") 緩解高性能存算一體芯片IR-drop問題的軟硬件協(xié)同設(shè)計
緩解高性能存算一體芯片IR-drop問題的軟硬件協(xié)同設(shè)計

在高性能計算與AI芯片領(lǐng)域,基于SRAM的存算一體(Processing-In-Memory, PIM)架構(gòu)因兼具計算密度、能效和精度優(yōu)勢成為主流方案。隨著存算一體芯片性能的持續(xù)攀升,供電電壓降(IR-drop)問題日益成為制約其性能、能效與可靠性的關(guān)鍵瓶頸,而傳統(tǒng)電路級優(yōu)化方法往往需在功耗、性能或面積上做出妥協(xié),難以實現(xiàn)系統(tǒng)化解決。
針對這一挑戰(zhàn),后摩智能與北京大學(xué)等高校合作的論文《AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM》,創(chuàng)新性地提出了AIM軟硬件協(xié)同設(shè)計,成功入選ISCA 2025。
該論文首創(chuàng)性地建立了量化工作負(fù)載與IR-drop關(guān)聯(lián)的關(guān)鍵參數(shù)HR,開發(fā)了基于正則化與權(quán)重優(yōu)化的算法以降低權(quán)重HR值,設(shè)計了動態(tài)反饋系統(tǒng)實現(xiàn)電壓/頻率的實時調(diào)節(jié)以應(yīng)對IR-drop波動,并通過HR感知的任務(wù)映射機(jī)制實現(xiàn)了跨層協(xié)同優(yōu)化。這一系列軟硬件協(xié)同創(chuàng)新技術(shù)有效緩解了高性能PIM芯片的IR-drop問題,同時顯著提升了芯片性能與能效表現(xiàn)。基于一款256 TOPS PIM芯片的后仿真驗證數(shù)據(jù)表明,AIM能夠?qū)R-drop大幅降低69.2%,并同步實現(xiàn)能效提升2.29倍或性能增益15.2%。
本文將展開介紹這一創(chuàng)新方法。
研究動機(jī)
