") 一種基于CNN的通用框架來(lái)區(qū)別自然圖像NIs與計(jì)算機(jī)生成圖像CG之間的差異
一種基于CNN的通用框架來(lái)區(qū)別自然圖像NIs與計(jì)算機(jī)生成圖像CG之間的差異

傳統(tǒng)的肉眼識(shí)別方法是很難直接識(shí)別出 NIs (自然圖像) 和 CG (計(jì)算機(jī)生成的圖像)。本文中提出了一種高效的、基于卷積神經(jīng)網(wǎng)絡(luò) (CNN) 的圖像識(shí)別方法。通過(guò)大量的實(shí)驗(yàn)來(lái)評(píng)估模型的性能。實(shí)驗(yàn)結(jié)果表明,該方法優(yōu)于現(xiàn)有的其他識(shí)別方法,與傳統(tǒng)方法中采用 CNN 模型來(lái)識(shí)別圖像,此方法還能借助高級(jí)可視化工具。
▌?wù)?/p>
考慮到對(duì)現(xiàn)有的 CCNs 從頭開(kāi)始訓(xùn)練或微調(diào)預(yù)訓(xùn)練網(wǎng)絡(luò)都具有一定的局限性,這個(gè)研究提出了一種更合適的想法:設(shè)計(jì)階段在 CNN 模型的底部增加了兩個(gè)級(jí)聯(lián)卷積層。該網(wǎng)絡(luò)能夠根據(jù)不同大小的圖像輸入,進(jìn)行自適應(yīng)地調(diào)整,同時(shí)保持固定的深度,以穩(wěn)定 CNN 結(jié)構(gòu)并實(shí)現(xiàn)良好的識(shí)別表現(xiàn)。對(duì)于所提出的模型,我們采用一種稱為“局部到全局”的策略,即 CNN 能夠獲取局部圖像的識(shí)別決策,而全局的識(shí)別決策可通過(guò)簡(jiǎn)單的投票方式獲得。我們通過(guò)大量的實(shí)驗(yàn)來(lái)評(píng)估模型的性能。實(shí)驗(yàn)結(jié)果表明,該方法優(yōu)于現(xiàn)有的其他識(shí)別方法,且在后處理的圖像上也具有較好的魯棒性。此外,相比于傳統(tǒng)方法中采用 CNN 模型來(lái)識(shí)別圖像,我們的方法還能借助高級(jí)可視化工具,進(jìn)一步可視化地了解 NIs 與 CG 之間的差異。
▌簡(jiǎn)介
當(dāng)前,對(duì) NIs 和 CG 的圖像識(shí)別研究已經(jīng)得到了廣泛的關(guān)注。解決這個(gè)問(wèn)題的主要挑戰(zhàn)在于 NIs 與 CG 有近乎相同的寫(xiě)實(shí)性及圖像模式。先前的研究通常都是人工設(shè)計(jì)一些可判別的特征,來(lái)區(qū)別 NIs 和 CG。但這些方法普遍存在的問(wèn)題是人為設(shè)計(jì)的特征對(duì)于給定的圖像識(shí)別問(wèn)題來(lái)說(shuō),并不一定是最適合的,特別對(duì)于一些復(fù)雜的數(shù)據(jù)庫(kù)而言,該方法的識(shí)別效果更差。
相比于需要先驗(yàn)知識(shí)和假設(shè)條件的傳統(tǒng)方法,卷積神經(jīng)網(wǎng)絡(luò) (CNN) 能夠自動(dòng)地從數(shù)據(jù)中學(xué)習(xí)目標(biāo)的特征及其抽象表征,這使得它能夠更廣泛適用于一些復(fù)雜的數(shù)據(jù)庫(kù)。本文,我們提出一種基于 CNN 的框架來(lái)識(shí)別 NIs 和 CG。這是一種以端到端的方式進(jìn)行自動(dòng)特征學(xué)習(xí),而無(wú)需進(jìn)行人為設(shè)計(jì)圖像特征的框架。我們的工作主要總結(jié)如下:
提出了一種基于 CNN 的 NIs 與 CG 的通用識(shí)別框架,通過(guò)微調(diào)它能夠自適應(yīng)于不同尺寸的圖像輸入塊。
對(duì)微調(diào)訓(xùn)練后的 CNN 模型,我們針對(duì)性地設(shè)計(jì)了一種改進(jìn)方案以改進(jìn)我們的識(shí)別表現(xiàn),這兩種基于 CNN 的方案都優(yōu)于目前最先進(jìn)的方法。
我們的方法在 Google 和 PRCG 數(shù)據(jù)庫(kù)上都表現(xiàn)出良好的識(shí)別性能,而且對(duì)調(diào)整圖像大小和壓縮 JPEG 等后處理操作有強(qiáng)大的魯棒性。
