") 深入探討增強(qiáng)學(xué)習(xí)如何在無人駕駛中發(fā)揮作用
深入探討增強(qiáng)學(xué)習(xí)如何在無人駕駛中發(fā)揮作用

本文著重介紹增強(qiáng)學(xué)習(xí)在無人駕駛中的應(yīng)用。增強(qiáng)學(xué)習(xí)的目的是通過和環(huán)境交互,學(xué)習(xí)如何在相應(yīng)觀測(cè)中采取最優(yōu)行為。相比傳統(tǒng)的機(jī)器學(xué)習(xí),它有以下優(yōu)勢(shì):首先,由于不需要標(biāo)注的過程,可以更有效地解決環(huán)境中存在的特殊情況。其次,可以把整個(gè)系統(tǒng)作為一個(gè)整體,從而對(duì)其中的一些模塊更加魯棒。最后,增強(qiáng)學(xué)習(xí)可以比較容易地學(xué)習(xí)到一系列行為。這些特性十分適用于自動(dòng)駕駛決策過程,我們?cè)诒疚纳钊胩接懺鰪?qiáng)學(xué)習(xí)如何在無人駕駛決策過程中發(fā)揮作用。
增強(qiáng)學(xué)習(xí)簡(jiǎn)介
增強(qiáng)學(xué)習(xí)是最近幾年中機(jī)器學(xué)習(xí)領(lǐng)域的最新進(jìn)展。增強(qiáng)學(xué)習(xí)的目的是通過和環(huán)境交互學(xué)習(xí)到如何在相應(yīng)的觀測(cè)中采取最優(yōu)行為。行為的好壞可以通過環(huán)境給的獎(jiǎng)勵(lì)來確定。不同的環(huán)境有不同的觀測(cè)和獎(jiǎng)勵(lì)。例如,駕駛中環(huán)境觀測(cè)是攝像頭和激光雷達(dá)采集到的周圍環(huán)境的圖像和點(diǎn)云,以及其他的傳感器的輸出,例如行駛速度、GPS定位、行駛方向。駕駛中的環(huán)境的獎(jiǎng)勵(lì)根據(jù)任務(wù)的不同,可以通過到達(dá)終點(diǎn)的速度、舒適度和安全性等指標(biāo)確定。
增強(qiáng)學(xué)習(xí)和傳統(tǒng)機(jī)器學(xué)習(xí)的最大區(qū)別是增強(qiáng)學(xué)習(xí)是一個(gè)閉環(huán)學(xué)習(xí)的系統(tǒng),增強(qiáng)學(xué)習(xí)算法選取的行為會(huì)直接影響到環(huán)境,進(jìn)而影響到該算法之后從環(huán)境中得到的觀測(cè)。傳統(tǒng)的機(jī)器學(xué)習(xí)通過把收集訓(xùn)練數(shù)據(jù)和模型學(xué)習(xí)作為兩個(gè)獨(dú)立的過程。例如,如果我們需要學(xué)習(xí)一個(gè)人臉分類的模型。傳統(tǒng)機(jī)器學(xué)習(xí)方法首先需要雇傭標(biāo)注者標(biāo)注一批人臉圖像數(shù)據(jù),然后在這些數(shù)據(jù)中學(xué)習(xí)模型,最后我們可以把訓(xùn)練出來的人臉識(shí)別模型在現(xiàn)實(shí)的應(yīng)用中進(jìn)行測(cè)試。 如果發(fā)現(xiàn)測(cè)試結(jié)果不理想,那么我們需要分析模型中存在問題,并且試著從數(shù)據(jù)收集或者模型訓(xùn)練中尋找原因,然后從這些步驟中解決這些問題。對(duì)于同樣的問題,增強(qiáng)學(xué)習(xí)采用的方法是通過在人臉識(shí)別的系統(tǒng)中嘗試進(jìn)行預(yù)測(cè),并且通過用戶反饋的滿意程度來調(diào)整自己的預(yù)測(cè),從而統(tǒng)一收集訓(xùn)練數(shù)據(jù)和模型學(xué)習(xí)的過程。增強(qiáng)學(xué)習(xí)和環(huán)境交互過程的框圖如圖1所示。
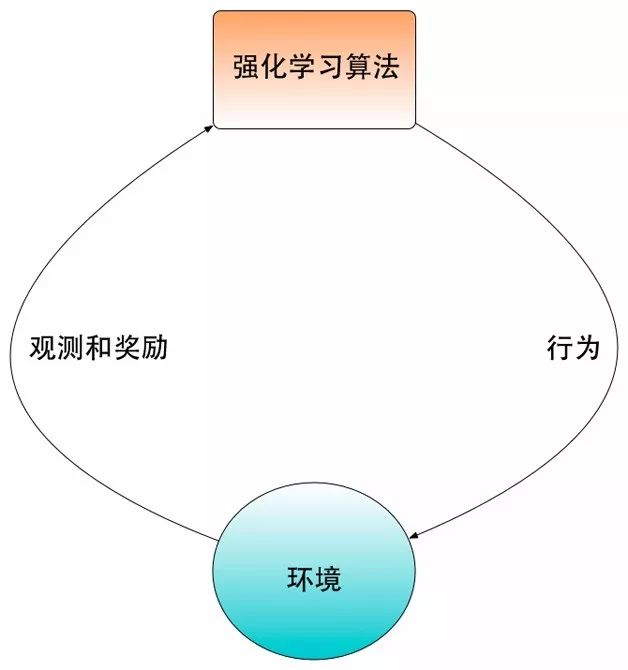
圖1 增強(qiáng)學(xué)習(xí)和環(huán)境交互的框圖
增強(qiáng)學(xué)習(xí)存在著很多傳統(tǒng)機(jī)器學(xué)習(xí)所不具備的挑戰(zhàn)。首先,因?yàn)樵谠鰪?qiáng)學(xué)習(xí)中沒有確定在每一時(shí)刻應(yīng)該采取哪個(gè)行為的信息,增強(qiáng)學(xué)習(xí)算法必須通過探索各種可能的行為才能判斷出最優(yōu)的行為。如何有效地在可能行為數(shù)量較多的情況下有效探索,是增強(qiáng)學(xué)習(xí)中最重要的問題之一。其次,在增強(qiáng)學(xué)習(xí)中一個(gè)行為不僅可能會(huì)影響當(dāng)前時(shí)刻的獎(jiǎng)勵(lì),而且還可能會(huì)影響之后所有時(shí)刻的獎(jiǎng)勵(lì)。在最壞的情況下,一個(gè)好行為不會(huì)在當(dāng)前時(shí)刻獲得獎(jiǎng)勵(lì),而會(huì)在很多步都執(zhí)行正確后才能得到獎(jiǎng)勵(lì)。在這種情況下,增強(qiáng)學(xué)習(xí)需要判斷出獎(jiǎng)勵(lì)和很多步之前的行為有關(guān)非常有難度。
