") TPU深度解析 一文搞懂 TPU 谷歌專用集成電路(ASIC)
TPU深度解析 一文搞懂 TPU 谷歌專用集成電路(ASIC)

“本文轉(zhuǎn)載自 Henry Ko 的 Blog,深入地解析了 TPU 的相關(guān)知識。”
我最近一直在大量使用 TPU,很有趣地發(fā)現(xiàn)它們與 GPU 的設(shè)計理念有多么不同。
TPU 的主要優(yōu)勢在于其可擴(kuò)展性。這是通過硬件(例如,能效和模塊化)和軟件(例如,XLA 編譯器)的協(xié)同設(shè)計實現(xiàn)的。
背景
簡單來說,TPU 是谷歌的專用集成電路 (ASIC),專注于兩個因素:極高的矩陣乘法吞吐量 + 高能效。
它們的起源可以追溯到 2006 年的谷歌,當(dāng)時他們首次評估應(yīng)該采用 GPU、FPGA 還是定制 ASIC。那時只有少數(shù)應(yīng)用需要專門的硬件,他們認(rèn)為這些需求可以通過利用其大型數(shù)據(jù)中心多余的 CPU 計算能力來滿足。但情況在 2013 年發(fā)生了變化,當(dāng)時谷歌的語音搜索功能開始在神經(jīng)網(wǎng)絡(luò)上運行,內(nèi)部預(yù)測顯示,如果該功能大受歡迎,他們將需要更多的計算能力。
快進(jìn)到今天,TPU 為谷歌的大部分 AI 服務(wù)提供了動力。當(dāng)然,這包括 Gemini 或 Veo 的訓(xùn)練和推理,也包括部署他們的推薦模型 (DLRM)。
讓我們從底層向上深入了解 TPU 的內(nèi)部結(jié)構(gòu)。
TPU 單芯片層面
我的圖表將主要關(guān)注 TPUv4,但這種布局或多或少也適用于最新一代的 TPU(例如,TPUv6p "Trillium";截至 2025 年 6 月撰寫本文時,TPUv7 "Ironwood" 的細(xì)節(jié)尚未公布)。
以下是單個 TPUv4 芯片的布局:
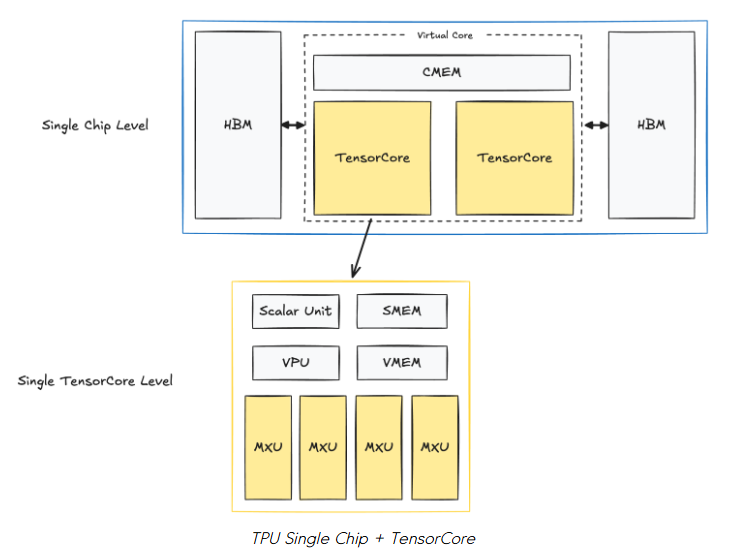
在每個芯片中,有兩個 TPU TensorCore,它們負(fù)責(zé)計算。(注意:專用于推理的 TPU 只有一個 TensorCore)。兩個 TensorCore 共享內(nèi)存單元:CMEM (128MiB) 和 HBM (32GiB)。
在每個 TensorCore 內(nèi)部,是我們的計算單元和更小的內(nèi)存緩沖區(qū):
-
矩陣乘法單元 (Matrix Multiply Unit, MXU)
-
這是 TensorCore 的關(guān)鍵組件,是一個 128x128 的脈動陣列 (systolic array)。
-
我們將在下面介紹脈動陣列。
-
向量單元 (Vector Unit, VPU)
-
用于通用的逐元素操作(例如 ReLU、逐點加/乘、規(guī)約操作)。
-
向量內(nèi)存 (Vector Memory, VMEM; 32MiB)
-
內(nèi)存緩沖區(qū)。數(shù)據(jù)在 TensorCore 進(jìn)行任何計算之前,會從 HBM 復(fù)制到 VMEM 中。
-
標(biāo)量單元 + 標(biāo)量內(nèi)存 (Scalar Unit + SMEM; 10MiB)
-
告訴 VPU 和 MXU 該做什么。
-
管理控制流、標(biāo)量操作和內(nèi)存地址生成。
如果你熟悉 NVIDIA GPU,可能會對一些初步觀察感到困惑:
-
TPU 上的片上內(nèi)存單元(CMEM、VMEM、SMEM)比 GPU 上的 L1、L2 緩存大得多。
-
TPU 上的 HBM 也比 GPU 上的 HBM 小得多。
-
負(fù)責(zé)計算的“核心”似乎要少得多。
