") 高性能緩存設(shè)計(jì):如何解決緩存?zhèn)喂蚕韱栴}
高性能緩存設(shè)計(jì):如何解決緩存?zhèn)喂蚕韱栴}

在多核高并發(fā)場(chǎng)景下,緩存?zhèn)喂蚕恚‵alse Sharing) 是導(dǎo)致性能驟降的“隱形殺手”。當(dāng)不同線程頻繁修改同一緩存行(Cache Line)中的獨(dú)立變量時(shí),CPU緩存一致性協(xié)議會(huì)強(qiáng)制同步整個(gè)緩存行,引發(fā)無效化風(fēng)暴,使看似無關(guān)的變量操作拖慢整體效率。本文從緩存結(jié)構(gòu)原理出發(fā),通過實(shí)驗(yàn)代碼復(fù)現(xiàn)偽共享問題(耗時(shí)從3709ms優(yōu)化至473ms),解析其底層機(jī)制;同時(shí)深入剖析高性能緩存庫 Caffeine 如何通過 內(nèi)存填充技術(shù)(120字節(jié)占位變量)隔離關(guān)鍵字段,以及 JDK 1.8 的 @Contended 注解如何以“空間換時(shí)間”策略高效解決偽共享問題,揭示緩存一致性優(yōu)化的核心思想與實(shí)踐價(jià)值,為開發(fā)者提供性能調(diào)優(yōu)的關(guān)鍵思路。
偽共享
偽共享(False sharing)是一種會(huì)導(dǎo)致性能下降的使用模式,最常見于現(xiàn)代多處理器CPU緩存中。當(dāng)不同線程頻繁修改同一緩存行(Cache Line)中不同變量時(shí),由于CPU緩存一致性協(xié)議(如MESI)會(huì)強(qiáng)制同步整個(gè)緩存行,導(dǎo)致線程間無實(shí)際數(shù)據(jù)競(jìng)爭(zhēng)的邏輯變量被迫觸發(fā)緩存行無效化(Invalidation),引發(fā)頻繁的內(nèi)存訪問和性能下降。盡管這些變量在代碼層面彼此獨(dú)立,但因物理內(nèi)存布局相鄰,共享同一緩存行,造成“虛假競(jìng)爭(zhēng)”,需通過內(nèi)存填充或字段隔離使其獨(dú)占緩存行解決。