雖然增強(qiáng)學(xué)習(xí)存在很多挑戰(zhàn),它也能夠解決很多傳統(tǒng)的機(jī)器學(xué)習(xí)不能解決的問題。首先,由于不需要標(biāo)注的過程, 增強(qiáng)學(xué)習(xí)可以更有效地解決環(huán)境中所存在著的特殊情況。比如,無人車環(huán)境中可能會(huì)出現(xiàn)行人和動(dòng)物亂穿馬路的特殊情況。只要我們的模擬器能夠模擬出這些特殊情況,增強(qiáng)學(xué)習(xí)就可以學(xué)習(xí)到怎么在這些特殊情況中做出正確的行為。其次,增強(qiáng)學(xué)習(xí)可以把整個(gè)系統(tǒng)作為一個(gè)整體的系統(tǒng),從而對(duì)其中的一些模塊更加魯棒。例如,自動(dòng)駕駛中的感知模塊不可能做到完全可靠。前一段時(shí)間,Tesla無人駕駛的事故就是因?yàn)樵趶?qiáng)光環(huán)境中感知模塊失效導(dǎo)致的。增強(qiáng)學(xué)習(xí)可以做到,即使在某些模塊失效的情況下也能做出穩(wěn)妥的行為。最后,增強(qiáng)學(xué)習(xí)可以比較容易學(xué)習(xí)到一系列行為。自動(dòng)駕駛中需要執(zhí)行一系列正確的行為才能成功的駕駛。如果只有標(biāo)注數(shù)據(jù),學(xué)習(xí)到的模型如果每個(gè)時(shí)刻偏移了一點(diǎn),到最后可能就會(huì)偏移非常多,產(chǎn)生毀滅性的后果。而增強(qiáng)學(xué)習(xí)能夠?qū)W會(huì)自動(dòng)修正偏移。
綜上所述,增強(qiáng)學(xué)習(xí)在自動(dòng)駕駛中有廣闊的前景。本文會(huì)介紹增強(qiáng)學(xué)習(xí)的常用算法以及其在自動(dòng)駕駛中的應(yīng)用。希望能夠激發(fā)這個(gè)領(lǐng)域的探索性工作。
增強(qiáng)學(xué)習(xí)算法
增強(qiáng)學(xué)習(xí)中的每個(gè)時(shí)刻t∈{0,1,2,…}中,我們的算法和環(huán)境通過執(zhí)行行為at進(jìn)行交互,可以得到觀測(cè)st和獎(jiǎng)勵(lì)rt。一般情況中,我們假設(shè)環(huán)境是存在馬爾科夫性質(zhì)的,即環(huán)境的變化完全可以通過狀態(tài)轉(zhuǎn)移概率Pass′=Pr{st+1=s′|st=s,at=a}刻畫出來。也就是說,環(huán)境的下一時(shí)刻觀測(cè)只和當(dāng)前時(shí)刻的觀測(cè)和行為有關(guān),和之前所有時(shí)刻的觀測(cè)和行為都沒有關(guān)系。而環(huán)境在t+1時(shí)刻返回的獎(jiǎng)勵(lì)在當(dāng)前狀態(tài)和行為確定下的期望可以表示為:Ras=E{rt+1|st=s,at=a}. 增強(qiáng)學(xué)習(xí)算法在每一個(gè)時(shí)刻執(zhí)行行為的策略可以通過概率π(s,a,θ)=Pr{at=a|st=s;θ}來表示。其中θ是需要學(xué)習(xí)的策略參數(shù)。我們需要學(xué)習(xí)到最優(yōu)的增強(qiáng)學(xué)習(xí)策略,也就是學(xué)習(xí)到能夠取得最高獎(jiǎng)勵(lì)的策略。
ρ(π)=E{∑t=1∞γt?1rt|s0,π (1)
其中γ是增強(qiáng)學(xué)習(xí)中的折扣系數(shù),用來表示在之后時(shí)刻得到的獎(jiǎng)勵(lì)折扣。同樣的獎(jiǎng)勵(lì),獲得的時(shí)刻越早,增強(qiáng)學(xué)習(xí)系統(tǒng)所感受到的獎(jiǎng)勵(lì)越高。
同時(shí),我們可以按照如下方式定義Q函數(shù)。Q函數(shù)Qpi(s,a)表示的是在狀態(tài)為s,執(zhí)行行為a之后的時(shí)刻都使用策略π選擇行為能夠得到的獎(jiǎng)勵(lì)。我們能夠?qū)W習(xí)到準(zhǔn)確的Q函數(shù),那么使Q函數(shù)最高的行為就是最優(yōu)行為。
Qπ(s,a)=E{∑k=1∞γk?1rr+k|st=s,at=a,π}=Es′[r+γQpi(s′,a′)|s,a,π] (2)
增強(qiáng)學(xué)習(xí)的目的,就是在給定的任意環(huán)境,通過對(duì)環(huán)境進(jìn)行探索學(xué)習(xí)到最佳的策略函數(shù)π最大化rho(π)。下面的章節(jié)中我們會(huì)簡(jiǎn)單介紹常用的增強(qiáng)學(xué)習(xí)算法。包括REINFORCE算法和Deep Q-learning算法。
REINFORCE算法
REINFORCE是最簡(jiǎn)單的reinforcement learning算法。其基本思想是通過在環(huán)境里面執(zhí)行當(dāng)前的策略直到一個(gè)回合結(jié)束(比如游戲結(jié)束),根據(jù)得到的獎(jiǎng)勵(lì)可以計(jì)算出當(dāng)前策略的梯度。我們可以用這個(gè)梯度更新當(dāng)前的策略得到新策略。在下面的回合,我們?cè)儆眯碌牟呗灾貜?fù)這個(gè)過程,一直到計(jì)算出的梯度足夠小為止。最后得到的策略就是最優(yōu)策略。