這與 GPU 的情況正好相反,GPU 擁有較小的 L1、L2 緩存(H100 分別為 256KB 和 50MB)、更大的 HBM(H100 為 80GB)以及數(shù)以萬計的核心。
在我們進(jìn)一步討論之前,請記住 TPU 能夠像 GPU 一樣實現(xiàn)極高的吞吐量。TPU v5p 每芯片可達(dá)到 500 TFLOPs/秒,一個包含 8960 個芯片的完整 Pod 大約可以達(dá)到 4.45 ExaFLOPs/秒。據(jù)說最新的 "Ironwood" TPUv7 每個 Pod(9216 chips)最高可達(dá) 42.5 ExaFLOPS/秒。
要理解 TPU 是如何實現(xiàn)這一點的,我們需要了解它們的設(shè)計理念。
TPU 設(shè)計理念
TPU 依靠兩大支柱和一個關(guān)鍵假設(shè),實現(xiàn)了驚人的吞吐量和能效:脈動陣列 + 流水線技術(shù)、預(yù)先編譯 (Ahead-of-Time, AoT),以及假設(shè)大多數(shù)操作都可以用一種能很好地映射到脈動陣列的方式來表達(dá)。幸運的是,在我們現(xiàn)代的深度學(xué)習(xí)時代,矩陣乘法占據(jù)了計算的大部分,這非常適合脈動陣列。
TPU 設(shè)計選擇 #1: 脈動陣列 + 流水線技術(shù)
問:什么是脈動陣列 (Systolic Array)?
脈動陣列是一種硬件設(shè)計架構(gòu),由一個網(wǎng)格狀的互連處理單元 (Processing Element, PE) 組成。每個 PE 執(zhí)行一個小的計算(例如,乘法和累加),并將結(jié)果傳遞給相鄰的 PE。
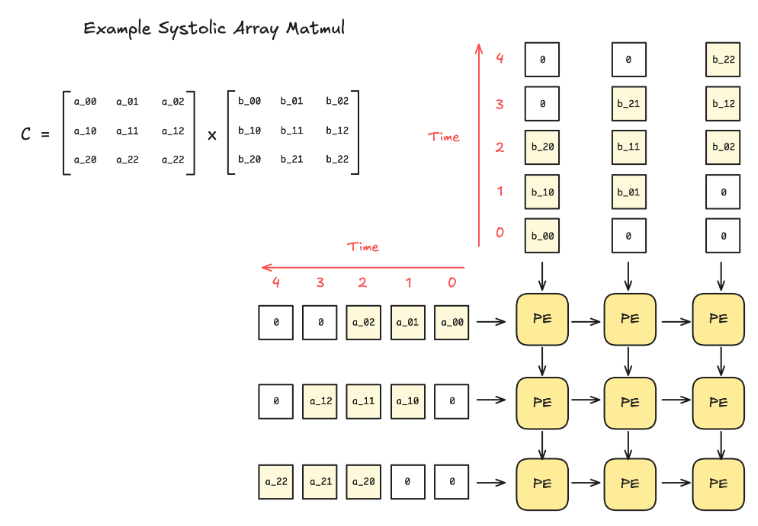
這種設(shè)計的好處在于,一旦數(shù)據(jù)被送入脈動陣列,就不再需要額外的控制邏輯來決定如何處理數(shù)據(jù)。此外,當(dāng)脈動陣列足夠大時,除了輸入和輸出,沒有其他的內(nèi)存讀/寫操作。
由于其剛性的組織結(jié)構(gòu),脈動陣列只能處理具有固定數(shù)據(jù)流模式的操作,但幸運的是,矩陣乘法和卷積完美地契合了這一范疇。
此外,通過流水線技術(shù),可以將計算與數(shù)據(jù)移動重疊起來。下面是一個在 TPU 上進(jìn)行流水線式逐點操作的圖示。
題外話:脈動陣列的缺點 - 稀疏性
你可以看到脈動陣列非常喜歡密集矩陣(即每個 PE 在幾乎每個周期都處于活動狀態(tài))。然而,其缺點在于,對于同樣大小的稀疏矩陣,性能沒有提升:即使是對于值為零的元素,PE 仍然需要執(zhí)行相同數(shù)量的周期來進(jìn)行計算。
如果深度學(xué)習(xí)社區(qū)更青睞不規(guī)則的稀疏性(例如 MoE),那么處理脈動陣列的這種系統(tǒng)性限制將變得更加重要。
TPU 設(shè)計選擇 #2: 預(yù)先編譯 (AoT) + 減少對緩存的依賴
本節(jié)回答了 TPU 如何通過TPU + XLA 編譯器的軟硬件協(xié)同設(shè)計來避免使用緩存,從而實現(xiàn)高能效。
首先,回想一下,傳統(tǒng)緩存是為了處理不可預(yù)測的內(nèi)存訪問模式而設(shè)計的。一個應(yīng)用程序的程序與另一個應(yīng)用程序的程序可能有著截然不同的內(nèi)存訪問模式。本質(zhì)上,緩存使硬件具有靈活性,能夠適應(yīng)各種應(yīng)用。這是 GPU 成為非常靈活的硬件的一大原因(注:與 TPU 相比)。
然而,緩存訪問(以及一般的內(nèi)存訪問)會消耗大量能量。下面是一個芯片上操作的能耗粗略估算(45nm, 0.9V; )。這里的關(guān)鍵信息是,內(nèi)存訪問和控制占據(jù)了我們大部分的能量,而算術(shù)運算的能耗則要低得多。