接下來我們討論并驗(yàn)證在 CPU 緩存中是如何發(fā)生偽共享問題的,首先我們需要先介紹一下 CPU 的緩存結(jié)構(gòu),如下圖所示:
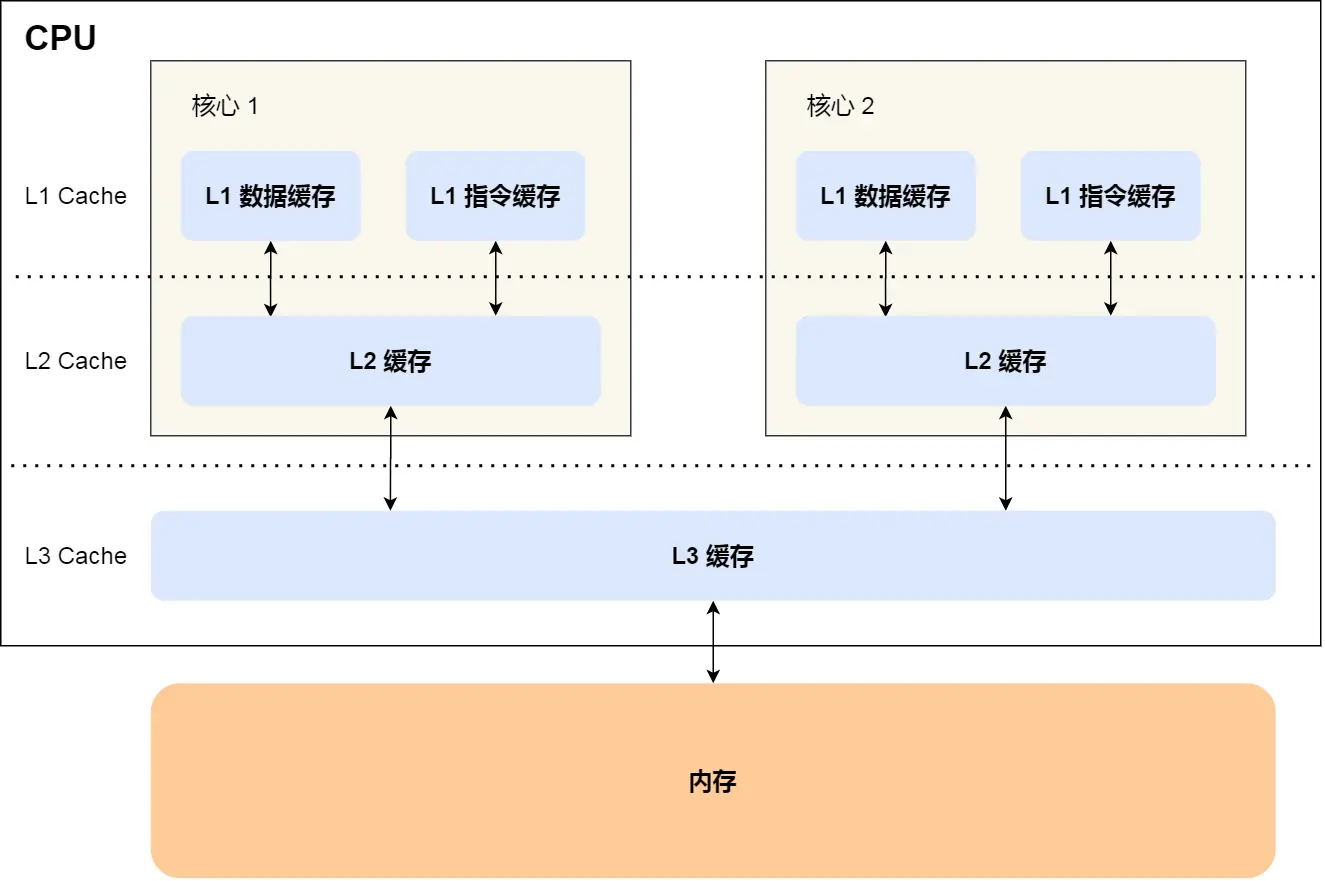
CPU Cache 通常分為大小不等的三級(jí)緩存,分別為 L1 Cache、L2 Cache、L3 Cache,越靠近 CPU 的緩存,速度越快,容量也越小。CPU Cache 實(shí)際上由很多個(gè)緩存行 Cache Line 組成,通常它的大小為 64 字節(jié)(或 128 字節(jié)),是 CPU 從內(nèi)存中 讀取數(shù)據(jù)的基本單位,如果訪問一個(gè) long[] 數(shù)組,當(dāng)其中一個(gè)值被加載到緩存中時(shí),它會(huì)額外加載另外 7 個(gè)元素到緩存中。那么我們考慮這樣一種情況,CPU 的兩個(gè)核心分別訪問和修改統(tǒng)一緩存行中的數(shù)據(jù),如下圖所示:
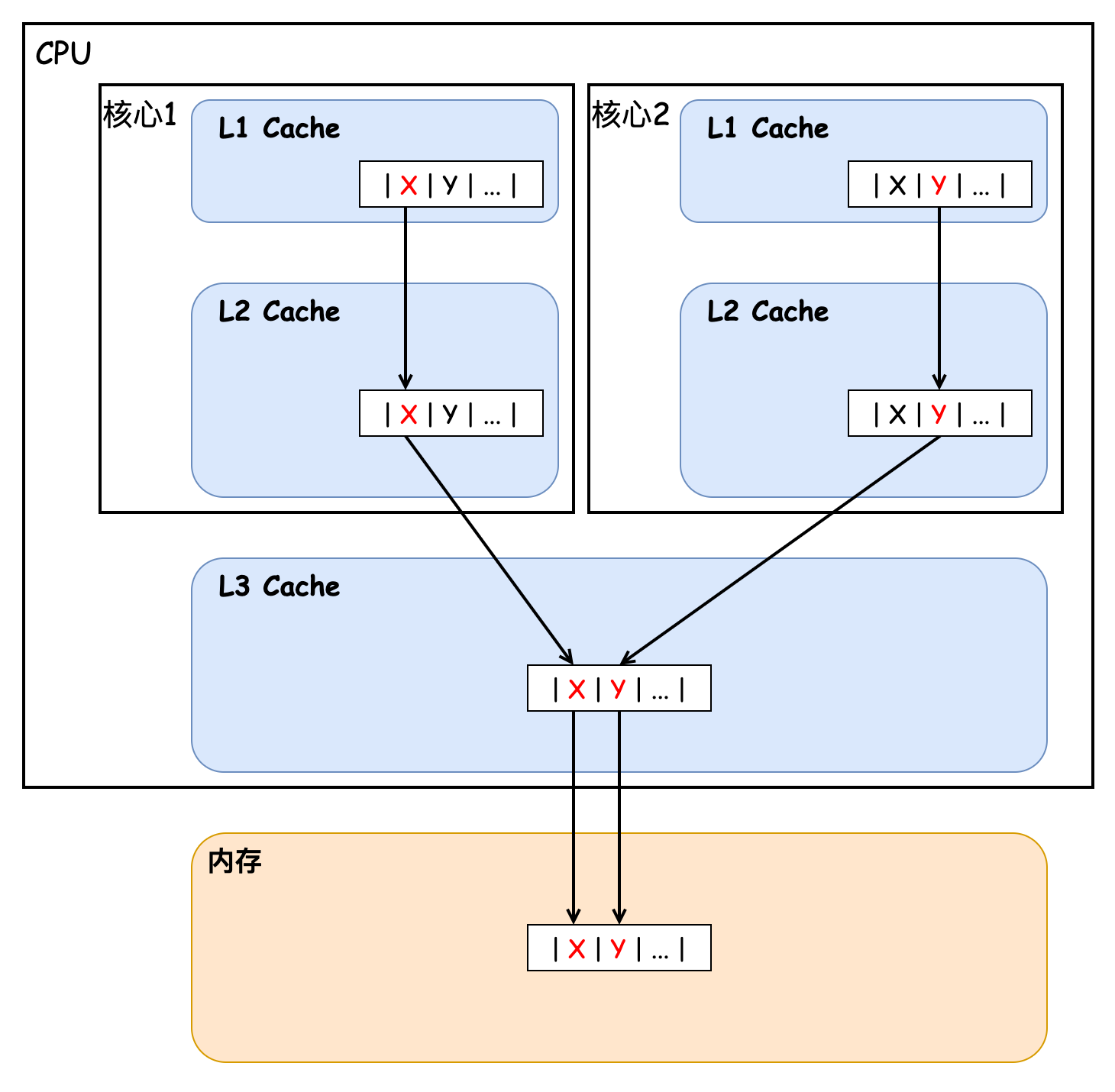
核心 1 不斷地訪問和更新值 X,核心 2 則不斷地訪問和更新值 Y,事實(shí)上每當(dāng)有核心對(duì)某一緩存行中的數(shù)據(jù)進(jìn)行修改時(shí),都會(huì)導(dǎo)致其他核心的緩存行失效,從而導(dǎo)致其他核心需要重新加載緩存行數(shù)據(jù),進(jìn)而導(dǎo)致性能下降,這也就是我們上文中所說的緩存?zhèn)喂蚕韱栴}。接下來我們用一段代碼來驗(yàn)證下緩存?zhèn)喂蚕韱栴}造成的性能損失,如下所示:
public class TestFalseSharing {
static class Pointer {
// 兩個(gè) volatile 變量,保證可見性
volatile long x;
volatile long y;
@Override
public String toString() {
return "x=" + x + ", y=" + y;
}
}
@Test
public void testFalseSharing() throws InterruptedException {
Pointer pointer = new Pointer();
// 啟動(dòng)兩個(gè)線程,分別對(duì) x 和 y 進(jìn)行自增 1億 次的操作
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100_000_000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -?> {
for (int i = 0; i < 100_000_000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}
}
這種情況下會(huì)發(fā)生緩存的偽共享,x 和 y 被加載到同一緩存行中,當(dāng)其中一個(gè)值被修改時(shí),會(huì)使另一個(gè)核心中的該緩存行失效并重新加載,代碼執(zhí)行實(shí)際耗時(shí)為 3709ms。如果我們將 x 變量后再添加上 7 個(gè) long 型的元素,使得變量 x 和變量 y 分配到不同的緩存行中,那么理論上性能將得到提升,我們實(shí)驗(yàn)一下:
public class TestFalseSharing {
static class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
@Override
public String toString() {
return "x=" + x + ", y=" + y;
}
}
@Test
public void testFalseSharing() throws InterruptedException {
// ...
