 自動駕駛中機器學習算法主要分為哪四類?
自動駕駛中機器學習算法主要分為哪四類?

機器學習算法已經被廣泛應用于自動駕駛各種解決方案,電控單元中的傳感器數據處理大大提高了機器學習的利用率,也有一些潛在的應用,比如利用不同外部和內部的傳感器的數據融合(如激光雷達、雷達、攝像頭或物聯網),評估駕駛員狀況或為駕駛場景分類等。
在 KDnuggets 網站此前發表的一篇文章中,作者 Savaram Ravindra 將自動駕駛中機器學習算法主要分為四類,即決策矩陣算法、聚類算法、模式識別算法和回歸算法。我們跟他一起看看,這些算法都是怎樣應用的。
算法概覽
我們先設想這樣一個自動駕駛場景——汽車的信息娛樂系統接收傳感器數據融合系統的信息,如果系統發現司機身體有恙,會指導無人車開往附近的醫院。
這項應用以機器學習為基礎,能識別司機的語音、行為,進行語言翻譯等。所有這些算法可以分為兩類:監督學習和無監督學習,二者的區別在它們學習的方法。
監督學習算法利用訓練數據集學習,并會堅持學到達到所要求的置信度(誤差的最小概率)。監督學習算法可分為回歸、分類和異常檢測或維度縮減問題。
無監督學習算法會在可用數據中獲取價值。這意味著算法能找到數據的內部聯系、找到模式,或者根據數據間的相似程度將數據集劃分出子集。無監督算法可以被粗略分類為關聯規則學習和聚類。
強化學習算法是另一類機器學習算法,這種學習方法介于監督學習和無監督學習之間。
監督學習會給每個訓練樣例目標標簽,無監督學習從來不會設立標簽——而強化學習就是它們的平衡點,它有時間延遲的稀疏標簽——也就是未來的獎勵。每個 agent 會根據環境獎勵學習自身行為。了解算法的優點和局限性,并開發高效的學習算法是強化學習的目標。
在自動駕駛汽車上,機器學習算法的主要任務之一是持續感應周圍環境,并預測可能出現的變化。
我們不妨分成四個子任務:
檢測對象
物體識別及分類
物體定位
運動預測
機器學習算法也可以被寬松地分為四類:
決策矩陣算法
聚類算法
模式識別算法
回歸算法
機器學習算法和任務分類并不是一一對應的,比如說,回歸算法既可以用于物體定位,也可以用于對象檢測和運動預測。
決策矩陣算法
決策矩陣算法能系統分析、識別和評估一組信息集和值之間關系的表現,這些算法主要是用戶決策。車輛的制動或轉向是有依據的,它依賴算法對下一個運動的物體的識別、分類、預測的置信水平。
決策矩陣算法是由獨立訓練的各種決策模型組合起來的模型,某種程度上說,這些預測組合在一起構成整體的預測,同時降低決策的錯誤率。AdaBoosting 是最常用的算法。
AdaBoost
Adaptive Boosting 算法也簡稱為 AdaBoost,它是多種學習算法的結合,可應用于回歸和分類問題。
與其他機器學習算法相比,它克服了過擬合問題,并且對異常值和噪聲數據非常敏感。它需要經過多次迭代才能創造出強學習器,它具有自適應性。學習器將重點關注被分類錯誤的樣本,最后再通過加權將弱學習器組合成強學習器。
AdaBoost 幫助弱閾值分類器提升為強分類器。上面的圖像描繪了如何在一個可以理解性代碼的單個文件中實現 AdaBoost 算法。該函數包含一個弱分類器和 boosting 組件。
弱分類器嘗試在數據維數中找到理想閾值,并將數據分為 2 類。分類器迭代時調用數據,并在每個分類步驟后,改變分類樣本的權重。因此,它實際創建了級聯的弱分類器,但性能像強分類器一樣好。
聚類算法
有時,系統獲取的圖像不清楚,難以定位和檢測對象,分類算法有可能丟失對象。在這種情況下,它們無法對問題分類并將其報告給系統。
