") 英特爾新一代AI芯片NNP-L1000明年面世
英特爾新一代AI芯片NNP-L1000明年面世

英特爾首屆AI開發(fā)者大會(huì)發(fā)布了一系列機(jī)器學(xué)習(xí)軟件工具,并宣布包括其首款商用神經(jīng)網(wǎng)絡(luò)處理器產(chǎn)品將于2019年推出。英特爾在舊金山舉辦第一屆AI開發(fā)者大會(huì)(AI Dev Con),英特爾人工智能負(fù)責(zé)人Naveen Rao做了開場(chǎng)演講。
Rao此前是Nervana的CEO和聯(lián)合創(chuàng)始人,該公司于2016年被英特爾收購(gòu)。
Naveen Rao
在會(huì)上,Rao發(fā)布了一系列機(jī)器學(xué)習(xí)軟件工具,并宣布英特爾新一代產(chǎn)品,其中包括其首款商用NNP產(chǎn)品NNP-L1000,將于2019年推出。
以下從軟件和硬件兩個(gè)方面介紹AI Dev Con的重點(diǎn)。
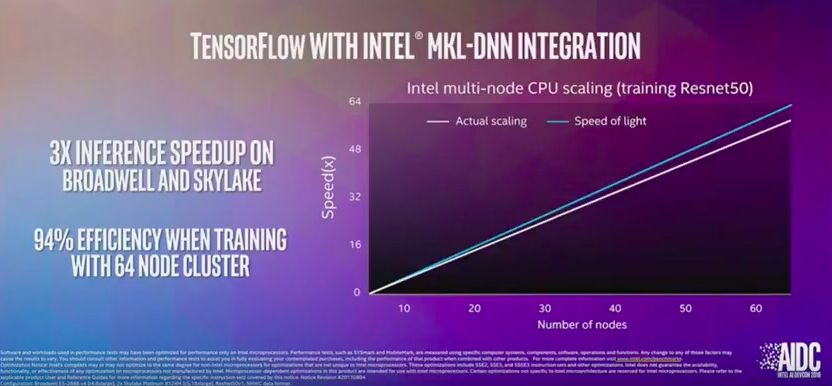
MKL-DNN是用于深層神經(jīng)網(wǎng)絡(luò)的數(shù)學(xué)內(nèi)核庫(kù)。它是神經(jīng)網(wǎng)絡(luò)中常見組件的數(shù)學(xué)程序列表,包括矩陣乘數(shù)、批處理規(guī)范、歸一化和卷積。該庫(kù)針對(duì)在英特爾CPU上部署模型進(jìn)行了優(yōu)化。
nGraph開發(fā)者選擇不同的AI框架,它們都有各自的優(yōu)點(diǎn)和缺點(diǎn)。為了使芯片具有靈活性,后端編譯器必須能夠有效地適應(yīng)所有的芯片。
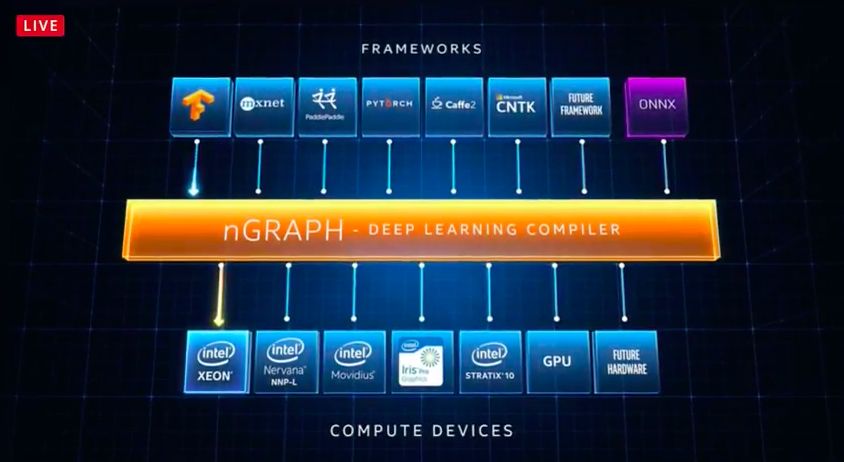
nGraph是一個(gè)編譯器,它可以在英特爾的芯片上運(yùn)行。開發(fā)人員可能想要在英特爾的Xeons處理器上訓(xùn)練他們的模型,然后使用英特爾的神經(jīng)網(wǎng)絡(luò)處理器(NNP)進(jìn)行推理。
BigDL是Apache Spark的另一個(gè)庫(kù),它的目標(biāo)是通過(guò)分布式學(xué)習(xí)在深度學(xué)習(xí)中處理更大的工作負(fù)載。應(yīng)用程序可以用Scala或Python編寫,并在Spark集群上執(zhí)行。
OpenVINOA軟件工具包用于處理“邊緣”(即攝像頭或移動(dòng)電話)視頻的模型。開發(fā)人員可以實(shí)時(shí)地做面部識(shí)別的圖像分類。它預(yù)計(jì)將在今年晚些時(shí)候開放,但現(xiàn)在可以下載了。
再來(lái)看硬件部分。
英特爾在這方面比較沉默,沒(méi)有透露更多的細(xì)節(jié)。
“幾年前Xeons不適合AI,但現(xiàn)在真的已經(jīng)改變了。”Rao強(qiáng)調(diào),增加的內(nèi)存和計(jì)算意味著自Haswell芯片以來(lái)性能提高了100倍,并且推理的性能提高了近200倍。
“你可能聽說(shuō)過(guò)GPU比CPU快100倍。這是錯(cuò)誤的。”他補(bǔ)充說(shuō),“今天大多數(shù)推理都是在Xeons上運(yùn)行的。”
Rao沒(méi)有提到Nvidia,他解釋說(shuō)GPU在深度學(xué)習(xí)方面起了個(gè)好頭,但受限于嚴(yán)重的內(nèi)存限制。 Xeon擁有更多的內(nèi)存,可以擴(kuò)展到批量大的內(nèi)存,因此它更適合推理。
在現(xiàn)場(chǎng),ZIVA CEO James Jacobs還介紹了如何將Xeons用于3D圖像渲染。
左邊的獅子是沒(méi)有使用AI,右邊的獅子使用了AI,效果很棒。
他也簡(jiǎn)要地談到了FPGA加速的問(wèn)題,并表示英特爾正在研發(fā)一種“離散加速器”(discrete accelerator)進(jìn)行推理,但沒(méi)有透露更多細(xì)節(jié)。
同時(shí),還介紹了Intel Movidius的神經(jīng)計(jì)算棒。它是一個(gè)U盤,可以運(yùn)行使用TensorFlow和Caffe編寫的模型,耗電量大約一瓦。去年,英特爾公司決定終止其可穿戴設(shè)備,如智能手表和健身腕帶。
現(xiàn)場(chǎng)還展示了一段用計(jì)算棒來(lái)進(jìn)行AI作曲的DEMO,人類演奏者演奏一段曲子,AI能夠在這段曲子的基礎(chǔ)上進(jìn)行創(chuàng)作。
