") 騰訊AI Lab宣布正式開源“Tencent ML-Images”項(xiàng)目
騰訊AI Lab宣布正式開源“Tencent ML-Images”項(xiàng)目

今日,騰訊AI Lab宣布正式開源“Tencent ML-Images”項(xiàng)目,該項(xiàng)目由多標(biāo)簽圖像數(shù)據(jù)集ML-Images,以及業(yè)內(nèi)目前同類深度學(xué)習(xí)模型中精度最高的深度殘差網(wǎng)絡(luò)ResNet-101構(gòu)成。
該項(xiàng)目的開源,是騰訊AI Lab在計(jì)算機(jī)視覺(jué)領(lǐng)域所累積的基礎(chǔ)能力的一次釋放,為人工智能領(lǐng)域的科研人員和工程師提供了充足的高質(zhì)量訓(xùn)練數(shù)據(jù),及簡(jiǎn)單易用、性能強(qiáng)大的深度學(xué)習(xí)模型,促進(jìn)人工智能行業(yè)共同發(fā)展。
騰訊AI Lab此次公布的圖像數(shù)據(jù)集ML-Images,包含了1800萬(wàn)圖像和1.1萬(wàn)多種常見物體類別,在業(yè)內(nèi)已公開的多標(biāo)簽圖像數(shù)據(jù)集中規(guī)模最大,足以滿足一般科研機(jī)構(gòu)及中小企業(yè)的使用場(chǎng)景。此外,基于ML-Images訓(xùn)練得到的深度殘差網(wǎng)絡(luò)ResNet-101,具有優(yōu)異的視覺(jué)表示能力和泛化性能,在當(dāng)前業(yè)內(nèi)同類模型中精度最高,將為包括圖像、視頻等在內(nèi)的視覺(jué)任務(wù)提供強(qiáng)大支撐,并助力圖像分類、物體檢測(cè)、物體跟蹤、語(yǔ)義分割等技術(shù)水平的提升。
本次正式開源,其主要內(nèi)容包括:
ML-Images數(shù)據(jù)集的全部圖像URLs,以及相應(yīng)的類別標(biāo)注。因原始圖像版權(quán)問(wèn)題,此次開源將不直接提供原始圖像,用戶可利用騰訊AI Lab提供的下載代碼和URLs自行下載圖像。
ML-Images數(shù)據(jù)集的詳細(xì)介紹。包括圖像來(lái)源、圖像數(shù)量、類別數(shù)量、類別的語(yǔ)義標(biāo)簽體系、標(biāo)注方法,以及圖像的標(biāo)注數(shù)量等統(tǒng)計(jì)量。
完整的代碼和模型。騰訊AI Lab提供的代碼涵蓋從圖像下載和圖像預(yù)處理,到基于ML-Images的預(yù)訓(xùn)練和基于ImageNet的遷移學(xué)習(xí),再到基于訓(xùn)練所得模型的圖像特征提取的完整流程。項(xiàng)目提供了基于小數(shù)據(jù)集的訓(xùn)練示例,以方便用戶快速體驗(yàn)該訓(xùn)練流程。項(xiàng)目還提供了具有極高精度的ResNet-101模型(在單標(biāo)簽基準(zhǔn)數(shù)據(jù)集ImageNet的驗(yàn)證集上的top-1精度為80.73%)。用戶可根據(jù)自身需求,隨意選用該項(xiàng)目的代碼或模型。
以深度神經(jīng)網(wǎng)絡(luò)為典型代表的深度學(xué)習(xí)技術(shù)已經(jīng)在很多領(lǐng)域充分展現(xiàn)出其優(yōu)異的能力,尤其是計(jì)算機(jī)視覺(jué)領(lǐng)域,包括圖像和視頻的分類、理解和生成等重要任務(wù)。然而,要充分發(fā)揮出深度學(xué)習(xí)的視覺(jué)表示能力,必須建立在充足的高質(zhì)量訓(xùn)練數(shù)據(jù)、優(yōu)秀的模型結(jié)構(gòu)和模型訓(xùn)練方法,以及強(qiáng)大的的計(jì)算資源等基礎(chǔ)能力之上。
各大科技公司都非常重視人工智能基礎(chǔ)能力的建設(shè),都建立了僅面向其內(nèi)部的大型圖像數(shù)據(jù)集,例如谷歌的JFT-300M和Facebook的Instagram數(shù)據(jù)集。但這些數(shù)據(jù)集及其訓(xùn)練得到的模型都沒(méi)有公開,對(duì)于一般的科研機(jī)構(gòu)和中小企業(yè)來(lái)說(shuō),這些人工智能基礎(chǔ)能力有著非常高的門檻。
當(dāng)前業(yè)內(nèi)公開的最大規(guī)模的多標(biāo)簽圖像數(shù)據(jù)集是谷歌公司的Open Images, 包含900萬(wàn)圖像和6000多物體類別。騰訊AI Lab此次開源的ML-Images數(shù)據(jù)集包括1800萬(wàn)圖像和1.1萬(wàn)多常見物體類別,或?qū)⒊蔀樾碌男袠I(yè)基準(zhǔn)數(shù)據(jù)集。
