") 如何利用TensorForce框架快速搭建深度強(qiáng)化學(xué)習(xí)模型
如何利用TensorForce框架快速搭建深度強(qiáng)化學(xué)習(xí)模型

深度強(qiáng)化學(xué)習(xí)已經(jīng)在許多領(lǐng)域取得了矚目的成就,并且仍是各大領(lǐng)域受熱捧的方向之一。本文深入淺出的介紹了如何利用TensorForce框架快速搭建深度強(qiáng)化學(xué)習(xí)模型。
深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, DRL)是目前最熱門的方向之一,從視頻游戲、圍棋、蛋白質(zhì)結(jié)構(gòu)預(yù)測到機(jī)器人、計(jì)算機(jī)視覺、推薦系統(tǒng)等領(lǐng)域已經(jīng)取得了很多令人矚目的成就且仍在蓬勃發(fā)展中。
AlphaGo第一作者Davild Silver就認(rèn)為通用人工智能需要強(qiáng)化學(xué)習(xí)結(jié)合深度學(xué)習(xí)來實(shí)現(xiàn),即AGI=DL+RL。
框架
為了便于研究人員快速搭建出強(qiáng)化學(xué)習(xí)模型,很多機(jī)構(gòu)發(fā)布了強(qiáng)化學(xué)習(xí)基準(zhǔn)算法或框架,其中較早的有OpenAI Baselines [1]、伯克利的rllab [2],最新的有18年谷歌發(fā)布的Dopamine [3]、Facebook發(fā)布的Horizon [4]。具體見下表:
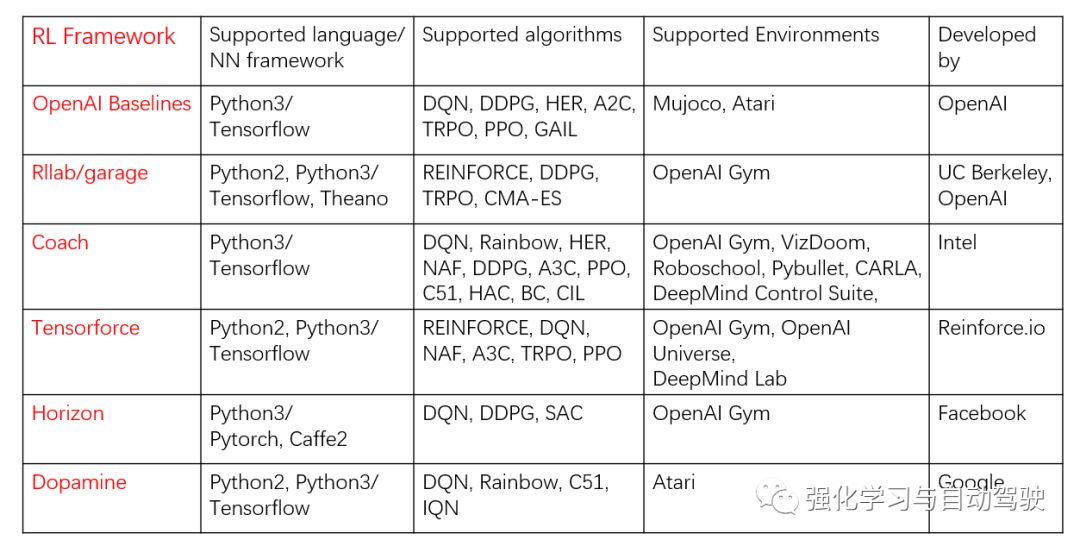
本文介紹的是TensorForce并非由這些大機(jī)構(gòu)發(fā)布,而是由幾個劍橋大學(xué)的博士生開發(fā)、維護(hù)的。
當(dāng)時選擇TensorForcce是因?yàn)樾枰?a href="http://www.tjjbhg.com/v/tag/1004/" target="_blank">ROS框架下開發(fā),而如上表列出的,它完全支持Python2,且包含很多主流的強(qiáng)化學(xué)習(xí)算法、支持OpenAI Gym、DeepMind Lab等常用于強(qiáng)化學(xué)習(xí)算法測試的基準(zhǔn)環(huán)境。
TensorForce是架構(gòu)在TensorFlow上的強(qiáng)化學(xué)習(xí)API,最早在17年就開源了,并發(fā)布了博客[5]介紹其背后的設(shè)計(jì)思想及基本應(yīng)用。
這里簡單介紹一下TensorForce的設(shè)計(jì)思想。
框架設(shè)計(jì)的難點(diǎn)在于如何解耦出其它層面的內(nèi)容,盡可能將共用的部分抽象出來。拿強(qiáng)化學(xué)習(xí)來說,智能體與環(huán)境不斷通過交互試錯來學(xué)習(xí),如果由我們從頭自己編程實(shí)現(xiàn)某個RL任務(wù),為了方便智能體與環(huán)境很自然地會寫在一起。但作為框架卻不行,需要將智能體從環(huán)境中解耦出來。
TensorForce包括了下面四個層面的概念:
Environment <-> Runner <-> Agent <-> Model
Agent在訓(xùn)練前可以加載model,訓(xùn)練后保存model,運(yùn)行時接收state,(預(yù)處理后)作為model的輸入,返回action。模型會根據(jù)算法及配置自動更新。Runner將Agent和Environment之間的交互抽象出來作為函數(shù)。Environment根據(jù)應(yīng)用場景的不同需要自己寫接口,后文會提供一個機(jī)器人導(dǎo)航環(huán)境的接口案例。如果是學(xué)習(xí)或者算法測試,可以使用現(xiàn)成的基準(zhǔn)環(huán)境,TensorForce提供了OpenAI Gym、OpenAI Universe和DeepMind Lab的接口。
第一行代碼
下面通過使用近端策略優(yōu)化(Proximal Policy Optimization, PPO)算法訓(xùn)練OpenAI Gym中倒立擺來初識TensorForce的簡潔和強(qiáng)大。