英特爾去年宣布神經(jīng)網(wǎng)絡(luò)處理器(NNP)芯片。雖然沒(méi)有發(fā)布任何基準(zhǔn)測(cè)試結(jié)果,但英特爾表示將會(huì)有可供選擇的客戶。
Rao也沒(méi)有透露多少細(xì)節(jié)。不過(guò),大家所知道的是,它包含12個(gè)基于其“Lake Crest”架構(gòu)的內(nèi)核,總共擁有32GB內(nèi)存,在未公開的精度下性能達(dá)到40 TFLOPS,理論上的帶寬不足800納秒,在低延遲的互連上,每秒2.4兆的帶寬。
最后介紹了NNP L1000,Rao對(duì)它的介紹更少,這將是第一個(gè)商業(yè)NNP模型,并將在2019年推出。它將基于新的Spring Crest體系結(jié)構(gòu),預(yù)計(jì)將比之前的Lake Crest模型快3到4倍。
開發(fā)者大會(huì)的當(dāng)天,英特爾官網(wǎng)發(fā)出一篇Rao的署名文章,對(duì)英特爾Nervana神經(jīng)網(wǎng)絡(luò)處理器(NNP)進(jìn)行了介紹。
Nervana NNP有一個(gè)明確的設(shè)計(jì)目標(biāo),可實(shí)現(xiàn)高計(jì)算利用率和支持多芯片互連的真模型并行。
行業(yè)里討論了很多關(guān)于最大的理論性能,然而,實(shí)際情況是,除非體系結(jié)構(gòu)有能夠支持這些計(jì)算元素的高利用率的儲(chǔ)存器子系統(tǒng),否則大部分計(jì)算都是沒(méi)有意義的。此外,行業(yè)發(fā)布的大部分性能數(shù)據(jù)使用的是大型矩陣,這些矩陣通常在現(xiàn)實(shí)世界的神經(jīng)網(wǎng)絡(luò)中并不常見。
英特爾專注于為神經(jīng)網(wǎng)絡(luò)創(chuàng)建一個(gè)平衡的架構(gòu),它還包括低延遲的高芯片到芯片帶寬。NNP系列的初始性能基準(zhǔn)在利用率和互連方面顯示出強(qiáng)勁的競(jìng)爭(zhēng)力。具體包括:
使用A(1536, 2048)和B(2048, 1536)矩陣進(jìn)行矩陣乘法運(yùn)算的一般矩陣,在單個(gè)芯片上實(shí)現(xiàn)了96.4個(gè)百分點(diǎn)的計(jì)算利用率。這代表了在單個(gè)芯片上的實(shí)際(非理論)性能的38TOP/s。支持模型并行訓(xùn)練的多芯片分布式GEMM操作實(shí)現(xiàn)了A(6144,2048)和B(2048,1536)矩陣大小的接近線性縮放和96.2%的縮放效率,使得多個(gè)NNP能夠連接在一起,并將我們從其他架構(gòu)的內(nèi)存限制中釋放出來(lái)。
我們測(cè)量了89.4 %的單方向芯片到芯片的效率,理論上的帶寬小于790ns(納秒)的延遲,并且將其應(yīng)用于2.4Tb/s的高帶寬、低延遲互連。
所有這些都在單芯片總功率范圍內(nèi)低于210瓦的情況下進(jìn)行,這只是英特爾Nervana NNP(Lake Crest)原型。
英特爾將在2019年提供第一個(gè)商用NNP產(chǎn)品——英特爾Nervana NNP-L1000(Spring Crest)。
預(yù)計(jì)英特爾Nervana NNP-L1000的性能將達(dá)到第一代Lake Crest產(chǎn)品的3-4倍。
在英特爾Nervana NNP-L1000中,還將支持bfloat16,這是一種業(yè)界廣泛用于神經(jīng)網(wǎng)絡(luò)的數(shù)字格式。
隨著時(shí)間的推移,英特爾將在其AI產(chǎn)品線上擴(kuò)展bfloat16支持,包括英特爾Xeons處理器和英特爾FPGA。
-
英特爾
+關(guān)注
關(guān)注
61文章
10189瀏覽量
174362 -
AI
+關(guān)注
關(guān)注
88文章
34839瀏覽量
277445 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134368
原文標(biāo)題:超越傳統(tǒng)CPU?英特爾新一代AI芯片明年面世
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
直擊Computex 2025:英特爾重磅發(fā)布新一代GPU,圖形和AI性能躍升3.4倍