但是,如果你的應(yīng)用非常特定,其計算/內(nèi)存訪問模式高度可預(yù)測呢?
舉個極端的例子,如果我們的編譯器能夠提前計算出所有需要的內(nèi)存訪問,那么我們的硬件只需要一個便簽式內(nèi)存 (scratchpad memory) 作為緩沖區(qū)就足夠了,完全不需要緩存。
這正是 TPU 理念所追求的,也正是為什么 TPU 與 XLA 編譯器協(xié)同設(shè)計以實現(xiàn)這一目標(biāo)。XLA 編譯器通過提前分析計算圖來生成優(yōu)化的程序。
問:但是 JAX 也能很好地與 TPU 配合,可它們用的是 @jit?
JAX+XLA 在 TPU 上處于即時編譯 (JIT) 和預(yù)先編譯 (AOT) 的混合狀態(tài),因此會產(chǎn)生困惑。當(dāng)我們第一次在 JAX 中調(diào)用一個 jit 函數(shù)時,JAX 會追蹤它以創(chuàng)建一個靜態(tài)計算圖。這個圖被傳遞給 XLA 編譯器,在那里它被轉(zhuǎn)換成一個完全靜態(tài)的 TPU 二進(jìn)制文件。正是在這最后的轉(zhuǎn)換階段,會進(jìn)行 TPU 特定的優(yōu)化(例如,最小化內(nèi)存訪問)來為 TPU 定制處理過程。
但有一個注意事項:如果 jit 函數(shù)以不同的輸入形狀運行,就必須重新編譯和緩存。這就是為什么 JAX 在處理任何動態(tài)填充或依賴于輸入的不同長度的 for 循環(huán)層時表現(xiàn)不佳的原因。
當(dāng)然,這種方法聽起來很好,但也有不便的缺點。它缺乏靈活性,并且對編譯器的重度依賴是一把雙刃劍。
但為什么谷歌仍然堅持這種設(shè)計理念呢?
TPU 與能效 (TPUv4)
前面那張能耗圖并不能準(zhǔn)確代表 TPU,所以這里是 TPUv4 的能耗分解。請注意,TPUv4 是 7nm 工藝,而 45nm 的數(shù)據(jù)僅作對比 。