from tensorforce.agents import PPOAgentfrom tensorforce.execution import Runnerfrom tensorforce.contrib.openai_gym import OpenAIGym# Create an OpenAIgym environment.environment=OpenAIGym('CartPole-v0',visualize=True)network_spec=[dict(type='dense',size=32,activation='relu'),dict(type='dense',size=32,activation='relu')]agent = PPOAgent(states=environment.states,actions=environment.actions,network=network_spec,step_optimizer=dict(type='adam',learning_rate=1e-3),saver=dict(directory='./saver/',basename='PPO_model.ckpt',load=False,seconds=600),summarizer=dict(directory='./record/',labels=["losses","entropy"],seconds=600),)# Create the runnerrunner=Runner(agent=agent,environment=environment)# Start learningrunner.run(episodes=600, max_episode_timesteps=200)runner.close()
很快,倒立擺能夠平衡:
使用TensorBoard查看訓(xùn)練過程(左圖是loss,右圖是entropy):
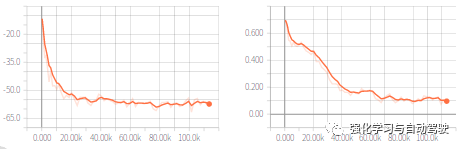
上面我們只用了30行代碼實(shí)現(xiàn)了PPO算法訓(xùn)練倒立擺,代碼首先定義了環(huán)境和網(wǎng)絡(luò)(兩層32個節(jié)點(diǎn)的全連接網(wǎng)絡(luò),激活函數(shù)為relu),然后定義了agent,agent的參數(shù)中states, actions, network三個參數(shù)是必填的,step_optimizer定義了優(yōu)化器,saver和summarizer分別保存模型和訓(xùn)練過程。最后通過runner來實(shí)現(xiàn)agent和environment的交互,總共跑了600個episodes,每個episode的最大步長是200。
runner解耦出了交互過程,實(shí)際上是是下面過程的循環(huán):
# Query the agent for its action decisionaction = agent.act(state)# Execute the decision and retrieve the current informationobservation, terminal, reward = GazeboMaze.execute(action)# Pass feedback about performance (and termination) to the agentagent.observe(terminal=terminal, reward=reward)
在上述過程中,agent會儲存相關(guān)信息來更新模型,比如DQNAgent會存儲(state, action, reward, next_state)。
視頻游戲
TensorForce提供了豐富的observation預(yù)處理功能,視頻游戲是DRL最先取得突破的方向,以Flappy Bird為例,需要進(jìn)行四個步驟的預(yù)處理:
轉(zhuǎn)化為灰度圖,去除不必要的顏色信息;
縮小輸入的游戲截屏,resize為80*80;
堆疊連續(xù)的四幀,推導(dǎo)出運(yùn)行信息;
歸一化處理,以便于訓(xùn)練。