造成這種現象可能的原因包括不連續數據、極少的數據點或低分辨率圖像。K-means 是一種常見的聚類算法。
K-means
K-means 是著名的聚類算法,它從數據對象中選擇任意 k 個對象作為初始聚類中心,再根據每個聚類對象的均值(中心對象)計算出每個對象與中心對象的距離,然后根據最小距離重新劃分對象,最后重新計算調整后的聚類的均值。
下圖形象描述了 K-means 算法。其中:
(a)表示原始數據集。
(b)表示隨機初始聚類中心。
(c-f)表示運行 2 次 k-means 迭代演示。
模式識別算法(分類)
通過高級駕駛輔助系統(ADAS)中的傳感器獲得的圖像由各種環境數據組成,圖像過濾可以用來決定物體分類樣例,排除無關的數據點。在對物體分類前,模式識別是一項重要步驟,這種算法被定義為數據簡化算法。數據簡化算法可以減少數據集的邊緣和折線(擬合線段)。
PCA(原理分量分析)和 HOG(定向梯度直方圖),支持向量機(Support Vector Machines,SVM)是 ADAS 中常用的識別算法。我們也經常用到 K 最近鄰(KNN,K-NearestNeighbor)分類算法和貝葉斯決策規則。
支持向量機(SVM)
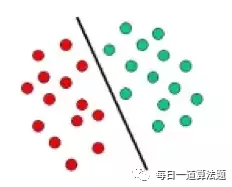
SVM 依賴于定義決策邊界的決策層概念。決策平面分隔由不同的類成員組成的對象集。下面是一個示意圖,在這里,物體要么屬于紅色類要么綠色類,分隔線將彼此分隔開。落在左邊的新物體會被標記為紅色,落在右邊就被標記為綠色。
回歸算法
這種算法的專長是預測事件,回歸分析會對兩個或更多變量之間的關聯性進行評估,并對不同規模上的變量效果進行對照。
回歸算法通常由三種度量標準驅動:
回歸線的形狀
因變量的類型
因變量的數量
在無人車的驅動和定位方面,圖像在 ADAS 系統中扮演著關鍵角色。對于任何算法來說,最大的挑戰都是如何開發一種用于進行特征選取和預測的、基于圖像的模型。
回歸算法利用環境的可重復性來創造一個概率模型,這個模型揭示了圖像中給定物體位置與該圖像本身間的關系。
通過圖形采樣,此概率模型能夠提供迅速的在線檢測,同時也可以在線下進行學習。模型還可以在不需要大量人類建模的前提下被進一步擴展到其他物體上。
算法會將某一物體的位置以一種在線狀態下的輸出和一種對物體存在的信任而返回。回歸算法同樣可以被應用到短期預測和長期學習中,在自動駕駛上,則尤其多用于決策森林回歸、神經網絡回歸以及貝葉斯回歸。
回歸神經網絡
神經網絡可以被用在回歸、分類或非監督學習上。它們將未標記的數據分組并歸類,或者監督訓練后預測連續值。神經網絡的最后一層通常通過邏輯回歸將連續值變為變量 0 或 1。

在上面的圖表中,x 代表輸入,特征從網絡中的前一層傳遞到下一層。許多 x 將輸入到最后一個隱藏層的每個節點,并且每一個 x 將乘以相關權重 w。
乘積之和將被移動到一個激活函數中,在實際應用中我們經常用到 ReLu 激活函數。它不像 Sigmoid 函數那樣在處理淺層梯度問題時容易飽和。
-
機器學習
+關注
關注
66文章
8499瀏覽量
134391 -
無人駕駛
+關注
關注
99文章
4166瀏覽量
123281 -
自動駕駛
+關注
關注
788文章
14274瀏覽量
170273
原文標題:無人駕駛中的應用中都有哪些機器學習算法
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論