假設(shè)我們當(dāng)前的策略概率是πθ(x)=Pr{at=a|st=s;θ} (θ是策略參數(shù))。每個(gè)回合,算法實(shí)際執(zhí)行的行為at是按照概率π(x)采樣所得到的。算法在當(dāng)前回合時(shí)刻t獲得的獎(jiǎng)勵(lì)用rt表示。那么,策略梯度可以通過以下的公式計(jì)算。
?θρ(π)=∑t=1T▽?duì)萳ogπ(at|st;θ)Rt (3)
其中π(at|st;θ)是策略在觀測(cè)到st時(shí)選擇at的概率。Rt=∑Tt′=tγt′-trt′是算法在采取了當(dāng)前策略之后所獲得的總的折扣后的獎(jiǎng)勵(lì)。為了減少預(yù)測(cè)出梯度的方差。我們一般會(huì)使用(Rt-bt)來代替Rt。bt一般等于Eπ[Rt],也就是當(dāng)前t時(shí)刻的環(huán)境下使用策略π之后能獲得的折扣后獎(jiǎng)勵(lì)的期望。
計(jì)算出方差之后,我們可以使用θ=θ+▽?duì)圈?π)更新參數(shù)得到新的策略。
REINFORCE的核心思想是通過從環(huán)境中獲得的獎(jiǎng)勵(lì)判斷執(zhí)行行為的好壞。如果一個(gè)行為執(zhí)行之后獲得的獎(jiǎng)勵(lì)比較高,那么算出的梯度也會(huì)比較高,這樣在更新后的策略中該行為被采樣到的概率也會(huì)比較高。反之,對(duì)于執(zhí)行之后獲得獎(jiǎng)勵(lì)比較低的行為,因?yàn)橛?jì)算出的梯度低,更新后的策略中該行為被采樣到的概率也會(huì)比較低。通過在這個(gè)環(huán)境中反復(fù)執(zhí)行各種行為,REIFORCE可以大致準(zhǔn)確地估計(jì)出各個(gè)行為的正確梯度,從而對(duì)策略中各個(gè)行為的采樣概率做出相應(yīng)調(diào)整。
作為最簡(jiǎn)單的采樣算法,REINFORCE得到了廣泛應(yīng)用,例如學(xué)習(xí)視覺的注意力機(jī)制和學(xué)習(xí)序列模型的預(yù)測(cè)策略都用到了REINFORCE算法。事實(shí)證明,在模型相對(duì)簡(jiǎn)單,環(huán)境隨機(jī)性不強(qiáng)的環(huán)境下,REINFORCE算法可以達(dá)到很好的效果。
但是,REINFORCE算法也存在著它的問題。首先,REINFORCE算法中,執(zhí)行了一個(gè)行為之后的所有獎(jiǎng)勵(lì)都被認(rèn)為是因?yàn)檫@個(gè)行為產(chǎn)生的,這顯然不合理。雖然在執(zhí)行了策略足夠多的次數(shù)然后對(duì)計(jì)算出的梯度進(jìn)行平均之后,REINFORCE以很大概率計(jì)算出正確的梯度。但是在實(shí)際實(shí)現(xiàn)中,處于效率考慮,同一個(gè)策略在更新之前不可能在環(huán)境中執(zhí)行太多次。在這種情況下,REINFORCE計(jì)算出的梯度有可能會(huì)有比較大的誤差。其次,REINFROCE算法有可能會(huì)收斂到一個(gè)局部最優(yōu)點(diǎn)。如果我們已經(jīng)學(xué)到了一個(gè)策略,這個(gè)策略中大部分的行為都以近似1的概率采樣到。那么,即使這個(gè)策略不是最優(yōu)的,REINFORCE算法也很難學(xué)習(xí)到如何改進(jìn)這個(gè)策略。因?yàn)槲覀兺耆珱]有執(zhí)行其他采樣概率為0的行為,無法知道這些行為的好壞。最后,REINFORCE算法之后在環(huán)境存在回合的概念的時(shí)候才能夠使用。如果不存在環(huán)境的概念,REINFORCE算法也無法使用。
最近,DeepMind提出了使用Deep Q-learning算法學(xué)習(xí)策略,克服了REINFORCE算法的缺點(diǎn),在Atari游戲?qū)W習(xí)這樣的復(fù)雜的任務(wù)中取得了令人驚喜的效果。
Deep Q-learning
Deep Q-learning是一種基于Q函數(shù)的增強(qiáng)學(xué)習(xí)算法。該算法對(duì)于復(fù)雜的每步行為之間存在較強(qiáng)的相關(guān)性環(huán)境有很好的效果。Deep Q-learning學(xué)習(xí)算法的基礎(chǔ)是Bellman公式。我們?cè)谇懊娴恼鹿?jié)已經(jīng)介紹了Q函數(shù)的定義,如下所示。
Qpi(s,a)=E{∑k=1∞γk-1rr+k|st=s,at=a,π}=Es’[r+γQpi(s’,a’)|s,a,π] (4)
如果我們學(xué)習(xí)到了最優(yōu)行為對(duì)應(yīng)的Q函數(shù)Q*(s,a),那么這個(gè)函數(shù)應(yīng)該滿足下面的Bellman公式。
Q*(s,a)=Es’[r+γmaxa’Q*(s,a)|s,a] (5)
另外,如果學(xué)習(xí)到了最優(yōu)行為對(duì)應(yīng)的Q函數(shù)Q*(s,a),那么我們?cè)诿恳粫r(shí)刻得到了觀察st之后,選擇使得Q*(s,a)最高的行為做為執(zhí)行的行為at。