}
}
本次任務(wù)執(zhí)行耗時(shí)為 473ms,性能得到了極大的提升。現(xiàn)在我們已經(jīng)清楚的了解了緩存?zhèn)喂蚕韱栴},接下來我們討論下在 Caffeine 中是如何解決緩存?zhèn)喂蚕韱栴}的。
Caffeine 對(duì)緩存?zhèn)喂蚕韱栴}的解決方案
在 緩存之美:萬文詳解 Caffeine 實(shí)現(xiàn)原理 中我們提到過,負(fù)責(zé)記錄寫后任務(wù)的 WriterBuffer 數(shù)據(jù)結(jié)構(gòu)的類繼承關(guān)系如下所示:
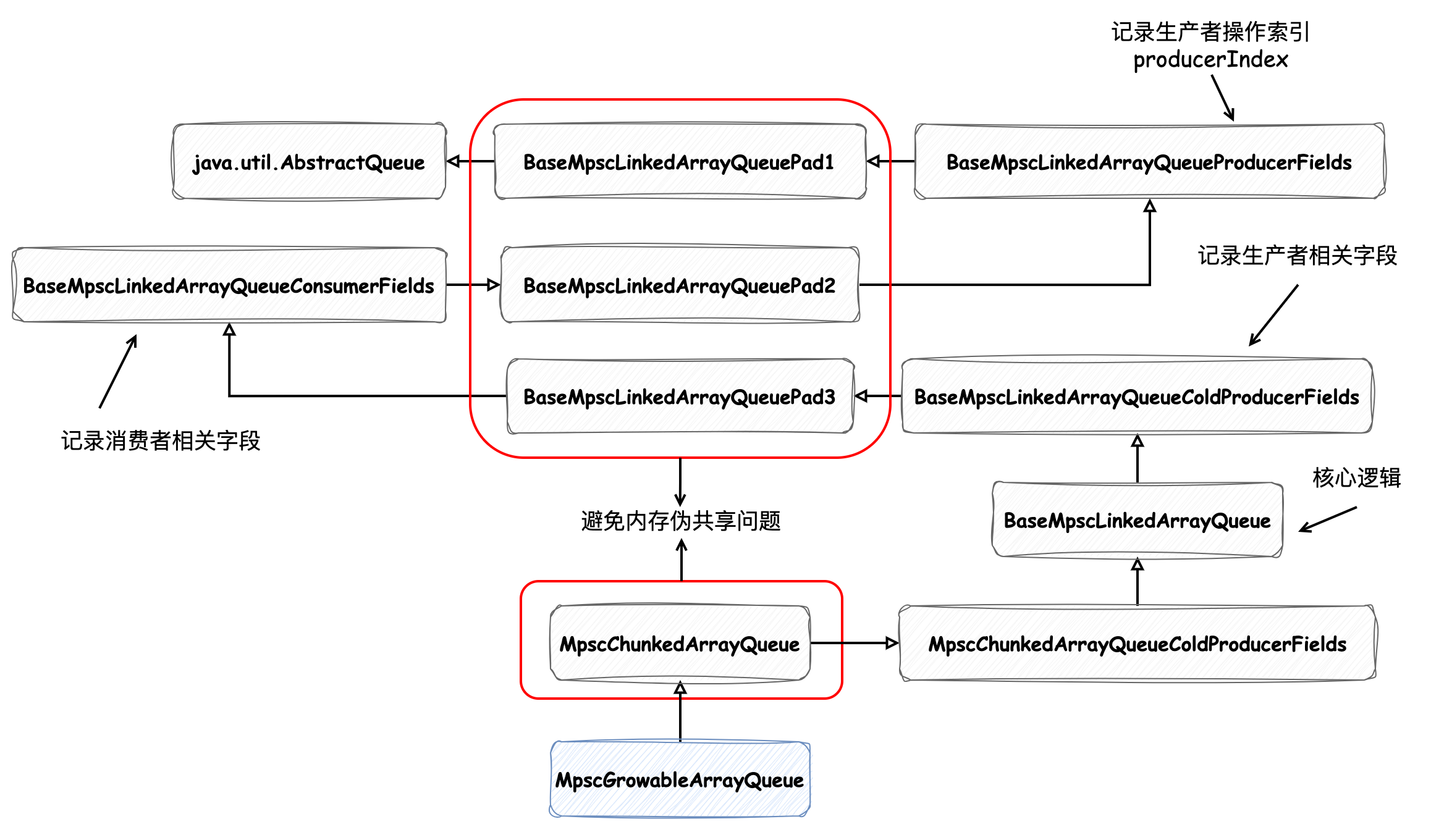
如圖中標(biāo)紅的類所示,它們都是用來解決偽共享問題的,我們以 BaseMpscLinkedArrayQueuePad1 為例來看下它的實(shí)現(xiàn):
abstract class BaseMpscLinkedArrayQueuePad1 extends AbstractQueue {
byte p000, p001, p002, p003, p004, p005, p006, p007;
byte p008, p009, p010, p011, p012, p013, p014, p015;
byte p016, p017, p018, p019, p020, p021, p022, p023;
byte p024, p025, p026, p027, p028, p029, p030, p031;
byte p032, p033, p034, p035, p036, p037, p038, p039;
byte p040, p041, p042, p043, p044, p045, p046, p047;
byte p048, p049, p050, p051, p052, p053, p054, p055;
byte p056, p057, p058, p059, p060, p061, p062, p063;
byte p064, p065, p066, p067, p068, p069, p070, p071;
byte p072, p073, p074, p075, p076, p077, p078, p079;
