 智能體AI面臨非結構化數據難題:IBM推出解決方案
智能體AI面臨非結構化數據難題:IBM推出解決方案

北京2025年7月1日/美通社/ -- IBM 正在從根本上簡化面向 AI 的數據堆棧。IBM 在Think大會上預覽watsonx.data的重大演進,以幫助組織做好數據準備為AI所用,同時提供一個開放的混合數據基礎架構和企業級的結構化和非結構化數據管理。
智能體AI面臨非結構化數據難題:IBM推出解決方案
測試結果顯示,與傳統RAG相比,IBM watsonx.data的AI準確性提高了40%。IBM于6月推出的產品和功能包括:
Watsonx.data integration(集成),該軟件可在單個界面中編排不同集成樣式和格式的數據訪問和工程設計,其核心是靈活性和規模
Watsonx.data intelligence(智能),該軟件可改變組織處理、管理和利用有意義數據的方式,利用 AI 的力量簡化數據治理
在 Meta 的Llama Stack中增加 watsonx 作為 API 提供商,增強了企業大規模部署生成式 AI 的能力,并以開放性為核心
Watsonx.data 集成和 Watsonx.data 智能將作為獨立產品提供,部分功能也將通過 Watsonx.data 提供,從而最大限度地提高客戶選擇和模塊化程度。
為了補充這些產品,IBM近期宣布了收購 DataStax 的意向,DataStax 擅長將非結構化數據用于生成式AI。借助 DataStax,客戶可以訪問其他矢量搜索功能。
基于內部測試,對比使用 watsonx.data Premium Edition 檢索層與僅矢量 RAG 在三個常見用例中 AI 模型輸出答案的準確性,測試使用 IBM 專有數據集,采用相同的選定開源通用推理、評估和嵌入模型以及額外變量。測試結果可能因具體情況而異。
這一重大演進的背景
企業正面臨著實現準確且高性能的生成式AI——尤其是具有自主決策能力的智能體AI人的重大障礙,但該障礙并非如大多數企業領導者所想。
問題不在于推理成本或難以捉摸的"完美"模型。問題在于數據。
企業需要可信且具有公司特性的數據,才能讓智能體AI真正創造價值——這些數據存在于電子郵件、文檔、演示文稿和視頻等非結構化數據中。據估計,2022年企業產生的數據中90%是非結構化數據,但IBM預測其中僅有1%為大型語言模型(LLMs)所用。
非結構化數據的利用往往面臨巨大挑戰。這類數據分布廣泛且動態變化,存儲于多種格式中,缺乏清晰的標簽,且常需額外上下文才能完整解讀。傳統檢索增強生成(RAG)技術難以有效提取其價值,也無法妥善整合非結構化與結構化數據。
與此同時,各類孤立的工具會使AI數據處理架構變得復雜且繁瑣。企業需要同時管理數據倉庫、數據湖以及數據治理和數據集成工具。數據架構可能與它本應管理的非結構化數據一樣令人困惑。
許多組織并未解決根本問題。它們僅關注生成式AI的應用層,而非其下方的核心數據層。除非組織修復其數據基礎架構,否則AI智能體和其他生成式AI計劃將無法充分發揮其潛力。
幫助組織實現數據的AI就緒
IBM提供的新功能將使組織能夠采集、治理和檢索非結構化(及結構化)數據——在此基礎上,實現準確、高性能的生成式AI的規模化應用。
審核編輯 黃宇
-
IBM
+關注
關注
3文章
1819瀏覽量
75673 -
AI
+關注
關注
88文章
34909瀏覽量
277866
發布評論請先 登錄
從零到一:如何利用非結構化數據中臺快速部署AI解決方案
非結構化數據中臺:企業AI應用安全落地的核心引擎
廣和通發布AI紅外相機方案,引領多領域智能化升級
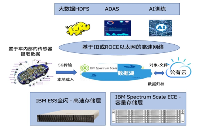
IBM Storage -?支持AI應用場景的數據存儲軟硬件解決方案





 工商網監
工商網監
評論