在高性能存算一體(PIM)芯片中,IR-drop 已成為制約性能與可靠性的關(guān)鍵挑戰(zhàn)。7nm 工藝下 256 TOPS SRAM PIM 芯片實測顯示,動態(tài) IR-drop 可達(dá) 140mV,導(dǎo)致時序違規(guī)和計算精度退化。傳統(tǒng)電路級方案(如電源平面修改、電容插入)雖能緩解 IR-drop,但會引入高額設(shè)計成本并犧牲功耗、性能和面積(PPA)。例如,Graphcore IPU 通過 3D 封裝和深槽電容緩解 100mV IR-drop,卻導(dǎo)致設(shè)計成本激增。
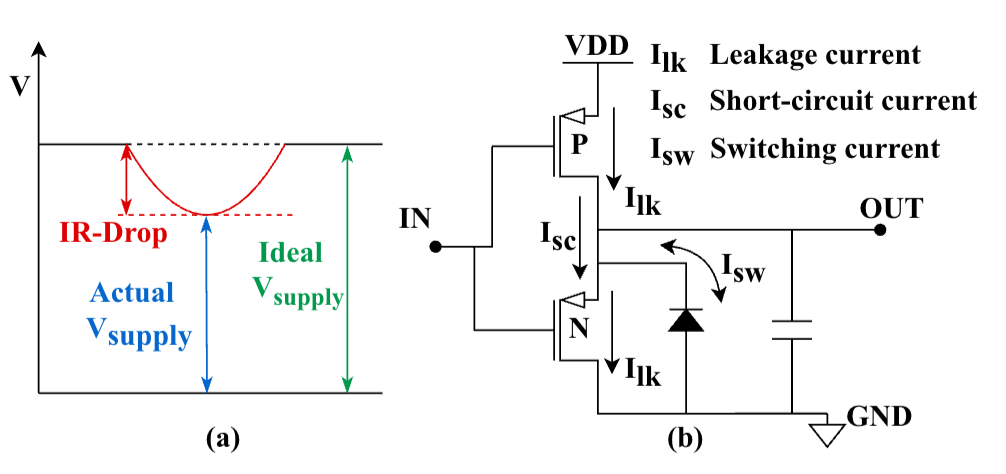
圖1:(a)IR-drop現(xiàn)象(b)靜態(tài)和動態(tài)電流
圖1 IR-drop現(xiàn)象。實際電源電壓和理想電壓的插值,由電流通過電源網(wǎng)絡(luò)的寄生電阻引起,這會導(dǎo)致電路單元電壓不足,引發(fā)時鐘延遲、時序違規(guī)甚至功能失效。
圖1:(b):靜態(tài)和動態(tài)電流。IR-drop 由靜態(tài)和動態(tài)電流共同決定,其中動態(tài)電流隨計算負(fù)載波動,是高性能 PIM 中 IR-drop 惡化的主要原因。
PIM架構(gòu)的獨特優(yōu)勢為架構(gòu)級優(yōu)化提供契機(jī):
工作負(fù)載規(guī)律性: PIM 專為神經(jīng)網(wǎng)絡(luò)設(shè)計, workload 可預(yù)測(如自LLMs的推理的結(jié)構(gòu)和工作流固定);
原位處理特性:權(quán)重數(shù)據(jù)可離線分析,輸入數(shù)據(jù)流和計算模式解耦。這為建立IR-drop和工作負(fù)載的關(guān)聯(lián)奠定基礎(chǔ)。
方法簡介
AIM通過“指標(biāo)建模-軟件優(yōu)化-硬件協(xié)同”三層架構(gòu)實現(xiàn)端到端IR-drop緩解:
1.架構(gòu)級指標(biāo)關(guān)聯(lián)
提出瞬時位流翻轉(zhuǎn)率(Rtog)和權(quán)重漢明率(HR),建立工作負(fù)載與IR-drop的直接關(guān)聯(lián)。Rtog量化了PIM bank中從SRAM到加法器的位流翻轉(zhuǎn)頻率,如圖2所示,其與 IR-drop 的線性相關(guān)系數(shù)在 7nm DPIM 中達(dá) 0.977。而HR作為Rtog的理論上界,可通過量化過程優(yōu)化,且與輸入無關(guān),便于離線處理。
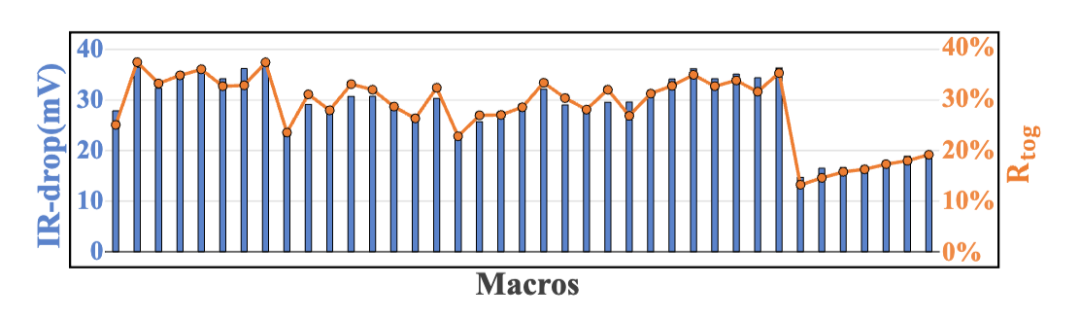
圖2:IR-drop和Rtog的相關(guān)性
2.軟件側(cè)HR優(yōu)化
2.1 LHR(低漢明率正則化)
在量化訓(xùn)練中引入可微HR近似,懲罰高HR權(quán)重,使權(quán)重分布趨向低HR局部極小值(如-8、0、8),精度損失可忽略。如圖3中所示,Resnet18的可以通過LHR平均降低28%,且精度損失可以忽略。
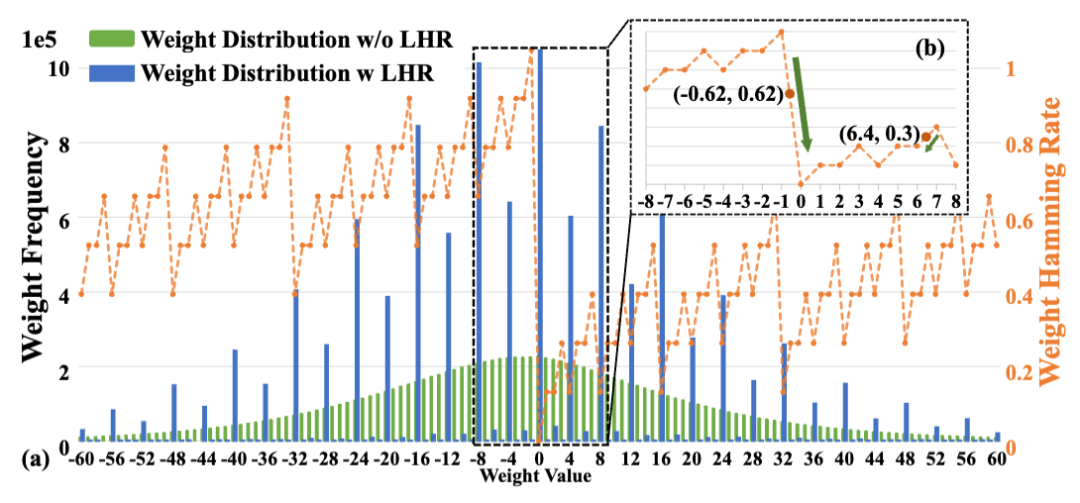
圖3:(a) LHR的權(quán)重分布與漢明率的局部極小值對齊 (b) 通過插值計算浮點數(shù)的HR及其相應(yīng)梯度
2.2 WDS(權(quán)重分布偏移)
通過向量化偏移δ(如8/16)將權(quán)重分布推向正區(qū)間,利用補(bǔ)碼編碼特性降低HR,并通過硬件移位補(bǔ)償消除計算誤差。
3.硬件側(cè)動態(tài)調(diào)節(jié)
3.1 IR-Booster
結(jié)合軟件HR信息與硬件IR監(jiān)測,動態(tài)調(diào)整電壓-頻率(V-f)對。通過安全級與激進(jìn)級雙層調(diào)節(jié),在保障可靠性的同時提升能效(如低功耗模式下能效提升2.29×)。
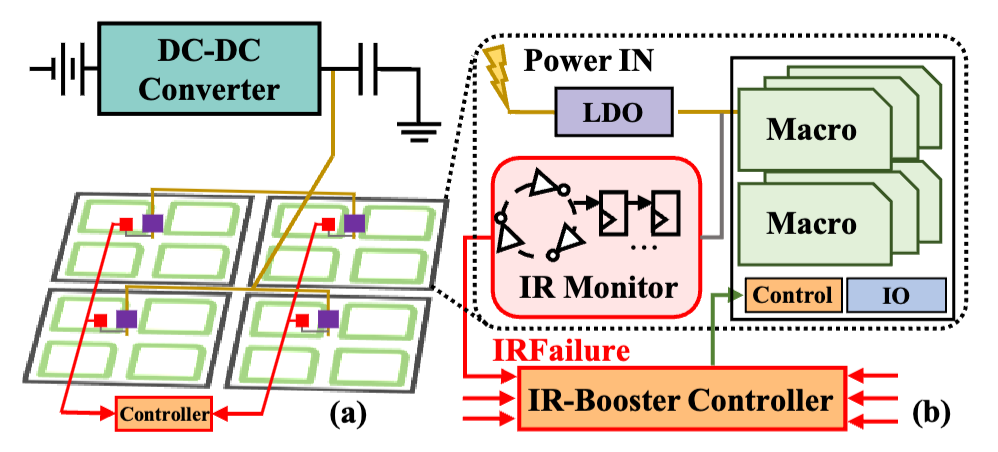