左邊的條形圖直觀地顯示了數(shù)值,但需要注意的一點是,現(xiàn)代芯片使用 HBM3,其能耗遠(yuǎn)低于這里顯示的 DDR3/4 DRAM。盡管如此,這表明內(nèi)存操作的能耗要高出幾個數(shù)量級。
這與現(xiàn)代規(guī)模法則 (scaling laws) 有很好的聯(lián)系:我們非常樂意增加浮點運算次數(shù) (FLOPS) 來換取內(nèi)存操作的減少。因此,減少內(nèi)存操作具有雙重的優(yōu)化效益,因為它們不僅使程序運行更快,而且能耗也更低。
TPU 多芯片層面
讓我們再一層,看看 TPU 在多芯片環(huán)境中的工作方式。
Tray 層面 (又稱 "板卡"; 4 芯片)

一個 TPU tray 包含 4 個 TPU 芯片或 8 個 TensorCore(簡稱為“核心”)。每個 tray 都有自己的 CPU 主機(jī)(注意:對于推理型 TPU,一個主機(jī)訪問 2 個tray,因為它們每個芯片只有 1 個核心)。
主機(jī)與芯片的連接是 PCIe,但芯片與芯片之間的連接是核間互連 (Inter-Core Interconnect, ICI),它具有更高的帶寬。
但 ICI 連接可以延伸到更遠(yuǎn)的多個托盤。為此,我們需要上升到機(jī)架 (Rack) 層面。
機(jī)架 (Rack) 層面 (4x4x4 芯片)
TPU 特別令人興奮的部分在于其可擴(kuò)展性,我們從機(jī)架層面開始看到這一點。
一個 TPU 機(jī)架由 64 個 TPU 組成,它們以 4x4x4 的 3D 環(huán)面 (torus) 結(jié)構(gòu)連接。如果你看過谷歌下面這樣的 TPU 宣傳材料,那就是 8 個 TPU 機(jī)架的圖像。

但在我們深入了解機(jī)架之前,需要澄清一些容易混淆的術(shù)語:機(jī)架 (rack) vs. Pod vs. Slice。
問:“TPU Rack”、“TPU Pod” 和 “TPU Slice” 之間有什么區(qū)別?
不同的谷歌資料對它們的使用略有不同,有時會將 "TPU Pods" 和 "TPU Slices" 互換使用。但在本文中,我們將遵循谷歌 TPU 論文和 GCP TPU 文檔中的定義。
-
TPU Rack (機(jī)架):
-
包含 64 個芯片的物理單元。也稱為“立方體 (cube)”。
-
-
TPU Pod:
-
可通過 ICI 和光纖連接的 TPU 的最大單元。
-
也稱為 "Superpod" 或 "Full pod"。例如,TPUv4 的一個 TPU Pod 將由 4096 個芯片或 64 個 TPU 機(jī)架組成。
-
-
TPU Slice (切片):
-
介于 4 個芯片和 Superpod 大小之間的任何 TPU 配置。
-
關(guān)鍵區(qū)別在于,TPU Rack 和 TPU Pod 是物理度量單位,而 TPU Slice 是一個抽象單位。當(dāng)然,設(shè)置 TPU Slice 有重要的物理屬性,但我們暫時將其抽象化。
現(xiàn)在,我們將使用物理度量單位:TPU Racks 和 TPU Pods。這是因為了解 TPU 系統(tǒng)是如何物理連接的,可以幫助我們更好地理解 TPU 的設(shè)計理念。
現(xiàn)在回到 TPU 機(jī)架 (針對 TPUv4):
一個 TPU 機(jī)架由 64 個芯片組成,通過 ICI 和光路交換 (Optical Circuit Switching, OCS) 連接在一起。本質(zhì)上,我們連接多個 tray 來模擬一個 64 芯片的系統(tǒng)。這種將小部件組合成超級計算機(jī)的主題在后面會繼續(xù)出現(xiàn)。
下面是單個 TPUv4 機(jī)架的圖示。它是一個 4x4x4 的 3D 環(huán)面,每個節(jié)點是一個芯片,藍(lán)色的箭頭是 ICI,而各個面上的線是 OCS。