利用可視化工具,我們進(jìn)一步地了解 CNN 模型是如何區(qū)分 NIs 和 CG。
▌數(shù)據(jù)集
我們使用的實(shí)驗(yàn)數(shù)據(jù)包括 Columbia Photo-graphic 與 PRCG 數(shù)據(jù)庫(kù)。數(shù)據(jù)庫(kù)由三組圖像組成:(1) 從40個(gè) 3D 圖形網(wǎng)站中獲取的800張 PRCGs 數(shù)據(jù);(2) 我們所采集的800張 NIs;以及 (3) 從 Google 搜索中獲取的795張攝影圖像。
我們所采集的300張 NIs 是通過(guò)小型數(shù)碼相機(jī)拍攝的。先前研究的方法都沒(méi)有在 Google 與 PRCG 數(shù)據(jù)庫(kù)上進(jìn)行過(guò)測(cè)試,這是因?yàn)?Google中的 NIs 與PRCG中的CG圖像起源不同。而我們的研究不僅嘗試解決這個(gè)問(wèn)題,而且還將在 Personal 與 PRCG ,以及 Personal+Google 與 PRCG 兩種不同數(shù)據(jù)庫(kù)組合條件下進(jìn)行測(cè)試。
▌框架
我們將 NIs 與 CG 的圖像識(shí)別問(wèn)題視為是一個(gè)二元分類問(wèn)題。針對(duì)此問(wèn)題,提出了兩種不同的圖像識(shí)別標(biāo)準(zhǔn)框架,如圖1所示:其中,f 是特征提取器,c 代表一個(gè)分類器 (如 SVM) 。我們的框架是一個(gè)二階段模型,其核心在于特征提取器。通常,特征的提取過(guò)程不僅需要耗費(fèi)大量的時(shí)間,且提取出來(lái)的特征不一定是我們?nèi)蝿?wù)所需要的,而我們的 CNN 框架能夠以端到端的方式自動(dòng)學(xué)習(xí)并提取所需特征,這為解決特征提取問(wèn)題提供了一種思路。因此,我們提出了一種適用的 CNN 模型,并采用以下三種不同的訓(xùn)練方法:(1) 遵循現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu),并從頭開(kāi)始訓(xùn)練 CNN 模型;(2) 微調(diào)一個(gè)預(yù)先在其他數(shù)據(jù)集或另外一個(gè)任務(wù)中訓(xùn)練好的、現(xiàn)成的 CNN 網(wǎng)絡(luò);(3) 設(shè)計(jì)一個(gè)新的網(wǎng)絡(luò),并從頭開(kāi)始訓(xùn)練。
圖1 兩種不同的圖像識(shí)別框架
局部到全局策略
考慮到模型的計(jì)算成本,圖片尺寸的多樣性以及圖像識(shí)別的性能要求,我們采用一種由局部到全局的策略,來(lái)對(duì)局部圖像進(jìn)行訓(xùn)練并使用簡(jiǎn)單的投票規(guī)則再對(duì)全局的圖像進(jìn)行分類。這種由局部到全局的策略是一種基于數(shù)據(jù)增強(qiáng)的思想,也是擴(kuò)展訓(xùn)練中的常用技巧,尤其是在深度學(xué)習(xí)領(lǐng)域。
對(duì)于圖像分類問(wèn)題,局部策略 (即高精度的局部圖像) 對(duì)于圖像識(shí)別來(lái)說(shuō)是非常重要的;另一方面,從 CG 上裁剪下來(lái)的圖像本質(zhì)仍是 CG,而對(duì) Nis 而言也是如此。因此,我們引入數(shù)據(jù)增強(qiáng)的方法,也就是說(shuō),從每次訓(xùn)練中選擇一些固定尺寸的圖像去增強(qiáng)訓(xùn)練數(shù)據(jù)集,并且盡可能地去獲取更高精度的圖像。在實(shí)踐階段,我們使用 Maximal Poisson-disk 從每次訓(xùn)練中隨機(jī)裁剪一定數(shù)量的圖像來(lái)構(gòu)建新的訓(xùn)練數(shù)據(jù)集。在測(cè)試階段,從每個(gè)測(cè)試圖像中裁剪一定數(shù)量的局部圖像,并給每張局部圖像加上特定的標(biāo)簽 ( CG 屬于0,而 NI 屬于1 ),編號(hào)較高的標(biāo)簽作為該圖像的預(yù)測(cè)結(jié)果。
網(wǎng)絡(luò)結(jié)構(gòu)