byte p080, p081, p082, p083, p084, p085, p086, p087;
byte p088, p089, p090, p091, p092, p093, p094, p095;
byte p096, p097, p098, p099, p100, p101, p102, p103;
byte p104, p105, p106, p107, p108, p109, p110, p111;
byte p112, p113, p114, p115, p116, p117, p118, p119;
}
abstract class BaseMpscLinkedArrayQueueProducerFields extends BaseMpscLinkedArrayQueuePad1 {
// 生產(chǎn)者操作索引(并不對(duì)應(yīng)緩沖區(qū) producerBuffer 中索引位置)
protected long producerIndex;
}
可以發(fā)現(xiàn)在這個(gè)類中定義了 120 個(gè)字節(jié)變量,這樣緩存行大小不論是 64 字節(jié)還是 128 字節(jié),都能保證字段間的隔離。如圖中所示 AbstractQueue 和 BaseMpscLinkedArrayQueueProducerFields 中的變量一定會(huì) 被分配到不同的緩存行 中。同理,借助 BaseMpscLinkedArrayQueuePad2 中的 120 個(gè)字節(jié)變量,BaseMpscLinkedArrayQueueProducerFields 和 BaseMpscLinkedArrayQueueConsumerFields 中的變量也會(huì)被分配到不同的緩存行中,這樣就避免了緩存的偽共享問題。
其實(shí)除了 Caffeine 中有解決緩存?zhèn)喂蚕韱栴}的方案外,在 JDK 1.8 中引入了 @Contended 注解,它也可以解決緩存?zhèn)喂蚕韱栴},如下所示為它在 ConcurrentHashMap 中的應(yīng)用:
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
// ...