然而,這張圖引出了幾個問題。為什么 OCS 只用于各個面?換句話說,使用 OCS 有什么好處?有 3 大好處,我們稍后會介紹另外兩個。
OCS 的好處 #1: 環(huán)繞連接 (Wraparound)
通過環(huán)繞連接實現(xiàn)節(jié)點間更快的通信。
OCS 還充當(dāng)給定 TPU 配置的環(huán)繞連接。這將兩個節(jié)點之間的最壞情況跳數(shù)從 N-1 跳減少到每個軸 (N-1)/2 跳,因為每個軸都變成了一個環(huán)(1D 環(huán)面)。
隨著我們進(jìn)一步擴(kuò)展,這種效應(yīng)變得更加重要,因為減少芯片間通信延遲對于高并行化至關(guān)重要。
題外話:并非所有 TPU 都具有 3D 環(huán)面拓?fù)?/span>
注意:較早的 TPU 代(例如 TPUv2, v3)和推理 TPU(例如 TPUv5e, TPUv6e)具有 2D 環(huán)面拓?fù)洌皇窍裣旅孢@樣的 3D 環(huán)面。然而,TPUv7 "Ironwood" 似乎是 3D 環(huán)面,盡管它被宣傳為推理芯片(注意:我只是根據(jù)他們的宣傳材料進(jìn)行假設(shè))。

完整 Pod 層面 (又稱 "Superpod"; TPUv4 為 4096 芯片)
就像我們將多個芯片連接起來組成一個 TPU 機(jī)架一樣,我們可以連接多個機(jī)架來組成一個大型的 Superpod。
Superpod 也指 TPU 可以達(dá)到的(僅使用 ICI 和 OCS)互連芯片的最大配置。接下來還有一個多 Pod 層面,但這必須通過較慢的互連,我們稍后會討論。
這個大小因代而異,但對于 TPUv4 是 4096 個芯片(即 64 個 4x4x4 芯片的機(jī)架)。對于最新的 TPUv7 "Ironwood",是 9216 個芯片。
下圖顯示了一個 TPUv4 的 Superpod。

請注意每個立方體(即一個 TPU 機(jī)架)是如何通過 OCS 相互連接的。這也允許我們在一個 Pod 中獲取 TPU 的“切片”(slices)。
帶 OCS 的 TPU 切片
我們可以在 Pod 內(nèi)請求 TPU 的子集,這些就是 TPU 切片。但即使你想要 N 個芯片,也有多種拓?fù)淇晒┻x擇。
例如,假設(shè)你總共需要 512 個芯片。你可以要求一個立方體 (cube) (8x8x8)、一個雪茄形 (cigar shape) (4x4x32) 或一個矩形 (rectangle) (4x8x16)。選擇切片的拓?fù)浔旧砭褪且粋€超參數(shù)。
你選擇的拓?fù)鋾绊懝?jié)點之間的通信帶寬。這直接影響不同并行化方法的性能。
例如,對于全局通信 (all-to-all),如數(shù)據(jù)并行或張量并行,立方體 (例如 8x8x8) 會是首選,因為它具有最高的對分帶寬 (bisection bandwidth)。然而,對于流水線并行,雪茄形 (例如 4x4x32) 會更好,因為它可以更快地與順序?qū)油ㄐ牛僭O(shè)一個層適合一個 4x4 芯片的子切片)。

當(dāng)然,最佳拓?fù)淙Q于模型,找到它本身就是一項工作。TPUv4 的論文 [9] 也對此進(jìn)行了測量,以顯示拓?fù)渥兓绾渭铀偻掏铝浚ㄗ⒁猓何也淮_定第一行指的是哪種 LLM 架構(gòu),因為它沒有具體說明)。

