") Google翻譯出現(xiàn)“水逆”,是員工的惡作劇?
Google翻譯出現(xiàn)“水逆”,是員工的惡作劇?

最近,一些網(wǎng)友使用的 Google 翻譯“水逆”了。
在Reddit上,有網(wǎng)友截圖顯示,在 Google 翻譯中當(dāng)某些語(yǔ)種的詞匯翻譯成英語(yǔ)時(shí),輸出的卻是毫無(wú)由頭的宗教語(yǔ)言。比如鍵入 19 個(gè) dog,將其從毛利語(yǔ)翻譯成英語(yǔ)時(shí),輸出的卻是“距離十二點(diǎn)的世界末日時(shí)鐘還差三分鐘,我們正在經(jīng)歷世界上的人物和戲劇性發(fā)展,這預(yù)示著我們正在無(wú)線接近末日,耶穌回歸時(shí)日將近。”
但這只是眾多無(wú)厘頭翻譯的其中之一。還有網(wǎng)友放出了很多“不詳”的翻譯內(nèi)容。例如,在索馬里語(yǔ)中,“ag”這個(gè)詞被翻譯成了“Gershon 的兒子(sons of Gershon)”,“耶和華的名字(name of the LORD)”,并且會(huì)引用圣經(jīng)里的“cubits”(計(jì)量單位)和Deuteronomy(《申命記》)。
有網(wǎng)友留言稱其為“惡魔”或者“幽靈”,猜測(cè)這是 Google 員工的惡作劇,也有人建議設(shè)置“建議編輯”功能,讓用戶可以進(jìn)行修改為正確內(nèi)容。Google 發(fā)言人 Justin Burr 在一封電子郵件中稱:這只是一個(gè)將無(wú)意義的話語(yǔ)輸入系統(tǒng)然后產(chǎn)生無(wú)意義輸出的功能。
不過(guò) Justin Burr 并未透露 Google 翻譯使用的訓(xùn)練數(shù)據(jù)是否有宗教文本。但上述詭異輸出內(nèi)容很可能已被 Google 翻譯修正,AI科技大本營(yíng)編輯輸入上述相同內(nèi)容后也并未發(fā)現(xiàn)異常。
但人們對(duì)探討 Google 翻譯出現(xiàn)如此結(jié)果的背后原因熱情不減,更專業(yè)的聲音在不斷發(fā)出。哈佛大學(xué)助理教授 Andrew Rush 認(rèn)為,這很可能與 2 年前 Google 翻譯技術(shù)的改變有關(guān),它目前使用了的是“神經(jīng)機(jī)器翻譯(NMT)”的技術(shù)。
BBN Technologies 的科學(xué)家 Sean Colbath 從事機(jī)器翻譯工作,他同意奇怪的輸出可能是由于 Google 翻譯的算法試圖在混亂中尋找秩序。他還指出,索馬里語(yǔ)、夏威夷語(yǔ)以及毛利語(yǔ)等產(chǎn)生最奇怪結(jié)果的語(yǔ)言,它們用于訓(xùn)練的翻譯文本比英語(yǔ)或漢語(yǔ)等更廣泛使用的語(yǔ)言要少很多。所以他認(rèn)為,Google 可能會(huì)使用像圣經(jīng)等被翻譯成多種語(yǔ)言的宗教文本來(lái)訓(xùn)練小語(yǔ)種的模型,這也解釋了為什么會(huì)最終輸出宗教內(nèi)容。
前 Google 員工 Delip Rao 在其博客上則指出,當(dāng)談到平行語(yǔ)料庫(kù)時(shí),宗教文本是最低層次的共同標(biāo)準(zhǔn)資源,像“圣經(jīng)”和“古蘭經(jīng)”這樣的主要宗教文本有各種語(yǔ)言版本。