圖4:(a) 宏組顆粒度下的電源和V-f調(diào)整 (b) 由IRFailure調(diào)節(jié)的IR-Booster
3.2 HR-aware任務(wù)映射
基于模擬退火算法,按 HR 特性分配任務(wù)至宏單元組,避免不同 HR 任務(wù)相互干擾。與順序映射相比,如圖5所示,該方法將多算子并發(fā)時能效提升 15%~22%。
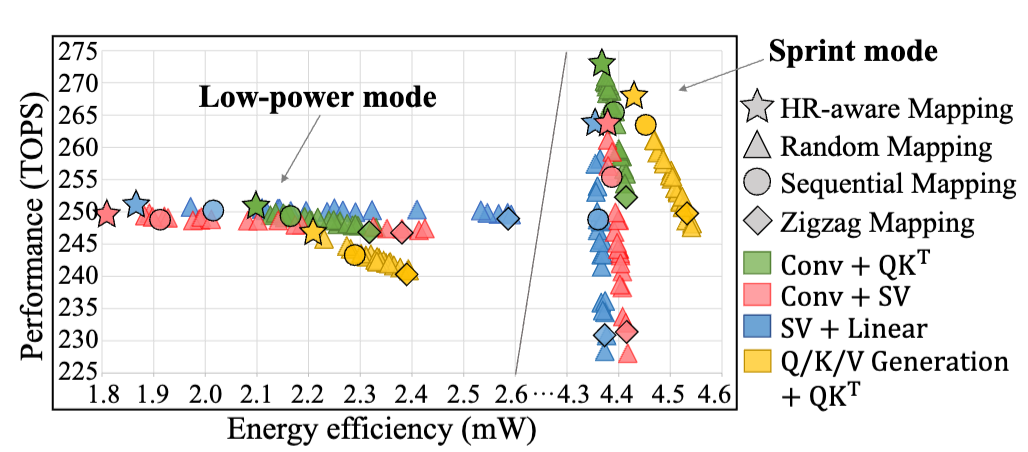
圖5:HR感知任務(wù)映射與其他方法對比
實驗結(jié)果
在7nm 256 TOPS PIM芯片的后布局仿真中,AIM展現(xiàn)顯著優(yōu)勢:
1.IR-drop緩解
圖6展示了展示了應(yīng)用 AIM 前后,7nm PIM 芯片布局中 IR-drop(電源網(wǎng)絡(luò)電壓降)的分布變化。后布局仿真顯示,AIM 將宏單元內(nèi)的 IR-drop 從 140mV 降至 43.2~58.1mV,緩解率達(dá) 58.5%~69.2%,直接證明其在硬件層面的有效性。
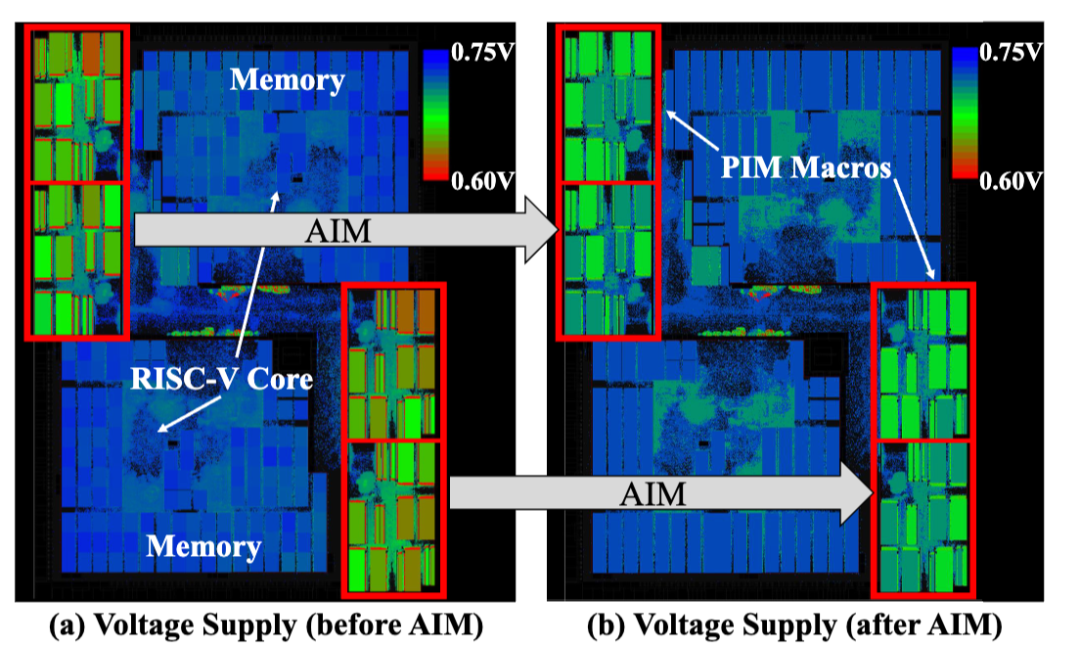
圖6:7nm 工藝 256 TOPS PIM 芯片布局的 IR-drop 緩解效果
2.能效與性能提升
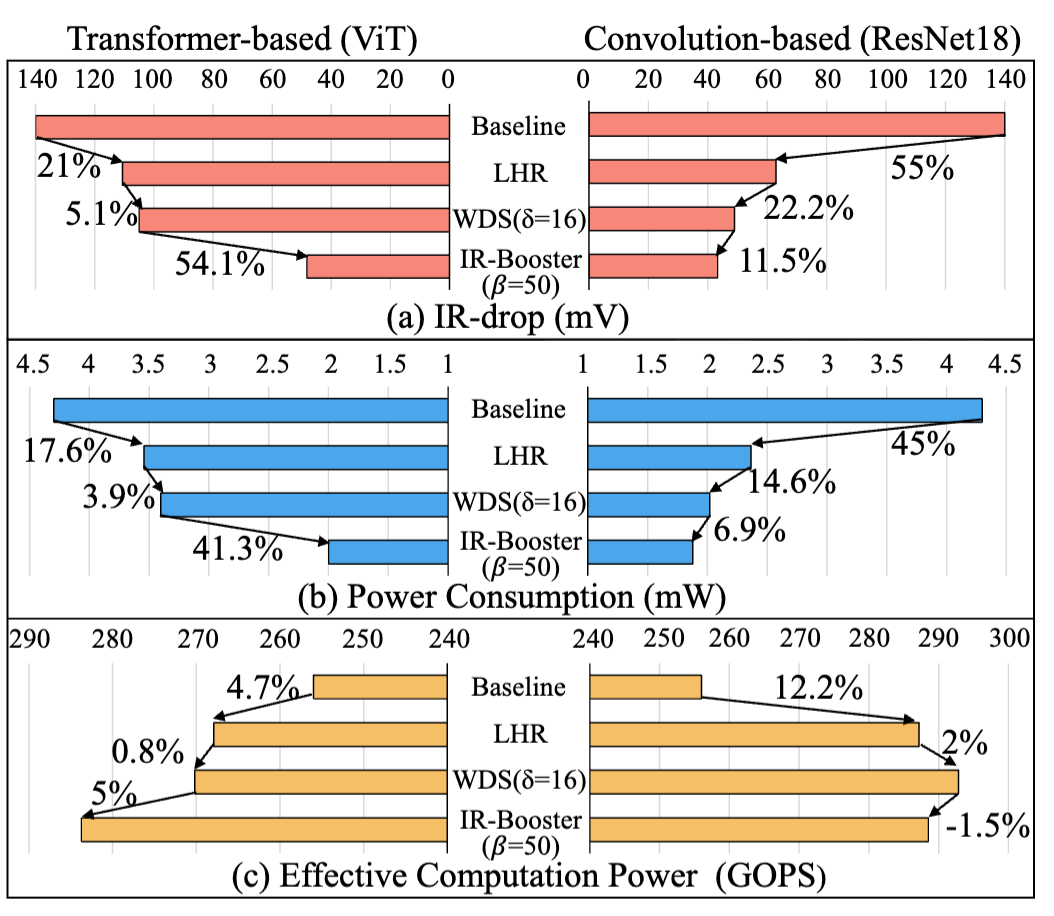
圖7:IR-drop、功耗與性能的消融研究
如圖7所示,AIM在解決IR-drop的同時優(yōu)化了芯片的功耗和計算性能。
能效比提升1.91~2.29×(宏單元的功耗從4.2978mW降至1.876mW);
計算性能提升1.129~1.152×(256TOPS提升至295TOPS)。
3.任務(wù)映射優(yōu)化
相比順序映射,HR-aware映射使多算子并發(fā)時的能效提升15%~22%,延遲降低9ms。
總結(jié)
