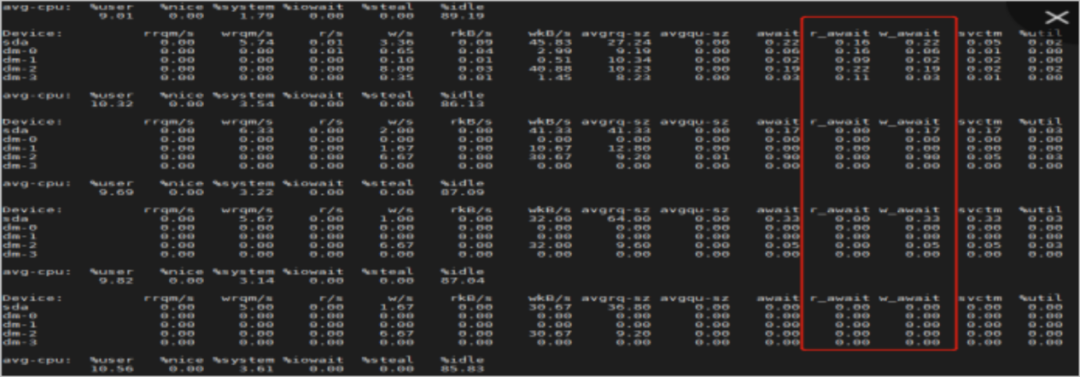
4. 執行iostat -x 3命令,檢查服務器節點。持續續觀察1小時,節點檢查正常,如下圖所示。
5. 在CloveStorage分布式存儲上使用告警信息中虛機名稱檢查,確認虛機對應卷。
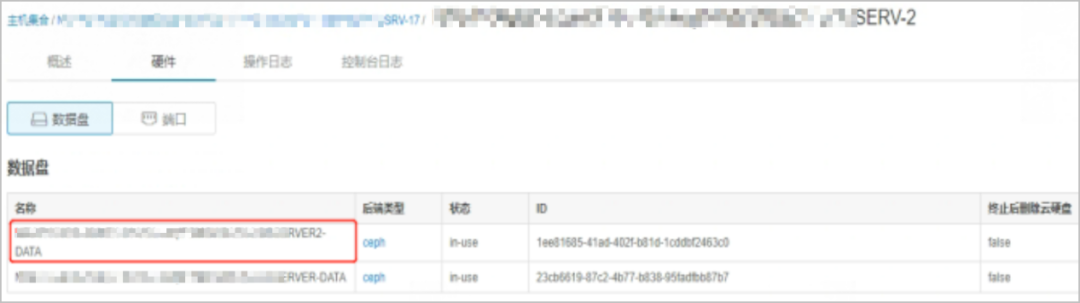
a. 在TECS平臺檢查虛機對應的云盤,獲取云盤對應卷的ID,從告警確定虛機名,如下圖所示。
b. 測試TECS平臺使用sftp方式訪問第三方存儲正常,能夠正常訪問,也能正常發送問題。
c. 在CloveStorage分布式存儲上檢查每個對應卷和集群的性能,如下圖所示。
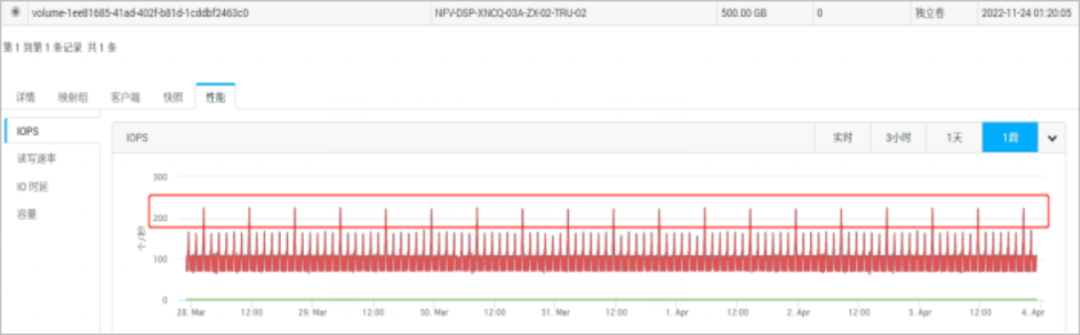
IOPS:I/O per second,即每秒鐘可以處理的I/O個數,用來衡量存儲系統的I/O處理能力,如下圖所示。
讀寫速率:每秒鐘可以處理的數據量,常以MB/s或GB/s為單位,用于衡量存儲系統的吞吐量。
I/O:輸入(input)、輸出(output)。
IO時延:發起一次I/O請求到I/O處理完成的時間間隔。
容量:可用的存儲空間大小。
6. 根據上圖可以看出IOPS值在告警時間段超出200。
7. 在TECS平臺檢查存儲QoS設置值,為200,如下圖所示。
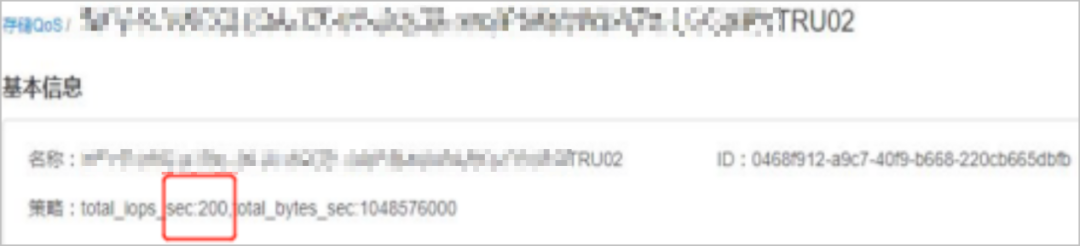
8. 檢查對應卷的IOPS值,超過 200;而卷的QoS設置IOPS最大上限為200,經確認出現時延沖高的卷QoS均超過了設定的最大值,因此存在QoS設置不合理影響卷性能的問題。
9. 同時和業務網元確認,存在卷的QoS設置小于實際運行的預期值。
10. QoS(Quality of Service)即服務質量。在有限的資源下,QoS為各種業務分配固定的資源預留,為業務提供端到端的服務質量保證。