比如,如果你為政府部署一個(gè) Urdu-to-English (烏爾都語(yǔ)——英語(yǔ))的機(jī)器翻譯系統(tǒng),那么很容易將一堆已經(jīng)翻譯成烏爾都語(yǔ)的宗教文本組合在一起。因此,可以合理地假設(shè) Google 的平行語(yǔ)料庫(kù)中包含所有的宗教文本,而對(duì)于許多資源不足的語(yǔ)言,它們不只是訓(xùn)練語(yǔ)料庫(kù)中微不足道的部分。
那么,為什么我們看到 Google 翻譯會(huì)輸出宗教文本,尤其是以那些資源不足的語(yǔ)言對(duì)作為輸入時(shí) ,如上文中的毛利語(yǔ)?一種解釋是,因?yàn)樽诮涛谋景S多只會(huì)在宗教文本中出現(xiàn)的罕見詞,而這些詞在其他任何地方都不會(huì)出現(xiàn)。因此,罕見的詞語(yǔ)可能會(huì)觸發(fā)解碼器中的宗教情境,尤其是當(dāng)這些文本的比例很大時(shí)。另一種解釋是該模型對(duì)輸入的內(nèi)容沒(méi)有太多的統(tǒng)計(jì)支持,而輸出也只是解碼器模型的無(wú)意義采樣。
更重要的是,他想要指出現(xiàn)在的神經(jīng)機(jī)器翻譯 (NMT) 真正存在的問(wèn)題。
他特意總結(jié)了2017 年 Philipp Koehn 和 Rebecca Knowles 撰寫的一篇論文,內(nèi)容如下:
1.NMT 在域外數(shù)據(jù)上表現(xiàn)很差:像 Google 翻譯這樣的通用 MT 系統(tǒng)在法律或金融等專業(yè)領(lǐng)域的表現(xiàn)尤其糟糕。此外,與基于短語(yǔ)的翻譯系統(tǒng)等傳統(tǒng)方法相比,NMT 系統(tǒng)的效果更差。到底有多糟糕?如下圖所示,其中非對(duì)角線元素表示域外結(jié)果,綠色是 NMT 的結(jié)果,藍(lán)色是基于短語(yǔ)的翻譯系統(tǒng)的結(jié)果。
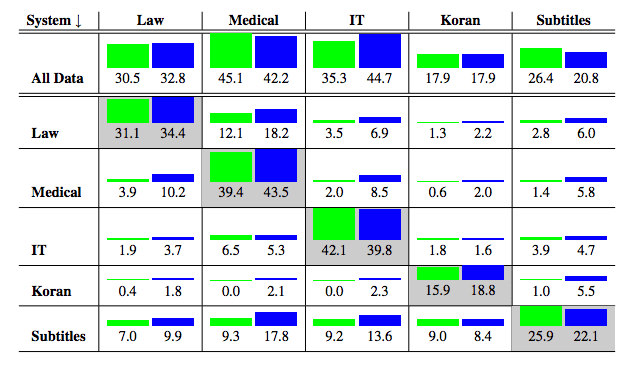
MT 系統(tǒng)在一個(gè)域 (行) 上訓(xùn)練并在另一個(gè)域 (列) 上進(jìn)行測(cè)試。藍(lán)色表示基于短語(yǔ)翻譯系統(tǒng)的表現(xiàn),而綠色表示 NMT 的表現(xiàn)。
2.NMT 在小數(shù)據(jù)集上的表現(xiàn)很差:雖然這算是機(jī)器學(xué)習(xí)的通病,但這個(gè)問(wèn)題在 NMT 中體現(xiàn)尤其明顯。相比基于短語(yǔ)的 MT 系統(tǒng),雖然 NMT 隨著數(shù)據(jù)量的增加能進(jìn)行更好地概括 ,但在小數(shù)據(jù)量情況下 NMT 的表現(xiàn)確實(shí)更糟糕。
引用作者的話來(lái)說(shuō),“在資源較少的情況下,NMT 會(huì)產(chǎn)生與輸入無(wú)關(guān)的輸出,盡管這些輸出是流暢的。”這可能也是 Motherboard 那篇文章中探討 NMT 表現(xiàn)怪異的另一個(gè)原因。
3.Subword NMT 在罕見詞匯上的表現(xiàn)很糟糕:雖然它的表現(xiàn)仍然要好過(guò)基于短語(yǔ)的翻譯系統(tǒng),但對(duì)于罕見或未見過(guò)的詞語(yǔ),NMT 的表現(xiàn)不佳。例如,那些系統(tǒng)只觀察到一次的單詞就會(huì)被 drop 掉。像 byte-pair encoding 這樣的技術(shù)對(duì)解決這個(gè)問(wèn)題有所幫助,但我們有必要對(duì)此進(jìn)行更詳細(xì)的研究。
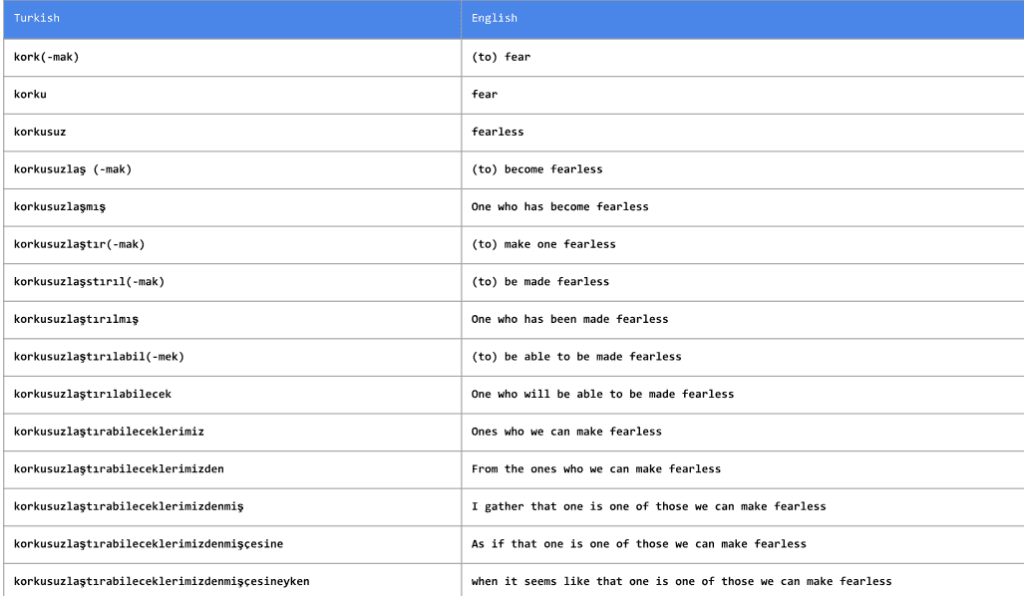