使用TensorForce可以很方便地進(jìn)行預(yù)處理:
states = dict(shape=(3264, 18723, 3), type='float')states_preprocessing_spec = [dict( type='image_resize', width=80, height=80), dict( type='grayscale'),dict( type='normalize')dict( type='sequence', length=4)]agent = DQNAgent( states=states, actions=actions, network=network_spec, states_preprocessing=states_preprocessing_spec)
環(huán)境搭建
如果要在具體的應(yīng)用場景中使用TensorForce就需要根據(jù)應(yīng)用場景手動搭建環(huán)境,環(huán)境的模板為environment.py [7],其中最重要的函數(shù)是execute,該函數(shù)接收agent產(chǎn)生的action,并在環(huán)境中執(zhí)行該action,然后返回next_state,reward,terminal。這里我以搭建的Gazebo中的機(jī)器人導(dǎo)航環(huán)境為例,進(jìn)行介紹。
首先搭建仿真環(huán)境如下圖:
設(shè)計(jì)環(huán)境的接口及其與agent交互的過程:
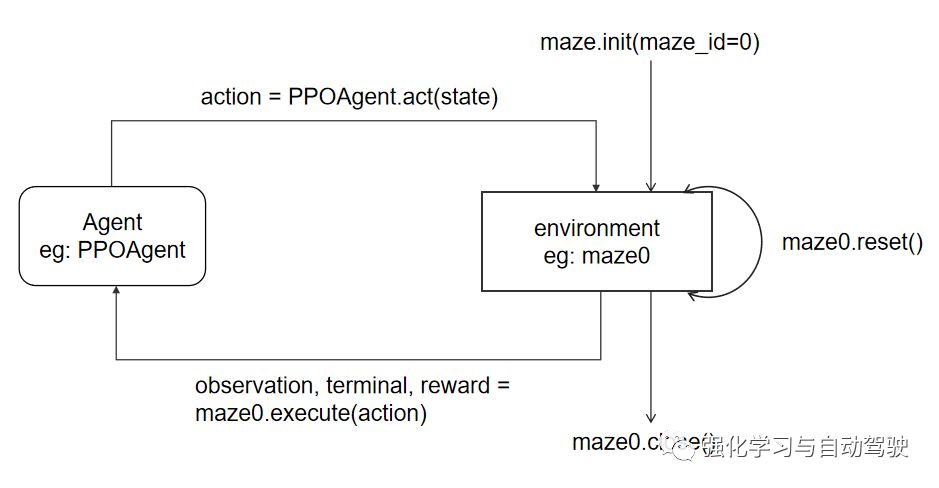
仿真開始,init函數(shù)打開Gazebo并加載對應(yīng)的導(dǎo)航環(huán)境,reset函數(shù)初始化機(jī)器人,execute函數(shù)接收到action后通過ROS發(fā)送對應(yīng)的速度命令,Gazebo中的機(jī)器人接收到速度命令后執(zhí)行對應(yīng)的速度,機(jī)器人傳感器返回相應(yīng)的信息,計(jì)算對應(yīng)的reward,讀取視覺傳感器的RGB圖像作為next_state,判斷是否到達(dá)目標(biāo)點(diǎn)或者碰撞,如果是Terminal為True,該episode結(jié)束。完整的代碼見 [8]。
復(fù)雜網(wǎng)絡(luò)
DRL網(wǎng)絡(luò)和算法是智能體最重要的兩部分,一個確定模型結(jié)構(gòu)、一個決定模型更新。上面只介紹了簡單的模型,對于有些復(fù)雜網(wǎng)絡(luò)需要層疊的方式來定義,如下如:
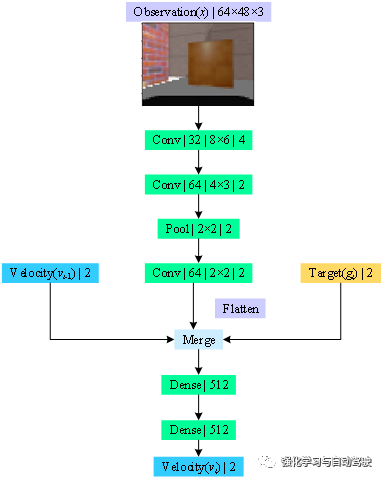
該網(wǎng)絡(luò)的輸入為64*48*3的RGB圖像,由卷積層提取特征后與2維的速度信息和運(yùn)動信息共同輸入全連接層進(jìn)行決策。首先定義state:
states=dict(image=dict(shape=(48,64,3),type='float'),#Observationprevious_act=dict(shape=(2,),type='float'),#velocityrelative_pos=dict(shape=(2,),type='float')#target)
然后定義action即velocity,這里為機(jī)器人的線速度(限制在[0,1])和角速度(限制在[-1,1]):
dict(linear_vel=dict(shape=(),type='float',min_value=0.0,max_value=1.0),angular_vel=dict(shape=(),type='float',min_value=-1.0,max_value=1.0))
然后通過層疊的方式來定義網(wǎng)絡(luò)結(jié)構(gòu):