我們可以用一個(gè)神經(jīng)網(wǎng)絡(luò)來計(jì)算Q函數(shù),用Q(s,a;w)來表示。其中w是神經(jīng)網(wǎng)絡(luò)的參數(shù)。我們希望學(xué)習(xí)出來的Q函數(shù)滿足Bellman公式。因此可以定義下面的損失函數(shù)。這個(gè)函數(shù)的Bellman公式的L2誤差如下。
L(w)=E[(r+γmaxa’Q*(s’,a’;w)-Q(s,a;w))2](6)
其中r是在s的觀測(cè)執(zhí)行行為a后得到的獎(jiǎng)勵(lì),s′是執(zhí)行行為a之后下一個(gè)時(shí)刻的觀測(cè)。這個(gè)公式的前半部分r+γmaxa′Q*(s′,a′,w)也被稱為目標(biāo)函數(shù)。我們希望預(yù)測(cè)出的Q函數(shù)能夠和通過這個(gè)時(shí)刻得到的獎(jiǎng)勵(lì)及下個(gè)時(shí)刻狀態(tài)得到的目標(biāo)函數(shù)盡可能接近。通過這個(gè)損失函數(shù),我們可以計(jì)算出如下梯度。
?L(w)?w=E[(r+γmaxa’Q*(s’,a’;w)-Q(s,a;w))?Q(s,a;w?w) (7)
可以通過計(jì)算出的梯度,使用梯度下降算法更新參數(shù)w。
使用深度神經(jīng)網(wǎng)絡(luò)來逼近Q函數(shù)存在很多問題。首先,在一個(gè)回合內(nèi)采集到的各個(gè)時(shí)刻的數(shù)據(jù)是存在著相關(guān)性的。因此,如果我們使用了一個(gè)回合內(nèi)的全部數(shù)據(jù),那么我們計(jì)算出的梯度是有偏的。其次,由于取出使Q函數(shù)最大的行為這個(gè)操作是離散的,即使Q函數(shù)變化很小,我們所得到的行為也可能差別很大。這個(gè)問題會(huì)導(dǎo)致訓(xùn)練時(shí)策略出現(xiàn)震蕩。最后,Q函數(shù)的動(dòng)態(tài)范圍有可能會(huì)很大,并且我們很難預(yù)先知道Q函數(shù)的動(dòng)態(tài)范圍。因?yàn)椋覀儗?duì)一個(gè)環(huán)境沒有足夠的了解的時(shí)候,很難計(jì)算出這個(gè)環(huán)境中可能得到的最大獎(jiǎng)勵(lì)。這個(gè)問題會(huì)使Q-learning工程梯度可能會(huì)很大,導(dǎo)致訓(xùn)練不穩(wěn)定。
首先,Deep Q-learning算法使用了經(jīng)驗(yàn)回放算法。其基本思想是記住算法在這個(gè)環(huán)境中執(zhí)行的歷史信息。這個(gè)過程和人類的學(xué)習(xí)過程類似。人類在學(xué)習(xí)執(zhí)行行為的策略時(shí),不會(huì)只通過當(dāng)前執(zhí)行的策略結(jié)果進(jìn)行學(xué)習(xí),而還會(huì)利用之前的歷史執(zhí)行策略經(jīng)驗(yàn)進(jìn)行學(xué)習(xí)。因此,經(jīng)驗(yàn)回放算法將之前算法在一個(gè)環(huán)境中的所有經(jīng)驗(yàn)都存放起來。在學(xué)習(xí)的時(shí)候,可以從經(jīng)驗(yàn)中采樣出一定數(shù)量的跳轉(zhuǎn)信息(st,at,rt+1,st+1),也就是當(dāng)處于環(huán)境,然后利用這些信息計(jì)算出梯度學(xué)習(xí)模型。因?yàn)椴煌奶D(zhuǎn)信息是從不同回合中采樣出來的,所以它們之間不存在強(qiáng)相關(guān)性。這個(gè)采樣過程還可以解決同一個(gè)回合中的各個(gè)時(shí)刻的數(shù)據(jù)相關(guān)性問題。
而且,Deep Q-learning算法使用了目標(biāo)Q網(wǎng)絡(luò)來解決學(xué)習(xí)過程中的震蕩問題。我們可以定義一個(gè)目標(biāo)Q網(wǎng)絡(luò)Q(s,a;w-)。這個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)和用來執(zhí)行的Q網(wǎng)絡(luò)結(jié)構(gòu)完全相同,唯一不同就是使用的參數(shù)w-。我們的目標(biāo)函數(shù)可以通過目標(biāo)Q網(wǎng)絡(luò)計(jì)算。
r+γmaxa’Q*(s’,a’;w-) (8)
目標(biāo)Q網(wǎng)絡(luò)參數(shù)在很長(zhǎng)時(shí)間內(nèi)保持不變,每當(dāng)在Q網(wǎng)絡(luò)學(xué)習(xí)了一定時(shí)間之后,可以Q網(wǎng)絡(luò)的參數(shù)w替換目標(biāo)Q網(wǎng)絡(luò)的參數(shù)w-。這樣目標(biāo)函數(shù)在很長(zhǎng)的時(shí)間里保持穩(wěn)定。可以解決學(xué)習(xí)過程中的震蕩問題。
最后,為了防止Q函數(shù)的值太大導(dǎo)致梯度不穩(wěn)定。Deep Q-learning的算法對(duì)獎(jiǎng)勵(lì)設(shè)置了最大和最小值(一般設(shè)置為[-1, +1])。我們會(huì)把所有獎(jiǎng)勵(lì)縮放到這個(gè)范圍。這樣算法計(jì)算出的梯度更加穩(wěn)定。
Q-learning算法的框圖如圖2所示。
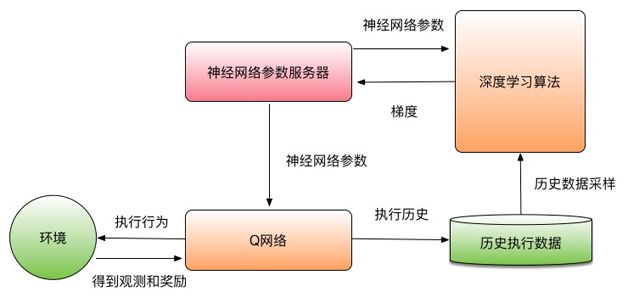
