 NVIDIA RTX AI PC為AnythingLLM加速本地AI工作流
NVIDIA RTX AI PC為AnythingLLM加速本地AI工作流

大語言模型(LLM)基于包含數十億個 Token 的數據集訓練而來,能夠生成高質量的內容。它們是眾多最熱門 AI 應用的核心支撐技術,包括聊天機器人、智能助手、代碼生成工具等。
當前,使用 LLM 的便捷方式之一是通過 AnythingLLM。這是一款專為 AI 愛好者打造的桌面應用,能夠直接在用戶的 PC 上為其提供集眾多功能于一體且注重隱私保護的 AI 助手。
隨著 NVIDIA GeForce RTX 和 NVIDIA RTX PRO GPU 新增對 NVIDIA NIM 微服務的支持,AnythingLLM 用戶可享受更快的性能體驗,從而以更快的響應速度運行本地 AI 工作流。
AnythingLLM 是什么?
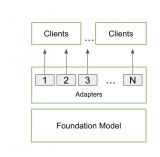
AnythingLLM 是一款集眾多功能于一身的 AI 應用,可供用戶運行本地 LLM、檢索增強生成(RAG)系統和代理式工具。
它在用戶選定的大語言模型與其數據之間起到橋梁作用,可以使用各類工具(即“技能”),從而能夠更輕松高效地將大語言模型應用于特定任務,例如:
問題解答:無需產生額外成本,即可從 Llama、DeepSeek R1 等頂尖大語言模型獲取問題解答。
個人數據查詢:使用檢索增強生成(RAG)對 PDF、Word 文件、代碼庫等內容做隱私提問。
文檔摘要:為長文檔(如研究論文)生成摘要。
數據分析:通過加載文件并使用大語言模型對其進行查詢來提取數據洞見。
代理式操作:使用本地或遠程資源對內容進行動態研究,并根據用戶提示詞運行生成式工具及操作。
AnythingLLM 能夠連接各類開源本地大語言模型,也可以連接規模更大的云端大語言模型,包括 OpenAI、微軟與 Anthropic 旗下的模型。此外,該應用還通過其社區中心提供了各種技能(skills),用以擴展代理式 AI 的功能。
AnythingLLM 支持一鍵安裝,且可作為獨立應用或瀏覽器擴展程序發布,無需復雜設置即可提供直觀易用的體驗,是 AI 愛好者(特別是 GeForce RTX 和 NVIDIA RTX PRO GPU 用戶)的絕佳選擇。
RTX 為 AnythingLLM 提供加速
GeForce RTX 與 NVIDIA RTX PRO GPU 能夠大幅提升 AnythingLLM 中 LLM 與智能體的運行性能,通過專為加速 AI 而設計的 Tensor Core 加速推理。
AnythingLLM 通過 Ollama 運行 LLM,并通過 Llama.cpp 及 GGML 機器學習張量庫加速端側執行。
Ollama、Llama.cpp 和 GGML 針對 NVIDIA RTX GPU 和第五代 Tensor Core 進行了優化。
隨著 NVIDIA 不斷推出新的 NIM 微服務和參考工作流(例如其日益壯大的 AI Blueprint 庫),像 AnythingLLM 這樣的工具將解鎖更豐富的多模態 AI 用例。
AnythingLLM — 現已支持 NVIDIA NIM
AnythingLLM 最近新增 NVIDIA NIM 微服務(性能經過優化的預打包生成式 AI 模型)支持,助力用戶在 RTX AI PC 上通過精簡易用的 API 輕松啟動 AI 工作流。
對于希望在工作流中對生成式 AI 模型進行快速測試的開發者而言,NVIDIA NIM 非常實用。用戶無需自行尋找最適用的模型、下載全部文件并為所有組件設置連接,因為 NVIDIA NIM 微服務提供了包含一切必需組件的單一容器。此外,它們在云端與 PC 端均可運行,因而便于開發者在本地完成原型設計,然后再部署到云端。
這些微服務均可以通過 AnythingLLM 用戶友好型界面使用,讓用戶可以快速測試與實驗。隨后,用戶可以利用 AnythingLLM 將其連接至工作流,也可以通過 NVIDIA AI Blueprint、NIM 文檔及示例代碼將其直接集成到相關應用或項目中。
-
機器人
+關注
關注
213文章
29663瀏覽量
212393 -
NVIDIA
+關注
關注
14文章
5292瀏覽量
106152 -
AI
+關注
關注
88文章
34909瀏覽量
277893
原文標題:RTX AI PC:為 AnythingLLM 加速本地 AI 工作流
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA攜手微軟加速代理式AI發展
使用NVIDIA RTX PRO Blackwell系列GPU加速AI開發
NVIDIA推出AI零售購物助手藍圖
AI工作流自動化是做什么的
NVIDIA助力西門子醫療加速醫學影像AI部署
NVIDIA亮相微軟Ignite技術大會
NVIDIA RTX AI Toolkit擁抱LoRA技術





 工商網監
工商網監
評論