@sun.misc.Contended
static final class CounterCell {
volatile long value;
CounterCell(long x) {
value = x;
}
}
}
其中的內(nèi)部類 CounterCell 被標(biāo)記了 @sun.misc.Contended 注解,表示該類中的字段會(huì)與其他類的字段相隔離,如果類中有多個(gè)字段,實(shí)際上該類中的變量間是不隔離的,這些字段可能被分配到同一緩存行中。因?yàn)?CounterCell 中只有一個(gè)字段,所以它會(huì)被被分配到一個(gè)緩存行中,剩余緩存行容量被空白內(nèi)存填充,本質(zhì)上也是一種以空間換時(shí)間的策略。這樣其他變量的變更就不會(huì)影響到 CounterCell 中的變量了,從而避免了緩存?zhèn)喂蚕韱栴}。
這個(gè)注解不僅能標(biāo)記在類上,還能標(biāo)記在字段上,拿我們的的代碼來舉例:
public class TestFalseSharing {
static class Pointer {
@Contended("cacheLine1")
volatile long x;
// long p1, p2, p3, p4, p5, p6, p7;
@Contended("cacheLine2")
volatile long y;
@Override
public String toString() {
return "x=" + x + ", y=" + y;
}
}
@Test
public void testFalseSharing() throws InterruptedException {
// ...
}
}
它可以指定內(nèi)容來 定義多個(gè)字段間的隔離關(guān)系。我們使用注解將這兩個(gè)字段定義在兩個(gè)不同的緩存行中,執(zhí)行結(jié)果耗時(shí)與顯示聲明字段占位耗時(shí)相差不大,為 520ms。另外需要注意的是,要想使注解 Contended 生效,需要添加 JVM 參數(shù) -XX:-RestrictContended。
再談偽共享
避免偽共享的主要方法是代碼檢查,而且偽共享可能不太容易被識(shí)別出來,因?yàn)橹挥性诰€程訪問的是不同且碰巧在主存中相鄰的全局變量時(shí)才會(huì)出現(xiàn)偽共享問題,線程的局部存儲(chǔ)或者局部變量不會(huì)是偽共享的來源。此外,解決偽共享問題的本質(zhì)是以空間換時(shí)間,所以并不適用于在大范圍內(nèi)解決該問題,否則會(huì)造成大量的內(nèi)存浪費(fèi)。
巨人的肩膀
維基百科 - 偽共享
小林coding - 2.3 如何寫出讓 CPU 跑得更快的代碼
知乎 - 雜談 什么是偽共享(false sharing)
博客園 - CPU Cache 與緩存行
博客園 - 偽共享(false sharing),并發(fā)編程無聲的性能殺手
審核編輯 黃宇
-
cpu
+關(guān)注
關(guān)注
68文章
11067瀏覽量
216677 -
緩存
+關(guān)注
關(guān)注
1文章
246瀏覽量
27122
發(fā)布評(píng)論請(qǐng)先 登錄
MCU緩存設(shè)計(jì)
Nginx緩存配置詳解
nginx中強(qiáng)緩存和協(xié)商緩存介紹
帶緩存與不帶緩存的固態(tài)硬盤有什么區(qū)別
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
緩存對(duì)大數(shù)據(jù)處理的影響分析
HTTP緩存頭的使用 本地緩存與遠(yuǎn)程緩存的區(qū)別
Web緩存的類型及功能分析
緩存技術(shù)在軟件開發(fā)中的應(yīng)用
什么是緩存(Cache)及其作用
探討移動(dòng)設(shè)備中的緩存文件管理
緩存之美——如何選擇合適的本地緩存?
TMS320C64x在高性能DSP應(yīng)用中的高速緩存使用情況






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論