圖2 Q-learning算法框圖
因?yàn)槭褂昧松疃壬窠?jīng)網(wǎng)絡(luò)來學(xué)習(xí)Q函數(shù),Deep Q-learning算可以直接以圖像作為輸入學(xué)習(xí)復(fù)雜的策略。其中一個(gè)例子是學(xué)習(xí)Atari游戲。這是計(jì)算機(jī)游戲的早期形式,一般圖像比較粗糙,但要玩好需要對(duì)圖像進(jìn)行理解,并且執(zhí)行復(fù)雜的策略,例如躲避,發(fā)射子彈,走迷宮等。一些Atari游戲的例子如圖3所示,其中包含了一個(gè)簡(jiǎn)單的賽車游戲。
Deep Q-learning算法在沒有任何額外知識(shí)的情況下,完全以圖像和獲得的獎(jiǎng)勵(lì)進(jìn)行輸入。在大部分Atari游戲中都大大超過了人類性能。這是深度學(xué)習(xí)或者增強(qiáng)學(xué)習(xí)出現(xiàn)前完全不可能完成的任務(wù)。Atari游戲是第一個(gè)Deep Q-learning解決了用其他算法都無法解決的問題,充分顯示了將深度學(xué)習(xí)和增強(qiáng)學(xué)習(xí)結(jié)合的優(yōu)越性和前景。
使用增強(qiáng)學(xué)習(xí)幫助決策
現(xiàn)有的深度增強(qiáng)學(xué)習(xí)解決的問題中,我們執(zhí)行的行為一般只對(duì)環(huán)境有短期影響。例如,在Atari賽車游戲中,我們只需要控制賽車的方向和速度讓賽車沿著跑道行駛,并且躲避其他賽車就可以獲得最優(yōu)的策略。但是對(duì)于更復(fù)雜決策的情景,我們無法只通過短期獎(jiǎng)勵(lì)得到最優(yōu)策略。一個(gè)典型的例子是走迷宮。在走迷宮這個(gè)任務(wù)中,判斷一個(gè)行為是否是最優(yōu)無法從短期的獎(jiǎng)勵(lì)來得到。只有當(dāng)走到終點(diǎn)時(shí),才能得到獎(jiǎng)勵(lì)。在這種情況下,直接學(xué)習(xí)出正確的Q函數(shù)非常困難。我們只有把基于搜索的和基于增強(qiáng)學(xué)習(xí)的算法結(jié)合,才能有效解決這類問題。
基于搜索算法一般是通過搜索樹來實(shí)現(xiàn)的。搜索樹既可以解決一個(gè)玩家在環(huán)境中探索的問題(例如走迷宮),也可以解決多個(gè)玩家競(jìng)爭(zhēng)的問題(例如圍棋)。我們以圍棋為例,講解搜索樹的基本概念。圍棋游戲有兩個(gè)玩家,分別由白子和黑子代表。圍棋棋盤中線的交叉點(diǎn)是可以下子的地方。兩個(gè)玩家分別在棋盤下白子和黑子。一旦一片白子或黑子被相反顏色的子包圍,那么這片子就會(huì)被提掉,重新成為空白的區(qū)域。游戲的最后,所有的空白區(qū)域都被占領(lǐng)或是包圍。占領(lǐng)和包圍區(qū)域比較大的一方獲勝。
在圍棋這個(gè)游戲中,我們從環(huán)境中得到的觀測(cè)st是棋盤的狀態(tài),也就是白子和黑子的分布。我們執(zhí)行的行為是所下白子或者黑子的位置。而我們最后得到的獎(jiǎng)勵(lì)可以根據(jù)游戲是否取勝得到。取勝的一方+1,失敗的一方-1。游戲進(jìn)程可以通過如下搜索樹來表示:搜索樹中的每個(gè)節(jié)點(diǎn)對(duì)應(yīng)著一種棋盤狀態(tài),每一條邊對(duì)應(yīng)著一個(gè)可能的行為。在如圖4所示的搜索樹中,黑棋先行,樹的根節(jié)點(diǎn)對(duì)應(yīng)著棋盤的初始狀態(tài)s0。a1和a2對(duì)應(yīng)著黑棋兩種可能的下子位置(實(shí)際的圍棋中,可能的行為遠(yuǎn)比兩種多)。每個(gè)行為ai對(duì)應(yīng)著一個(gè)新的棋盤的狀態(tài)si1。接下來該白棋走,白棋同樣有兩種走法b1和b2,對(duì)于每個(gè)棋盤的狀態(tài)si1,兩種不同的走法又會(huì)生成兩種不同狀態(tài)。如此往復(fù),一直到游戲結(jié)束,我們就可以在葉子節(jié)點(diǎn)中獲得游戲結(jié)束時(shí)黑棋獲得的獎(jiǎng)勵(lì)。我們可以通過這些獎(jiǎng)勵(lì)獲得最佳的狀態(tài)。
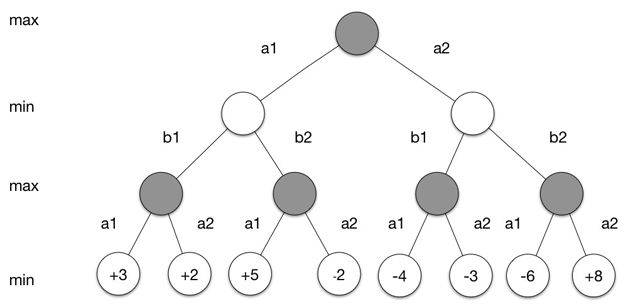
圖4 搜索樹的例子
通過這個(gè)搜索樹,如果給定黑棋和白棋的策略π=[π1,π2],我們可以定義黑棋的值函數(shù)為黑棋在雙方分別執(zhí)行策略π1和π2時(shí),最后黑棋能獲得獎(jiǎng)勵(lì)的期望。
vπ(s)=Eπ[Gt|St=s] (9)
黑棋需要尋找的最優(yōu)策略需要最優(yōu)化最壞的情況下,黑棋所能得到的獎(jiǎng)勵(lì)。我們定義這個(gè)值函數(shù)為最小最大值函數(shù)。黑棋的最優(yōu)策略就是能夠達(dá)到這個(gè)值函數(shù)的策略π1。
v*(s)=maxπ1minπ2vπ(s) (10)
