 群暉發布AI模型全流程存儲解決方案,破局訓練效率與數據孤島難題
群暉發布AI模型全流程存儲解決方案,破局訓練效率與數據孤島難題

兼容數據歸集、高速訓練、高可用部署全場景,支持Llama2等千億參數模型,讀寫效率提升90%
上海2025年6月24日/美通社/ -- 當算力狂奔時,數據存儲正成為AI進化的新瓶頸。
據IDC預測:從2023年每秒產生4.2PB數據,到2028年將激增至12.5PB——AI大模型掀起的數據海嘯已席卷而來。企業爭相投入千億參數模型訓練,卻在數據存儲環節頻頻"觸礁":分散的原始素材難以歸集、GPU集群因存儲延遲空轉、模型部署面臨單點故障風險...傳統存儲方案在AI洪流中正暴露出致命短板。
痛點一:數據孤島吞噬效率
訓練素材散落于各地工作站,圖像、視頻、音頻等非結構化數據如同碎片。傳統方案依賴人工搬運,耗時易錯;即便采用分布式存儲,跨地域同步效率仍受制于協議兼容性。某芯片企業就曾因數據收集延遲,導致GPU集群30%時間處于閑置狀態。
痛點二:存儲性能扼殺算力
當千張GPU卡同時讀取百萬小文件時,存儲延遲直接拖垮訓練效率。行業常見方案中,全閃存陣列雖提速明顯,但擴展性與成本難以平衡;而普通機械盤陣列的IOPS瓶頸更讓AI訓練寸步難行。
痛點三:部署環節暗藏風險
訓練完成的百GB級模型文件,若存儲系統缺乏高可用設計,一次硬件故障即可導致服務中斷。某金融機構曾因存儲節點宕機,線上AI客服停擺6小時損失千萬。
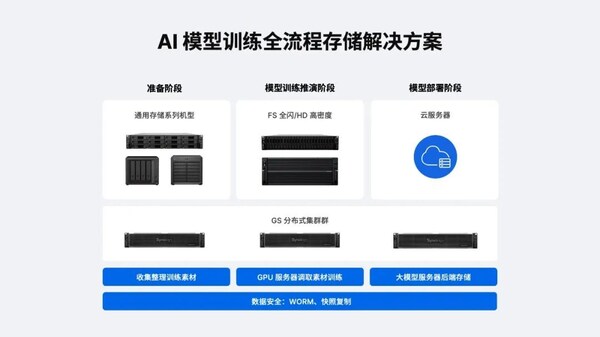
群暉AI存儲方案,破解大模型訓練的"數據困局"
群暉推出AI大模型訓練三級存儲解決方案,直擊行業痛點
/下載群暉AI模型存儲方案關注群暉官微/
1)準備階段:終結數據孤島
通用存儲機型(RS系列)抓取邊緣設備數據,實現集中化存儲和管理
支持SMB/NFS/iSCSI多協議,無縫對接工作站
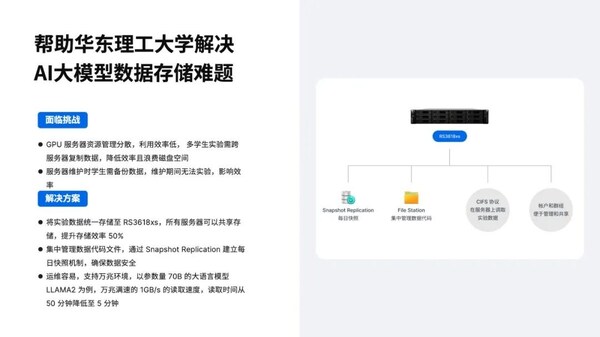
華東理工大學案例:數據歸集效率提升50%,釋放30%磁盤空間
/下載群暉AI模型存儲方案關注群暉官微/
2)訓練階段:釋放算力潛能
FS全閃系列(如FS6400)提供240,000 IOPS 4K隨機寫入
HD高密度系列(如HD6500)實現單機柜PB級存儲
對比測試:Llama2 70B模型讀取時間從50分鐘壓縮至5分鐘