直擊Computex2025:英特爾重磅發(fā)布新一代GPU,圖形和AI性能躍升3.4倍

英特爾先進(jìn)封裝:助力AI芯片高效集成的技術(shù)力量

英特爾塑造未來(lái)出行:AI增強(qiáng)型軟件定義汽車
英特爾發(fā)布新一代Core Ultra芯片,為2025移動(dòng)計(jì)算確立新標(biāo)準(zhǔn)

英特爾發(fā)布全新企業(yè)AI一體化方案
英特爾與火山引擎飛連攜手升級(jí)AI時(shí)代企業(yè)IT管理體驗(yàn)
英特爾目標(biāo)明年出貨1億臺(tái)AI PC
英特爾計(jì)劃明年AI PC出貨一億臺(tái)
英特爾聚焦AI座艙
英特爾調(diào)降明年AI服務(wù)器芯片出貨目標(biāo)
AI PC市場(chǎng)爆發(fā),英特爾、高通相繼推出新一代AI PC芯片,戰(zhàn)況火熱升級(jí)
IBM Cloud將部署英特爾Gaudi 3 AI芯片
軟銀與英特爾AI芯片合作計(jì)劃告吹
支持140億參數(shù)AI模型,229TOPS!英特爾重磅發(fā)布第一代車載獨(dú)立顯卡






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論