如果我們能夠窮舉搜索樹的每個(gè)節(jié)點(diǎn),那么我們可以很容易地用遞歸方式計(jì)算出最小最大值函數(shù)和黑棋的最優(yōu)策略。但在實(shí)際的圍棋中,每一步黑棋和白棋可以采用的行為個(gè)數(shù)非常多,而搜索樹的節(jié)點(diǎn)數(shù)目隨著樹的深度指數(shù)增長(zhǎng)。因此,我們無法枚舉所有節(jié)點(diǎn)計(jì)算出準(zhǔn)確的最小最大值函數(shù),而只能通過學(xué)習(xí)v(s;w)~v*(s)作為近似最小最大值函數(shù)。我們可以通過兩種方法使用這個(gè)近似函數(shù)。首先,我們可以使用這個(gè)近似函數(shù)確定搜索的優(yōu)先級(jí)。對(duì)于一個(gè)節(jié)點(diǎn),白棋或者黑棋可能有多種走法,我們應(yīng)該優(yōu)先搜索產(chǎn)生最小最大值函數(shù)比較高節(jié)點(diǎn)的行為,因?yàn)樵趯?shí)際游戲中,真實(shí)玩家一般會(huì)選擇這些相對(duì)比較好的行為。其次,我們可以使用這個(gè)近似函數(shù)來估計(jì)非葉子節(jié)點(diǎn)的最小最大值。如果這些節(jié)點(diǎn)的最小最大值非常低,那么這些節(jié)點(diǎn)幾乎不可能對(duì)應(yīng)著最優(yōu)策略。我們?cè)偎阉鞯臅r(shí)候也不用考慮這些節(jié)點(diǎn)。
因此主要問題是如何學(xué)習(xí)到近似最小最大值函數(shù)v(s;w)。我們可以使用兩個(gè)學(xué)習(xí)到的圍棋算法自己和自己玩圍棋游戲。然后通過增強(qiáng)學(xué)習(xí)算法更新近似最小最大值函數(shù)的參數(shù)w。在玩完了一局游戲之后,我們可以使用類似REINFORCE算法的更新方式:
▽w=α(Gt-v(st;w))▽wv(st;w) (11)
在這個(gè)式子中Gt表示的是在t時(shí)刻之后獲得的獎(jiǎng)勵(lì)。因?yàn)樵趪暹@個(gè)游戲中,我們只在最后時(shí)刻獲得獎(jiǎng)勵(lì)。所以Gt對(duì)應(yīng)的是最后獲得的獎(jiǎng)勵(lì)。我們也可以使用類似Q-learning的方式用TD誤差來更新參數(shù)。
▽w=α(v(st+1;w)-v(st;w))▽wv(st;w)(12)
因?yàn)閲暹@個(gè)游戲中,我們只在最后時(shí)刻獲得獎(jiǎng)勵(lì)。一般使用REINFORCE算法的更新方式效果比較好。在學(xué)習(xí)出一個(gè)好的近似最小最大值函數(shù)之后,可以大大加快搜索效率。這和人學(xué)習(xí)圍棋的過程類似,人在學(xué)習(xí)圍棋的過程中,會(huì)對(duì)特定的棋行形成感覺,能一眼就判斷出棋行的好壞,而不用對(duì)棋的發(fā)展進(jìn)行推理。這就是通過學(xué)習(xí)近似最小最大值函數(shù)加速搜索的過程。
通過學(xué)習(xí)近似最小最大值函數(shù),Google DeepMind在圍棋領(lǐng)域取得了突飛猛進(jìn)。在今年三月進(jìn)行的比賽中,AlphaGo以四比一戰(zhàn)勝了圍棋世界冠軍李世石。AlphaGo的核心算法就是通過歷史棋局和自己對(duì)弈學(xué)習(xí)近似最小最大值函數(shù)。AlphaGo的成功充分的顯示了增強(qiáng)學(xué)習(xí)和搜索結(jié)合在需要長(zhǎng)期規(guī)劃問題上的潛力。不過,需要注意的是,現(xiàn)有將增強(qiáng)學(xué)習(xí)和搜索結(jié)合的算法只能用于確定性的環(huán)境中。確定性的環(huán)境中給定一個(gè)觀測(cè)和一個(gè)行為,下一個(gè)觀測(cè)是確定的,并且這個(gè)轉(zhuǎn)移函數(shù)是已知的。在環(huán)境非確定,并且轉(zhuǎn)移函數(shù)未知的情況下,如何把增強(qiáng)學(xué)習(xí)和搜索結(jié)合還是增強(qiáng)學(xué)習(xí)領(lǐng)域中沒有解決的問題。
自動(dòng)駕駛的決策介紹
自動(dòng)駕駛的人工智能包含了感知、決策和控制三個(gè)方面。感知指的是如何通過攝像頭和其他傳感器輸入解析出周圍環(huán)境的信息,例如有哪些障礙物,障礙物的速度和距離,道路的寬度和曲率等。這個(gè)部分是自動(dòng)駕駛的基礎(chǔ),是當(dāng)前自動(dòng)駕駛研究的重要方向,在前文我們已經(jīng)有講解。控制是指當(dāng)我們有了一個(gè)目標(biāo),例如右轉(zhuǎn)30度,如何通過調(diào)整汽車的機(jī)械參數(shù)達(dá)到這個(gè)目標(biāo)。這個(gè)部分已經(jīng)有相對(duì)比較成熟的算法能夠解決,不在本文的討論范圍之內(nèi)。本節(jié),我們著重講解自動(dòng)駕駛的決策部分。