我們可以看到圖中像土耳其語(yǔ) (Turkish) 這樣的語(yǔ)言,遇到詞的變形形式是很常見的。
4.長(zhǎng)句:以長(zhǎng)句編碼并產(chǎn)生長(zhǎng)句,這仍然是一個(gè)開放的、值得研究的話題。在法律等領(lǐng)域,冗長(zhǎng)復(fù)雜的句子是很常見的。MT 系統(tǒng)的性能將隨句子長(zhǎng)度而降級(jí),而 NMT 系統(tǒng)亦是如此。引入注意力機(jī)制可能會(huì)有所幫助,但問(wèn)題還遠(yuǎn)未解決。
5.注意力機(jī)制 != 對(duì)齊:這是一個(gè)非常微妙但又很重要的問(wèn)題。在傳統(tǒng)的 SMT 系統(tǒng)中,如基于短語(yǔ)的翻譯系統(tǒng),語(yǔ)句對(duì)齊能夠提供有用的調(diào)試信息來(lái)檢查模型。但即便論文中經(jīng)常將軟注意力機(jī)制視為“軟對(duì)齊”,注意力機(jī)制并不是傳統(tǒng)意義上的對(duì)齊。在 NMT 系統(tǒng)中,除了源域中的動(dòng)詞外,目標(biāo)中的動(dòng)詞也可以作為主語(yǔ)和賓語(yǔ)。
6.難以控制翻譯質(zhì)量:每個(gè)單詞都有多種翻譯,并且典型的 MT 系統(tǒng)對(duì)源句的翻譯好于lattice of possible translations。為了保持后者的大小合理,我們使用集束搜索 (beam search)。通過(guò)改變波束的寬度,來(lái)找到低概率但正確的翻譯。而對(duì)于 NMT 系統(tǒng),調(diào)整集束尺寸似乎沒(méi)有任何不利影響。
當(dāng)你擁有大量數(shù)據(jù)時(shí),NMT 系統(tǒng)的翻譯性能依然還是難以被擊敗的,而且它們?nèi)匀辉诖罅康乇皇褂谩jP(guān)于通常我們所說(shuō)的神經(jīng)網(wǎng)絡(luò)模型的黑盒性,也有待進(jìn)一步說(shuō)明,如今的 NMT 模型 (基于 LSTM 和 Transformer 模型) 也都受此影響。
-
Google
+關(guān)注
關(guān)注
5文章
1789瀏覽量
58889 -
翻譯
+關(guān)注
關(guān)注
0文章
47瀏覽量
10988
原文標(biāo)題:輸出不詳宗教預(yù)言,Google翻譯為何“水逆”了?
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Google Fast Pair服務(wù)簡(jiǎn)介
手動(dòng)添加cubeMX的軟件自動(dòng)生成代碼后,編譯出現(xiàn)’rtthread.elf’:No Such File 的錯(cuò)誤怎么解決?
瑞薩RA單片機(jī)在e2 studio環(huán)境下printf編譯出錯(cuò)的問(wèn)題解析
數(shù)字電路—12、譯碼器
如何開發(fā)一款Google Find My Tag?
AI助力實(shí)時(shí)翻譯耳機(jī)

Google Play如何幫助您的應(yīng)用變現(xiàn)

Google Cloud發(fā)布兩款針對(duì)企業(yè)客戶的全新解決方案
LLMWorld上線代碼翻譯新工具——問(wèn)丫·碼語(yǔ)翻譯俠,快來(lái)體驗(yàn)!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論