此外,基于ML-Images訓(xùn)練得到的ResNet-101模型,具有優(yōu)異的視覺(jué)表示能力和泛化性能。通過(guò)遷移學(xué)習(xí),該模型在ImageNet驗(yàn)證集上取得了80.73%的top-1分類精度,超過(guò)谷歌同類模型(遷移學(xué)習(xí)模式)的精度,且值得注意的是,ML-Images的規(guī)模僅為JFT-300M的約1/17。這充分說(shuō)明了ML-Images的高質(zhì)量和訓(xùn)練方法的有效性。詳細(xì)對(duì)比如下表。
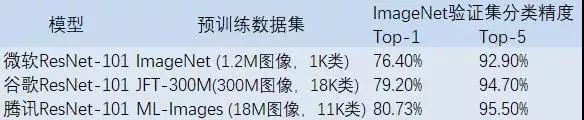
注:微軟ResNet-101模型為非遷移學(xué)習(xí)模式下訓(xùn)練得到,即1.2M預(yù)訓(xùn)練圖像為原始數(shù)據(jù)集ImageNet的圖像。
騰訊AI Lab此次開源的“Tencent ML-Images”項(xiàng)目,展現(xiàn)了騰訊在人工智能基礎(chǔ)能力建設(shè)方面的努力,以及希望通過(guò)基礎(chǔ)能力的開放促進(jìn)行業(yè)共同發(fā)展的愿景。
“Tencent ML-Images”項(xiàng)目的深度學(xué)習(xí)模型,目前已在騰訊多項(xiàng)業(yè)務(wù)中發(fā)揮重要作用,如“天天快報(bào)”的圖像質(zhì)量評(píng)價(jià)與推薦功能,其后臺(tái)測(cè)試的日調(diào)用量已達(dá)1000萬(wàn)次。
如下圖所示,天天快報(bào)新聞封面圖像的質(zhì)量得到明顯提高。
左圖為優(yōu)化前,右圖為優(yōu)化后
此外,騰訊AI Lab團(tuán)隊(duì)還將基于Tencent ML-Images的ResNet-101模型遷移到很多其他視覺(jué)任務(wù),包括圖像物體檢測(cè),圖像語(yǔ)義分割,視頻物體分割,視頻物體跟蹤等。這些視覺(jué)遷移任務(wù)進(jìn)一步驗(yàn)證了該模型的強(qiáng)大視覺(jué)表示能力和優(yōu)異的泛化性能。“Tencent ML-Images”項(xiàng)目未來(lái)還將在更多視覺(jué)相關(guān)的產(chǎn)品中發(fā)揮重要作用。
自2016年騰訊首次在GitHub上發(fā)布開源項(xiàng)目(https://github.com/Tencent),目前已累積開源覆蓋人工智能、移動(dòng)開發(fā)、小程序等領(lǐng)域的57個(gè)項(xiàng)目。為進(jìn)一步貢獻(xiàn)開源社區(qū),騰訊相繼加入Hyperledger、LF Networking和開放網(wǎng)絡(luò)基金會(huì),并成為L(zhǎng)F深度學(xué)習(xí)基金會(huì)首要?jiǎng)?chuàng)始成員及Linux基金會(huì)白金會(huì)員。作為騰訊“開放”戰(zhàn)略在技術(shù)領(lǐng)域的體現(xiàn),騰訊開源將繼續(xù)對(duì)內(nèi)推動(dòng)技術(shù)研發(fā)向共享、復(fù)用和開源邁進(jìn),向外釋放騰訊研發(fā)實(shí)力,為國(guó)內(nèi)外開源社區(qū)提供技術(shù)支持,注入研發(fā)活力。
-
騰訊
+關(guān)注
關(guān)注
7文章
1678瀏覽量
50257 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25393 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5559瀏覽量
122729
原文標(biāo)題:騰訊AI Lab正式開源業(yè)內(nèi)最大規(guī)模多標(biāo)簽圖像數(shù)據(jù)集
文章出處:【微信號(hào):AppDowns,微信公眾號(hào):掌上科技頻道】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NanoEdge AI Studio 面向STM32開發(fā)人員機(jī)器學(xué)習(xí)(ML)技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論