自動(dòng)駕駛的決策是指給定感知模塊解析出的環(huán)境信息如何控制汽車的行為來達(dá)到駕駛目標(biāo)。例如,汽車加速、減速、左轉(zhuǎn)、右轉(zhuǎn)、換道、超車都是決策模塊的輸出。決策模塊不僅需要考慮到汽車的安全和舒適性,保證盡快到達(dá)目標(biāo)地點(diǎn),還需要在旁邊車輛惡意駕駛的情況下保證乘客安全。因此,決策模塊一方面需要對(duì)行車計(jì)劃進(jìn)行長(zhǎng)期規(guī)劃,另一方面還需要對(duì)周圍車輛和行人的行為進(jìn)行預(yù)測(cè)。而且,自動(dòng)駕駛中的決策模塊對(duì)安全和可靠性有著嚴(yán)格要求。現(xiàn)有自動(dòng)駕駛的決策模塊一般根據(jù)規(guī)則構(gòu)建,雖然可以應(yīng)付大部分駕駛情況,對(duì)于駕駛中可能出現(xiàn)的各種突發(fā)情況,基于規(guī)則的決策系統(tǒng)不可能枚舉到所有突發(fā)情況。我們需要一種自適應(yīng)系統(tǒng)來應(yīng)對(duì)駕駛環(huán)境中出現(xiàn)的各種突發(fā)情況。
現(xiàn)有自動(dòng)駕駛的決策系統(tǒng)大部分基于規(guī)則,該系統(tǒng)大部分可以用有限狀態(tài)機(jī)表示。例如,自動(dòng)駕駛的高層行為可以分為向左換道、向右換道、跟隨、緊急停車。決策系統(tǒng)根據(jù)目標(biāo)可以決定執(zhí)行高層行為。根據(jù)需要執(zhí)行的高層行為,決策系統(tǒng)可以用相應(yīng)的規(guī)則生成出底層行為。基于規(guī)則決策系統(tǒng)的主要缺點(diǎn)是缺乏靈活性。對(duì)于所有的突發(fā)情況,都需要寫一個(gè)決策。這種方式很難對(duì)所有的突發(fā)系統(tǒng)面面俱到。
自動(dòng)駕駛模擬器
自動(dòng)駕駛的決策過程中,模擬器起著非常重要的作用。決策模擬器負(fù)責(zé)對(duì)環(huán)境中常見的場(chǎng)景進(jìn)行模擬,例如車道情況、路面情況、障礙物分布和行為、天氣等。同時(shí)還可以將真實(shí)場(chǎng)景中采集到的數(shù)據(jù)進(jìn)行回放。決策模擬器的接口和真車的接口保持一致,這樣可以保證在真車上使用的決策算法可以直接在模擬器上運(yùn)行。除了決策模擬器之外,自動(dòng)駕駛的模擬器還包含了感知模擬器和控制模擬器,用來驗(yàn)證感知和控制模塊。
自動(dòng)駕駛模擬器的第一個(gè)重要功能是驗(yàn)證。在迭代決策算法的過程中,我們需要比較容易地衡量算法性能。比如,需要確保新決策算法在之前能夠正確運(yùn)行和常見的場(chǎng)景都能夠安全運(yùn)行。我們還需要根據(jù)新決策算法對(duì)常見場(chǎng)景的安全性、快捷性、舒適性打分。我們不可能每次在更新算法時(shí)都在實(shí)際場(chǎng)景中測(cè)試,這時(shí)有一個(gè)能可靠反映真實(shí)場(chǎng)景的無人駕駛模擬器是非常重要的。
模擬器的另一個(gè)重要的功能是進(jìn)行增強(qiáng)學(xué)習(xí)。可以模擬出各種突發(fā)情況,然后增強(qiáng)學(xué)習(xí)算法利用其在這些突發(fā)情況中獲得的獎(jiǎng)勵(lì),學(xué)習(xí)如何應(yīng)對(duì)。這樣,只要能夠模擬出足夠的突發(fā)情況,增強(qiáng)學(xué)習(xí)算法就可以學(xué)習(xí)到對(duì)應(yīng)的處理方法,而不用每種突發(fā)情況都單獨(dú)寫規(guī)則處理。而且,模擬器也可以根據(jù)之前增強(qiáng)學(xué)習(xí)對(duì)于突發(fā)情況的處理結(jié)果,盡量產(chǎn)生出當(dāng)前的增強(qiáng)學(xué)習(xí)算法無法解決的突發(fā),從而增強(qiáng)學(xué)習(xí)效率。
綜上所述,自動(dòng)駕駛模擬器對(duì)決策模塊的驗(yàn)證和學(xué)習(xí)都有著至關(guān)重要的作用,是無人駕駛領(lǐng)域的核心技術(shù)。如何創(chuàng)建出能夠模擬出真實(shí)場(chǎng)景、覆蓋大部分突發(fā)情況、并且和真實(shí)的汽車接口兼容的模擬器,是自動(dòng)駕駛研發(fā)的難點(diǎn)之一。
增強(qiáng)學(xué)習(xí)在自動(dòng)駕駛中的應(yīng)用和展望
增強(qiáng)學(xué)習(xí)在自動(dòng)駕駛中很有前景。我們?cè)赥ORCS模擬器中使用增強(qiáng)學(xué)習(xí)進(jìn)行了探索性的工作。TORCS是一個(gè)賽車模擬器。玩家的任務(wù)是超過其他AI車,以最快速度達(dá)到終點(diǎn)。雖然TORCS中的任務(wù)和真實(shí)的自動(dòng)駕駛?cè)蝿?wù)還有很大區(qū)別。但其中算法的性能非常容易評(píng)估。TORCS模擬器如圖5所示。增強(qiáng)學(xué)習(xí)算法一般可以以前方和后方看到的圖像作為輸入,也可以環(huán)境狀態(tài)作為輸入(例如速度,離賽道邊緣的距離和跟其他車的距離)。
圖5 TORCS模擬器截圖
我們這里使用了環(huán)境狀態(tài)作為輸入。使用Deep Q-learning做為學(xué)習(xí)算法學(xué)習(xí)。環(huán)境獎(jiǎng)勵(lì)定義為在單位時(shí)刻車輛沿跑道的前進(jìn)距離。另外,如果車出了跑道或者和其他的車輛相撞,會(huì)得到額外懲罰。環(huán)境狀態(tài)包括車輛的速度、加速度、離跑道的左右邊緣的距離,以及跑道的切線夾角,在各個(gè)方向上最近的車的距離等等。車的行為包括向上換擋、向下?lián)Q擋、加速、減速、向左打方向盤、向右打方向盤等等。