AIM通過軟硬件協(xié)同設(shè)計,突破傳統(tǒng)IR-drop緩解的PPA瓶頸,為高性能PIM提供了兼具效率與可靠性的解決方案。后布局仿真驗證了其在7nm工藝下的有效性,未來可擴(kuò)展至浮點PIM和異構(gòu)計算架構(gòu)(如TPU、GPU)。該工作為存算一體芯片的實用化部署提供了關(guān)鍵技術(shù)支撐,代碼與模型已開源(https://github.com/pku-zyp/LHR-of-AIM-in-ISCA25.git),推動學(xué)術(shù)界與產(chǎn)業(yè)界的進(jìn)一步創(chuàng)新。
-
芯片
+關(guān)注
關(guān)注
459文章
52464瀏覽量
440166 -
存算一體
+關(guān)注
關(guān)注
0文章
108瀏覽量
4653 -
后摩智能
+關(guān)注
關(guān)注
0文章
35瀏覽量
1372
原文標(biāo)題:后摩前沿 | 緩解高性能存算一體芯片IR-drop問題的軟硬件協(xié)同設(shè)計
文章出處:【微信號:后摩智能,微信公眾號:后摩智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
存算一體大算力AI芯片將逐漸走向落地應(yīng)用
談?wù)?b class='flag-5'>芯片設(shè)計中的IR-drop
存算一體技術(shù)路線如何選

基于Altera FPGA的軟硬件協(xié)同仿真方法介紹
基于SoPC的嵌入式軟硬件協(xié)同設(shè)計性能怎么優(yōu)化?
基于軟硬件協(xié)同設(shè)計的低功耗生理信號處理ASIC設(shè)計
思科謀求“軟硬件一體”轉(zhuǎn)型
軟硬件協(xié)同設(shè)計是系統(tǒng)芯片的基礎(chǔ)設(shè)計方法學(xué)
存算一體芯片在可穿戴設(shè)備市場有哪些機(jī)會
2023年存算一體是芯片設(shè)計的技術(shù)趨勢
基于3DIC架構(gòu)的存算一體芯片仿真解決方案
存算一體芯片的技術(shù)壁壘






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論