我們介紹了 TPU 切片,但還有一個重要特性有助于 TPU 的高運行穩(wěn)定性。
那就是由于 OCS,這些切片不必是連續(xù)的機(jī)架。這是我們前面沒有提到的使用 OCS 的第二個好處——可能也是最大的好處。
OCS 的好處 #2: (可重構(gòu)的) 非連續(xù)多節(jié)點切片
請注意,這與硬連線多個節(jié)點來模擬非連續(xù)切片是不同的。由于 OCS 是一個交換機(jī)而不是硬連線,節(jié)點之間的物理線路要少得多,因此允許更高的可擴(kuò)展性(即更大的 TPU Pod 尺寸)。
這允許大規(guī)模靈活的節(jié)點配置。例如,假設(shè)我們想在一個 Pod 上運行三個作業(yè)。雖然樸素的調(diào)度不允許這樣做,但 OCS 連接允許我們抽象出節(jié)點的位置,并將整個 Pod 僅僅看作一個 “節(jié)點袋” (bag of nodes)。

這提高了 Pod 的利用率,并且在節(jié)點發(fā)生故障時可能使維護(hù)更容易。谷歌將其描述為**“故障節(jié)點的爆炸半徑很小”。然而,我不確定當(dāng)只有某些節(jié)點必須關(guān)閉時,其液體冷卻會受到怎樣的影響。
最后,這種靈活的 OCS 還有一個有趣的擴(kuò)展:我們還可以改變 TPU 切片的拓?fù)洌鐝某R?guī)環(huán)面變?yōu)榕でh(huán)面 (twisted torus)。
OCS 的好處 #3: 扭曲的 TPU 拓?fù)?/span>
我們之前看到了如何通過改變固定芯片數(shù)量的 (x,y,z) 維度來獲得不同的 TPU 切片拓?fù)洹H欢@次我們將在固定的 (x,y,z) 維度下工作,但改變它們的連接方式以實現(xiàn)不同的拓?fù)洹?/span>
一個顯著的例子是從雪茄形的常規(guī)環(huán)面變?yōu)槿缦滤镜呐で┣循h(huán)面。
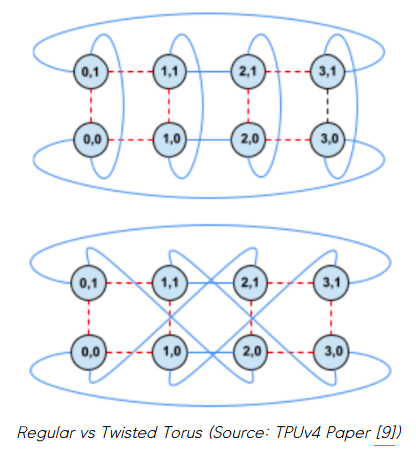
扭曲環(huán)面允許在扭曲的 2D 平面上的芯片之間進(jìn)行更快的通信。這對于加速全局通信 (all-to-all) 特別有用。
讓我們更深入地探討一下,想象一個具體的場景,這會有所幫助。
使用扭曲環(huán)面加速訓(xùn)練
理論上,扭曲環(huán)面對張量并行 (Tensor Parallel, TP) 的好處最大,因為每層都有多個 all-gather 和 reduce-scatter 操作。它可能對數(shù)據(jù)并行 (Data Parallel, DP) 帶來中等的好處,因為每個訓(xùn)練步驟也有一個 all-reduce,但這會不那么頻繁。
想象一下,我們正在訓(xùn)練一個標(biāo)準(zhǔn)的 decoder-only transformer,并且我們想采用大量的并行化來加速訓(xùn)練。我們將在下面看到兩種情況。
場景 #1: 4x4x16 拓?fù)?(TP + PP; 總共 256 芯片)
我們的 z 軸將是我們的流水線并行 (Pipeline Parallel, PP) 維度,我們的 2D TP 維度將是 4x4。本質(zhì)上,假設(shè)每個層 k 位于 z=k,并且每個層在 16 個芯片上分片。如果沒有明確繪制,則假定標(biāo)準(zhǔn)的 OCS 連接(即最近鄰)。
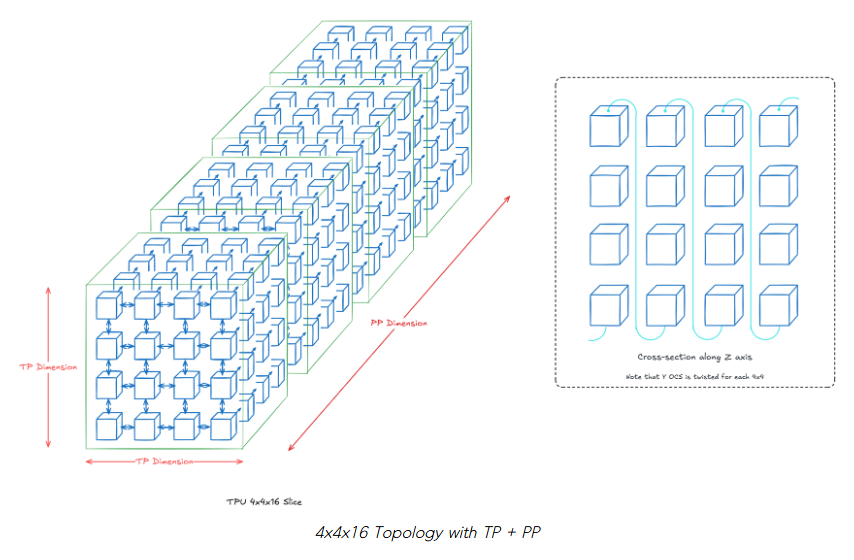
我們將在每個 z=k 處扭曲 2D 環(huán)面,這使得每個 TP 層中的芯片之間的通信更快。沿著我們的 PP 維度扭曲是不必要的,因為它們主要依賴于點對點通信。
注意: 實際上,當(dāng)芯片數(shù)量大于 4x4 時,扭曲環(huán)面才會帶來好處。我們在這里使用 4x4 僅為可視化目的。
場景 #2: 16x4x16 拓?fù)?(DP + TP + PP; 總共 1024 芯片)
作為擴(kuò)展,我們將在之前的場景中添加一個大小為 4 的 DP 維度。這意味著沿著 x 軸有 4 個場景 #1 的模型。