卷的QoS設置IOPS和帶寬上限,當卷的實際性能超過QoS設置的最大值時,會由于QoS的限制出現IO隊列排隊擁塞的情況,反映到上層,即對應的云盤IO時延增高并上報告警。
11. 通過以上檢查,發現存儲側在異常時間段沒有異常告警,確認底層存儲集群運行正常。
故障處理
1. 虛擬化平臺和業務網元聯合檢查確認是因為業務網元側針對QoS設置IOPS值小于卷實際運行的IOPS值,導致卷時延沖高,最終產生告警。
2. 修改存儲QoS值后,未再上報該告警。
-
運營商
+關注
關注
4文章
2419瀏覽量
45256 -
磁盤
+關注
關注
1文章
390瀏覽量
25796 -
命令
+關注
關注
5文章
737瀏覽量
22830 -
OpenStack
+關注
關注
1文章
72瀏覽量
19319
原文標題:TECS OpenStack-資源池虛機寫磁盤時延高告警的問題處理
文章出處:【微信號:ztedoc,微信公眾號:中興文檔】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
RCS融合通信系統設計方案解析
OpenStack資源調度和現狀分析
杉巖數據已實現了與OpenStack的全面緊耦合
OpenStack云平臺監控數據采集及處理的實踐與優化

TECS資源池上報存儲設備離線的問題處理
TECS資源池SSH控制節點虛機提示connection refused的問題處理
TECS資源池上報BFD會話DOWN和網絡流量異常告警的問題處理
資源池后端存儲服務狀態異常的問題處理
高并發內存池項目實現
TECS OpenStack資源池虛機殘留導致網元異常的問題處理
TECS OpenStack資源池時間同步失敗的故障分析


TECS OpenStack資源池虛擬機網絡二層地址無法互通的問題處理





 工商網監
工商網監
評論