我們所采用的網(wǎng)絡(luò)結(jié)構(gòu)由 ConvFilter 層,3個(gè)卷積層組,2層 FC 層以及1個(gè)softmax 分類層組成,模型的輸入是二進(jìn)制的圖片格式。其結(jié)構(gòu)如下圖2所示:我們的輸入是一張233*233的 RGB 圖像,用綠色方塊表示;紅色方塊代表卷積核,靠近它的數(shù)字代表該卷積核的尺寸,左側(cè)的紅色方塊代表一個(gè)7*7的卷積核;特征圖則由陰影部分的長(zhǎng)方體所示。
圖2 我們的網(wǎng)絡(luò)結(jié)構(gòu)
▌實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)設(shè)置與細(xì)節(jié)
我們使用了雙三次插值來(lái)調(diào)整所有圖像的大小,調(diào)整后的圖片的較短邊像素值為512,以此確保所有圖像的大小一致性。基于原始數(shù)據(jù)集,我們以 3:1 的分離率來(lái)設(shè)置訓(xùn)練集和測(cè)試集,并用 MPS 從每張訓(xùn)練數(shù)據(jù)中裁剪出 200 張,以滿足局部到全局策略的需要并達(dá)到擴(kuò)充訓(xùn)練數(shù)據(jù)的目的。同樣地,從每張測(cè)試數(shù)據(jù)中裁剪出 30 張來(lái)作為測(cè)試集。在訓(xùn)練時(shí),我們采用128的批次大小,學(xué)習(xí)率設(shè)置為0.001,每 30k 次迭代學(xué)習(xí)率就除以10,直到迭代完 90k 次為止。此外,除了 60×60 和 30×30 圖像塊大小的正則化設(shè)置為 5e-5 和 1e-5 外,其余的正則化權(quán)重的默認(rèn)值為 1e-4。
微調(diào) CaffeNet 和卷積濾波器層的性能分析
微調(diào)后的 CaffeNet 的測(cè)試結(jié)果如下表 1 所示。我們可以看到,微調(diào)后網(wǎng)絡(luò) (C-1 到 C-7) 的測(cè)試性能要優(yōu)于從頭開(kāi)始訓(xùn)練的網(wǎng)絡(luò) (C-S) 實(shí)驗(yàn)結(jié)果,這可能是由于預(yù)訓(xùn)練期間學(xué)習(xí)大量 NI 對(duì)模型的特征學(xué)習(xí)是有益的。而相比于傳統(tǒng)方法 (準(zhǔn)確率最高80.65%),通過(guò)微調(diào)后,我們的網(wǎng)絡(luò)性能更佳,準(zhǔn)確率更高。

表1 模型的分類精度,其中 C 表示 CaffeNet,”C-S” 表示從頭開(kāi)始訓(xùn)練網(wǎng)絡(luò) CaffeNet,”C-N” 表示微調(diào) CaffeNet 后的前 N 層網(wǎng)絡(luò),N 從1到7。
此外,我們還對(duì) ConvFilter 層進(jìn)行了四種不同的配置: (1) 兩個(gè)級(jí)聯(lián)卷積層;(2) 刪除 convFilter 層;(3) convFilter 層之后接 ReLU 激活層;以及(4) convFilter 層中加入高通濾波器。下表2 顯示了這四種配置相對(duì)應(yīng)的模型性能,其中使用兩個(gè)級(jí)聯(lián)卷積層時(shí)模型的準(zhǔn)確率最高。

表2 四種不同配置下的 convFilter 的分類精度
不同尺寸圖像塊上的分類性能
下圖 3 展示了我們的方法與三種人工設(shè)計(jì)特征的方法在不同尺寸圖像塊上的分類精度。與其他三種方法相比較,我們的方法在任何圖像塊尺寸上的準(zhǔn)確率都更高,且隨著圖像塊尺寸的縮小,網(wǎng)絡(luò)的分類準(zhǔn)確率會(huì)降低。
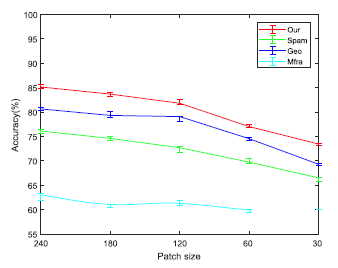
圖3 我們的方法與三種人工設(shè)計(jì)特征的方法在不同尺寸圖像塊上的分類精度表現(xiàn)
后處理的魯棒性分析
有效的圖像識(shí)別算法不僅能處理原始數(shù)據(jù),還應(yīng)該在后處理數(shù)據(jù)中具有良好的魯棒性。本文的研究中,我們針對(duì)圖像縮放和 JPEG 壓縮這兩種典型的后處理進(jìn)行魯棒性分析。下圖 4 展示了四種分類方法在五種后處理中的分類準(zhǔn)確率表現(xiàn) (實(shí)線部分)。可以看到,我們的模型對(duì)于后處理的數(shù)據(jù)具有更強(qiáng)的魯棒性。