與普通的Deep Q-learning相比,我們做了以下的改進(jìn)。首先,使用了多步TD算法進(jìn)行更新。多步TD算法能比單步算法每次學(xué)習(xí)時(shí)看到更多的執(zhí)行部數(shù),因此也能更快地收斂。其次,我們使用了Actor-Critic的架構(gòu)。它把算法的策略函數(shù)和值函數(shù)分別使用兩個(gè)網(wǎng)絡(luò)表示。這樣的表示有兩個(gè)優(yōu)點(diǎn):1. 策略函數(shù)可以使用監(jiān)督學(xué)習(xí)的方式進(jìn)行初始化學(xué)習(xí)。2. 在環(huán)境比較復(fù)雜的時(shí)候,學(xué)習(xí)值函數(shù)非常的困難。把策略函數(shù)和值函數(shù)分開學(xué)習(xí)可以降低策略函數(shù)學(xué)習(xí)的難度。
使用了改進(jìn)后的Deep Q-learning算法,我們學(xué)習(xí)到的策略在TORCS中可以實(shí)現(xiàn)沿跑到行走,換道,超車等行為。基本達(dá)到了TORCS環(huán)境中的基本駕駛的需要。Google DeepMind直接使用圖像作為輸入,也獲得了很好的效果,但訓(xùn)練的過程要慢很多。
現(xiàn)有的增強(qiáng)學(xué)習(xí)算法在自動(dòng)駕駛模擬環(huán)境中獲得了很有希望的結(jié)果。但是可以看到,如果需要增強(qiáng)學(xué)習(xí)真正能夠在自動(dòng)駕駛的場(chǎng)景下應(yīng)用,還需要有很多改進(jìn)。第一個(gè)改進(jìn)方向是增強(qiáng)學(xué)習(xí)的自適應(yīng)能力。現(xiàn)有的增強(qiáng)學(xué)習(xí)算法在環(huán)境性質(zhì)發(fā)生改變時(shí),需要試錯(cuò)很多次才能學(xué)習(xí)到正確的行為。而人在環(huán)境發(fā)生改變的情況下,只需要很少次試錯(cuò)就可以學(xué)習(xí)到正確的行為。如何只用非常少量樣本學(xué)習(xí)到正確的行為是增強(qiáng)學(xué)習(xí)能夠?qū)嵱玫闹匾獥l件。
第二個(gè)重要的改進(jìn)方向是模型的可解釋性。現(xiàn)在增強(qiáng)學(xué)習(xí)中的策略函數(shù)和值函數(shù)都是由深度神經(jīng)網(wǎng)絡(luò)表示的,其可解釋性比較差,在實(shí)際的使用中出了問題,很難找到原因,也比較難以排查。在自動(dòng)駕駛這種人命關(guān)天的任務(wù)中,無法找到原因是完全無法接受的。
第三個(gè)重要的改進(jìn)方向是推理和想象能力。人在學(xué)習(xí)的過程中很多時(shí)候需要有一定的推理和想象能力。比如,在駕駛時(shí),不用親身嘗試,也知道危險(xiǎn)的行為會(huì)帶來毀滅性的后果。 這是因?yàn)槿祟悓?duì)這個(gè)世界有一個(gè)足夠好的模型來推理和想象做出相應(yīng)行為可能會(huì)發(fā)生的后果。這種能力不僅對(duì)于存在危險(xiǎn)行為的環(huán)境下下非常重要,在安全的環(huán)境中也可以大大加快收斂速度。
只有在這些方向做出了實(shí)質(zhì)突破,增強(qiáng)學(xué)習(xí)才能真正使用到自動(dòng)駕駛或是機(jī)器人這種重要的任務(wù)場(chǎng)景中。希望更多有志之士能投身這項(xiàng)研究,為人工智能的發(fā)展貢獻(xiàn)出自己的力量。
-
無人駕駛
+關(guān)注
關(guān)注
99文章
4170瀏覽量
123334 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14287瀏覽量
170347
原文標(biāo)題:增強(qiáng)學(xué)習(xí)在無人駕駛中的應(yīng)用
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
智行者科技無人駕駛小巴落地海南

易控智駕發(fā)布礦山無人駕駛應(yīng)用落地成果
DeepSeek眼中的礦山無人駕駛
為什么聊自動(dòng)駕駛的越來越多,聊無人駕駛的越來越少?
深入探討試驗(yàn)機(jī)數(shù)據(jù)采集系統(tǒng)在力學(xué)試驗(yàn)室中發(fā)揮的作用
小馬智行第六代無人駕駛Robotaxi亮相香港國(guó)際機(jī)場(chǎng)
測(cè)速雷達(dá)與無人駕駛技術(shù)的結(jié)合 測(cè)速雷達(dá)故障排除技巧
UWB模塊如何助力無人駕駛技術(shù)
特斯拉推出無人駕駛Model Y
百度計(jì)劃海外推出蘿卜快跑無人駕駛服務(wù)
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】+ 簡(jiǎn)單建議
TS RadiMation測(cè)試軟件如何在脈沖抗擾度測(cè)試中發(fā)揮作用?
5G賦能車聯(lián)網(wǎng),無人駕駛引領(lǐng)未來出行






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論