請注意扭曲環(huán)面如何僅限于每個 DP 模型的每個 TP 維度(即,對于給定的 k=1…16,在每個 z=k 處的一個 4x4 的 2D 平面)。DP 維度只有一個環(huán)繞連接,以便每行成為一個大小為 16 的水平環(huán)。
你可能已經(jīng)注意到,還有一種 8x8x16 的替代拓?fù)洌?2x2 DP 維度),但這變得更加復(fù)雜,因為我們混合了 DP 和 TP 維度。具體來說,不清楚我們應(yīng)該如何為 y 軸構(gòu)建 OCS 環(huán)繞連接,同時為每個 TP 維度容納扭曲環(huán)面。
多 Pod 層面 (又稱 "Multislice"; TPUv4 為 4096+ 芯片)

TPU 層次結(jié)構(gòu)的最后一層是多 Pod 層面。在這里,你可以將多個 Pod 視為一臺大型機(jī)器。然而,Pod 之間的通信是通過數(shù)據(jù)中心網(wǎng)絡(luò) (Data-Center Network, DCN)完成的,其帶寬低于 ICI。

圖示多 Pod 訓(xùn)練如何配置
PaLM 就是這樣訓(xùn)練的。它花了 56 天在 6144 個 TPUv4(2個 Pod)上進(jìn)行訓(xùn)練。下面你可以看到 6 個 Pod 上的 TPU 作業(yè)分配:綠色是 PaLM,紅色是未分配,其余是其他作業(yè)。注意,每個方塊是一個 4x4x4 的 TPU 立方體。
實現(xiàn)這一點本身就很困難,但更令人印象深刻的是對開發(fā)者體驗的關(guān)注。具體來說,是關(guān)注 “我們?nèi)绾尾拍鼙M可能地抽象化模型擴(kuò)展的系統(tǒng)/硬件部分?” 這個問題。
谷歌的答案是讓 XLA 編譯器負(fù)責(zé)協(xié)調(diào)大規(guī)模芯片間的通信。通過研究人員提供的正確標(biāo)志(即 DP、FSDP、TP 的并行維度、切片數(shù)量等),XLA 編譯器會為手頭的 TPU 拓?fù)洳迦胝_的分層集合通信操作。目標(biāo)是以盡可能少的代碼更改來實現(xiàn)大規(guī)模訓(xùn)練。
例如,這里是谷歌博客 [1] 中跨多個切片的 all-reduce 操作的分解。