network_spec=[[dict(type='input',names=['image']),dict(type='conv2d',size=32,window=(8,6),stride=4,activation='relu',padding='SAME'),dict(type='conv2d',size=64,window=(4,3),stride=2,activation='relu',padding='SAME'),dict(type='pool2d',pooling_type='max',window=2,stride=2,padding='SAME'),dict(type='conv2d',size=64,window=2,stride=2,activation='relu',padding='SAME'),dict(type='flatten'),dict(type='output',name='image_output')],[dict(type='input',names=['image_output','previous_act','relative_pos'],aggregation_type='concat'),dict(type='dense',size=512,activation='relu'),dict(type='dense',size=512,activation='relu'),]]
完整代碼見[8]
其它
1. agent會有actions_exploration參數(shù)來定義exploration,默認(rèn)值為'none',但這并不代表不探索,以PPO為例,模型在輸出的時候不輸出直接的確定性動作(只有DPG才會輸出確定性動作),而是分布,輸出在分布上采樣輸出,這可以看作是一種exploration。
2. 網(wǎng)絡(luò)的輸出層是根據(jù)action自動添加的,在network中定義輸入層和隱藏層即可
3. 如果不再需要exploration而只是exploitation,則運(yùn)行:
agent.act(action,deterministic=True)
此時agent執(zhí)行g(shù)reedy策略。而如果模型訓(xùn)練完成,不再訓(xùn)練則:
agent.act(action,independent=True)
此時函數(shù)只執(zhí)行act不執(zhí)行observe來更新模型
4. PPO算法相比于DQN,不僅性能好,并且對超參數(shù)更魯棒,建議優(yōu)先選擇PPO
-
人工智能
+關(guān)注
關(guān)注
1805文章
48899瀏覽量
247951 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1708瀏覽量
46669 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11552
原文標(biāo)題:快速上手深度強(qiáng)化學(xué)習(xí)?學(xué)會TensorForce就夠了
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
如何構(gòu)建強(qiáng)化學(xué)習(xí)模型來訓(xùn)練無人車算法
深度強(qiáng)化學(xué)習(xí)的概念和工作原理的詳細(xì)資料說明
深度強(qiáng)化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
機(jī)器學(xué)習(xí)中的無模型強(qiáng)化學(xué)習(xí)算法及研究綜述

模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于深度強(qiáng)化學(xué)習(xí)的路口單交叉信號控制
基于深度強(qiáng)化學(xué)習(xí)仿真集成的壓邊力控制模型
基于深度強(qiáng)化學(xué)習(xí)的無人機(jī)控制律設(shè)計(jì)方法
《自動化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

ESP32上的深度強(qiáng)化學(xué)習(xí)

ICLR 2023 Spotlight|節(jié)省95%訓(xùn)練開銷,清華黃隆波團(tuán)隊(duì)提出強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架RLx2






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論