3)部署階段:護航持續服務
GS分布式集群實現秒級故障切換,節點宕機服務零中斷
不可變快照+WORM機制防勒索攻擊
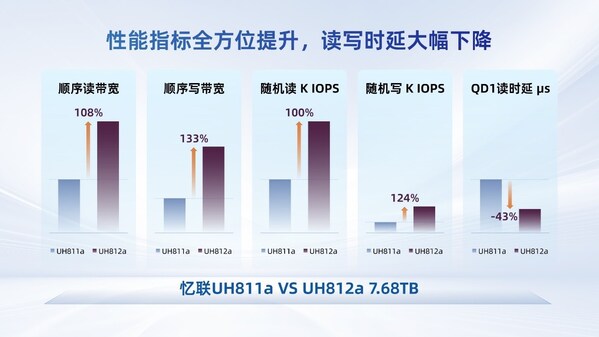
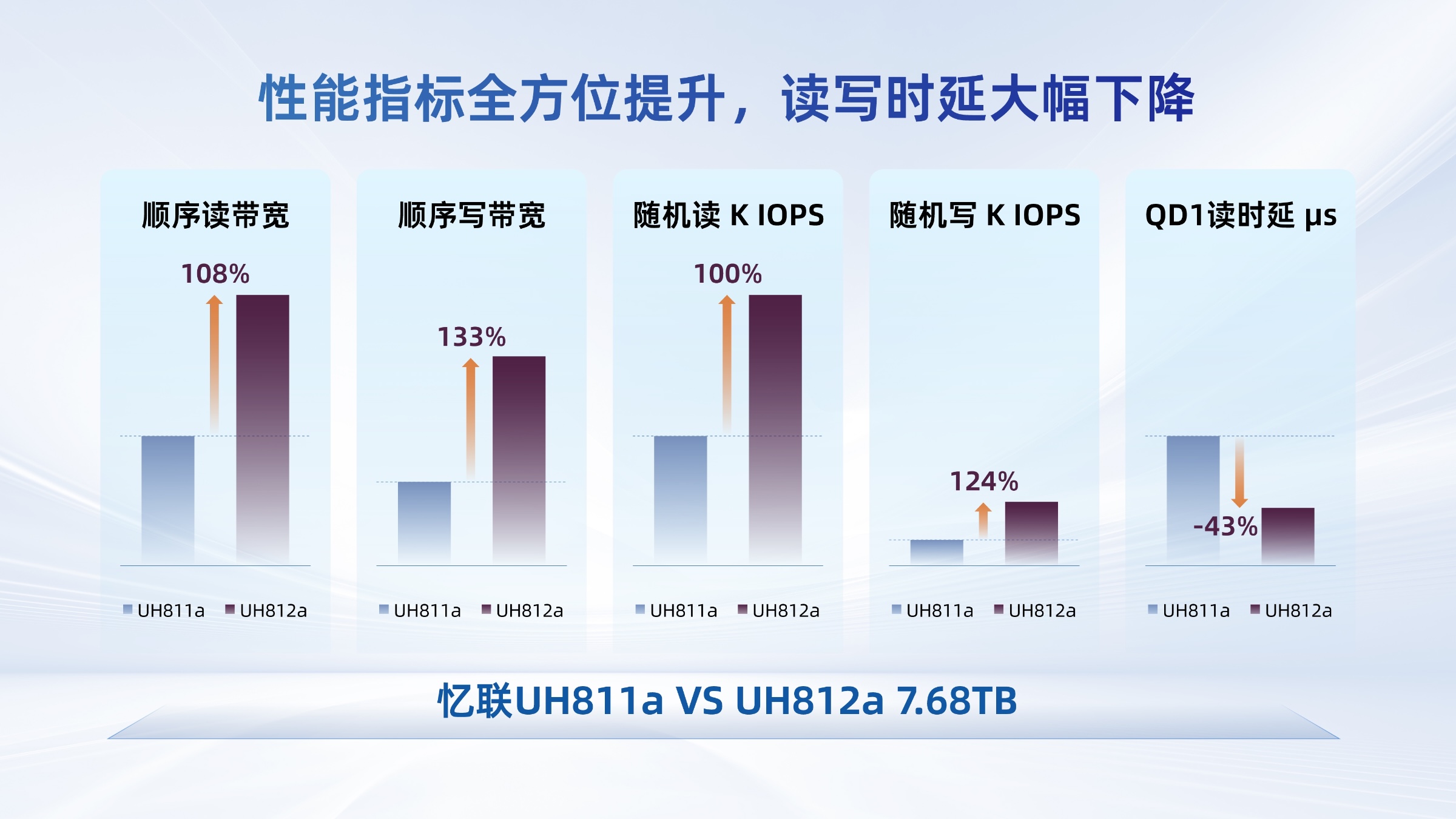
某芯片企業采用后,模型版本切換效率提升3倍!其在本地部署AI大模型的訓練階段,采用群暉全閃存存儲FS6400,用于存儲不斷更新的大模型版本與訓練數據,并通過中轉站傳輸至推理階段,支持模型快速切換與部署。FS6400能提供高達503,341/200,613的高速隨機讀寫IOPS(NFS),666,419/215,353的隨機讀寫IOPS(iSCSI)充分滿足AI模型訓練與實際應用階段對高性能存儲的嚴苛要求。
依托群暉超過20年自主研發的DSM專業存儲操作系統,FS6400具備RAID硬盤冗余、快照、版本控制等多項數據保護功能,并支持整機增量備份,集高性能、高可靠性與高性價比于一體,為企業級AI應用提供堅實的數據支撐。
安全多維度保險,滿足企業合規要求
群暉內置多維度的企業級安全防護,滿足合規要求:Secure SignIn智能認證防范入侵,Snapshot Replication快照復制實時復制確保數據可回溯,加密存儲空間滿足等保要求。

/下載群暉AI模型存儲方案關注群暉官微/
當AI競賽進入深水區,存儲不再只是"倉庫",而是決定訓練效率的核心引擎。群暉用三級存儲架構打通數據動脈,讓每張GPU卡都能全速運轉——畢竟在萬億參數時代,快1秒的模型迭代,可能意味著改寫行業格局的鑰匙。
數據革命已至,您的AI大模型存儲準備好接招了嗎?
超半數百強企業信賴群暉
審核編輯 黃宇
-
存儲
+關注
關注
13文章
4527瀏覽量
87346 -
AI
+關注
關注
88文章
34936瀏覽量
278341
發布評論請先 登錄
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
閃存破局“內存焦慮”,AI微調訓練增加閃存消耗

憶聯PCIe5.0 SSD以軟硬協同的高可靠性,支撐大模型全流程訓練
舊電腦搭建私有云群暉,怎么用群暉搭建舊電腦私有云

GPU是如何訓練AI大模型的
群暉PB級高密度存儲,滿足海量數據存儲、備份與存檔






 工商網監
工商網監
評論