這表明 XLA 編譯器負(fù)責(zé)處理切片之間和切片內(nèi)部的通信集合操作。
舉一個具體的例子,訓(xùn)練模型可能存在如下的 TPU 拓?fù)洹<せ钪低ㄐ磐ㄟ^ ICI 在切片內(nèi)發(fā)生,而梯度通信將通過 DCN 跨切片發(fā)生(即跨 DCN DP 維度)。
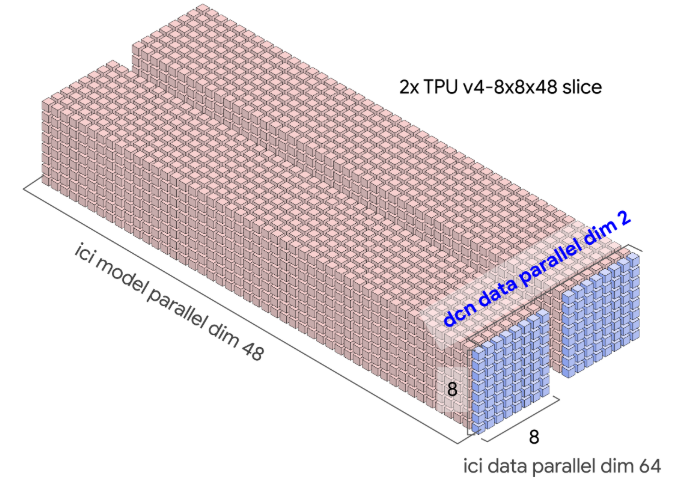
將圖表與現(xiàn)實聯(lián)系起來
當(dāng)你看到硬件的實際照片時,將圖表與現(xiàn)實聯(lián)系起來會很有幫助。下面是一個總結(jié)。
如果你看過谷歌 TPU 宣傳材料的圖片,你可能見過下面這張圖。

這是 8 個 TPU 機(jī)架,每個單元是我們上面看到的 4x4x4 的 3D 環(huán)面。一個機(jī)架中的每一行有 2 個托盤,這意味著每行有 8 個 TPU 芯片。
這是一個 TPUv4 的單托盤:

注意,圖示被簡化為只有一個 PCIe 端口,但實際托盤上有 4 個 PCIe 端口(在左側(cè))——每個 TPU 一個。
下面是一個單芯片:

中間部分是 ASIC,周圍的 4 個塊是 HBM 堆棧。我們看到的是一個 TPU v4,所以它內(nèi)部有 2 個 TensorCore,因此總共有 4 個 HBM 堆棧。
我沒找到 TPUv4 的芯片平面圖,所以這里有一個 TPUv4i 的,它很相似,只是因為它是一個推理芯片,所以只有一個 TensorCore。
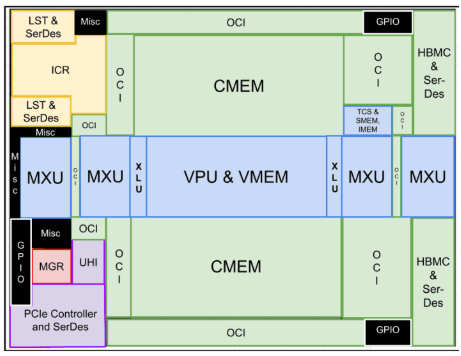
請注意 CMEM 在 TPUv4i 的布局上占了相當(dāng)大的空間。
原文轉(zhuǎn)載自:https://henryhmko.github.io/posts/tpu/tpu.html,經(jīng)過翻譯、校對。
-
FPGA
+關(guān)注
關(guān)注
1645文章
22015瀏覽量
616834 -
asic
+關(guān)注
關(guān)注
34文章
1245瀏覽量
122207 -
gpu
+關(guān)注
關(guān)注
28文章
4928瀏覽量
130967 -
TPU
+關(guān)注
關(guān)注
0文章
153瀏覽量
21145 -
KiCAD
+關(guān)注
關(guān)注
5文章
250瀏覽量
9433
發(fā)布評論請先 登錄
電機(jī)驅(qū)動與控制專用集成電路及應(yīng)用
電機(jī)控制專用集成電路PDF版
TPU處理器的特性和工作原理
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
TPU編程競賽系列|第九屆集創(chuàng)賽“算能杯”火熱報名中!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論