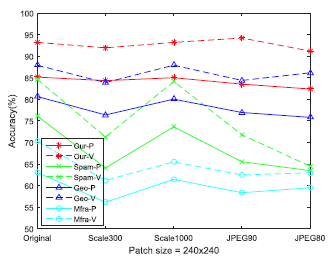
圖4 不同分類方法在后處理數(shù)據(jù)上的分類精度表現(xiàn)
局部到全局策略的分析
進(jìn)一步地,我們還分析了局部到全局策略在全尺寸圖像上的分類精度表現(xiàn)。如下表3所示,實(shí)驗(yàn)結(jié)果表明在全尺寸圖像上的模型精度,比在圖像塊上的模型精度要高,并且采用圖像塊投票的方式獲得的全尺寸分類精度要高于直接在全尺寸上圖像得到的分類精度。而投票準(zhǔn)確性對(duì)后處理操作的穩(wěn)健性由上圖4中的虛線表示。
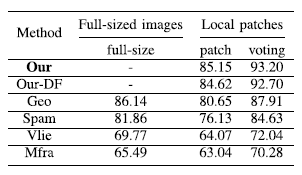
表3 局部到全局策略對(duì)六種方法的分類準(zhǔn)確率的影響
▌可視化
在計(jì)算機(jī)視覺(jué)任務(wù)中,CNN 的訓(xùn)練普遍存在一種現(xiàn)象:即模型在第一層學(xué)習(xí)的卷積核類似于 Gabor 濾波器和 color blobs。我們?cè)谙聢D 5 展示了模型的卷積可視化結(jié)果,其中 (a) 表示我們模型的第一層卷積核的傅里葉變換 (FFT) 結(jié)果, (b) 表示預(yù)訓(xùn)練的 CaffeNet 的結(jié)果,(c) 是對(duì)應(yīng)于 CaffeNet 中第一層的前96個(gè)卷積核的可視化結(jié)果,而 (d) 則對(duì)應(yīng)于最后的96個(gè)結(jié)果。濾波器根據(jù)三個(gè)顏色通道 B,G 和 R 被分為3個(gè)組,而像素越亮則代表所對(duì)應(yīng)的B,G,R的值越高。
圖 5 卷積可視化結(jié)果
▌結(jié)論
本文,我們提出了一種基于 CNN 的通用框架來(lái)區(qū)別自然圖像 NIs 與計(jì)算機(jī)生成圖像 CG 之間的差異,這種方法不僅能夠在 Google 和 PRCG 的數(shù)據(jù)集中進(jìn)行測(cè)試,而在后處理時(shí)也表現(xiàn)出較好的魯棒性。這些優(yōu)點(diǎn)對(duì)于現(xiàn)實(shí)生活中的圖像識(shí)別任務(wù)是非常有效且重要的。
未來(lái)的工作中,我們將嘗試通過(guò)引入語(yǔ)義級(jí)別的 CNN 集成模型來(lái)進(jìn)一步改進(jìn)我們的模型性能。此外,我們還將擴(kuò)展我們的方法,并應(yīng)用于視頻數(shù)據(jù)的差異性探索。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103229 -
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41138 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22686
原文標(biāo)題:學(xué)術(shù) | 一種新的CNN網(wǎng)絡(luò)可以更高效地區(qū)分自然圖像&生成圖像
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
計(jì)算機(jī)圖形圖像處理最新應(yīng)用分析
計(jì)算機(jī)視覺(jué)必讀:區(qū)分目標(biāo)跟蹤、網(wǎng)絡(luò)壓縮、圖像分類、人臉識(shí)別
使用計(jì)算機(jī)制作,一種方便教學(xué)使用的計(jì)算機(jī)的制作方法 精選資料推薦
計(jì)算機(jī)圖形學(xué)總覽:圖像和圖像的概念辨析
如何使用平穩(wěn)小波域深度殘差CNN進(jìn)行低劑量CT圖像估計(jì)
計(jì)算機(jī)視覺(jué)與機(jī)器視覺(jué)之間有什么差異
基于計(jì)算機(jī)的圖像處理方法
計(jì)算機(jī)圖形學(xué) 數(shù)字圖像處理和計(jì)算機(jī)視覺(jué)是什么?
用于計(jì)算機(jī)視覺(jué)訓(xùn)練的圖像數(shù)據(jù)集
一種具有語(yǔ)義區(qū)域風(fēng)格約束的圖像生成框架

一種全新的遙感圖像描述生成方法

一種基于改進(jìn)的DCGAN生成SAR圖像的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論