 MIT韓松等人團隊開發了一種高效的神經結構搜索算法
MIT韓松等人團隊開發了一種高效的神經結構搜索算法

MIT韓松等人團隊開發了一種高效的神經結構搜索算法,可以為在特定硬件上自動設計快速運行的神經網絡提供一個“按鈕型”解決方案,算法設計和優化的機器學習模型比傳統方法快200倍。
使用算法自動設計神經網絡是人工智能的一個新領域,而且算法設計的系統比人類工程師開發的系統更準確、更高效。
但是這種所謂的神經結構搜索(NAS)技術在計算上非常昂貴。
谷歌最近開發的最先進的NAS算法,它可以在一組GPU上運行,需要48000小時來生成一個用于圖像分類和檢測任務的卷積神經網絡。當然了,谷歌擁有并行運行數百個GPU和其他專用硬件的資金實力,但這對其他大部分人來說是遙不可及的。
在5月份即將舉行的ICLR會議發表的一篇論文中,MIT的研究人員描述了一種NAS算法,僅需200小時,可以專為目標硬件平臺(當在大規模圖像數據集上運行時)直接學習卷積神經網絡。這可以使這類算法得到更廣泛的使用。

論文:ProxylessNAS: 在目標任務和硬件上直接搜索神經架構
地址:https://arxiv.org/pdf/1812.00332.pdf
研究人員表示,資源匱乏的研究人員和企業可以從節省時間和成本的算法中受益。論文作者之一、MIT電子工程與計算機科學助理教授、微系統技術實驗室研究員韓松(Song Han)表示,他們的總體目標是“AI民主化”。
MIT電子工程與計算機科學助理教授韓松
他說:“我們希望通過在特定硬件上快速運行的一個’按鈕型’(push-button)的解決方案,讓AI專家和非專家都能夠高效地設計神經網絡架構。”
韓松補充說,這樣的NAS算法永遠不會取代人類工程師。“目的是減輕設計和改進神經網絡架構所帶來的重復和繁瑣的工作,”他說。他的團隊中的兩位研究人員Han Cai和Ligeng Zhu參與了論文。
ImageNet最高精度,計算成本降低200倍
在他們的工作中,研究人員開發了一些方法來刪除不必要的神經網絡設計組件,以縮短計算時間,并僅使用一小部分硬件內存來運行NAS算法。另一項創新確保每個輸出的CNN在特定的硬件平臺(CPU、GPU和移動設備)上運行得比傳統方法更高效。在測試中,研究人員用手機測得CNN運行速度是傳統方法的1.8倍,準確度與之相當。
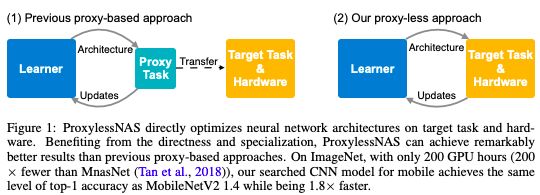
CNN的架構由可調參的計算層(稱為“過濾器”)和過濾器之間可能的連接組成。過濾器處理正方形網格形式的圖像像素,如3x3、5x5或7x7,每個過濾器覆蓋一個正方形。過濾器基本上是在圖像上移動的,并將其覆蓋的像素網格的所有顏色合并成單個像素。不同的層可能具有不同大小的過濾器,并以不同的方式連接以共享數據。輸出是一個壓縮圖像——來自所有過濾器的組合信息——因此可以更容易地由計算機進行分析。
由于可供選擇的架構的數量——稱為“搜索空間”——是如此之大,因此應用NAS在大型圖像數據集上創建神經網絡在計算上是令人望而卻步的。工程師們通常在較小的proxy數據集上運行NAS,并將它們學到的CNN架構轉移到目標任務。然而,這種泛化方法降低了模型的精度。此外,相同的輸出架構也適用于所有硬件平臺,這造成了效率問題。
研究人員直接在ImageNet數據集中的一個圖像分類任務上訓練并測試了他們的新NAS算法。他們首先創建了一個搜索空間,其中包含所有可能的CNN候選“路徑”(paths)——即層和過濾器連接以處理數據的方式。這使得NAS算法可以自由地找到最優的架構。
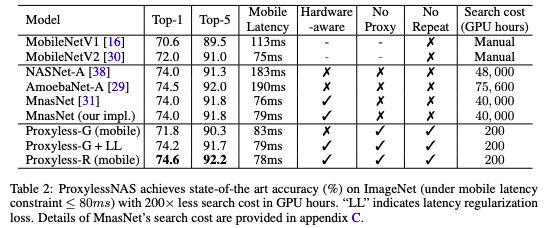
ProxylessNAS在ImageNet上達到最高精度,且搜索成本的GPU hours減少了200倍
通常,這意味著所有可能的路徑都必須存儲在內存中,這將超過GPU的內存限制。為了解決這個問題,研究人員利用了一種稱為“路徑級二值化”(path-level binarization)的技術,這種技術一次只存儲一個采樣路徑,并節省了一個數量級的內存消耗。他們將這種二值化與“path-level pruning”相結合,后者是一種傳統的技術,可以在不影響輸出的情況下學習刪除神經網絡中的哪些“神經元”。然而,他們提出的新NAS算法并不是丟棄神經元,而是修剪了整個路徑,這完全改變了神經網絡的結構。
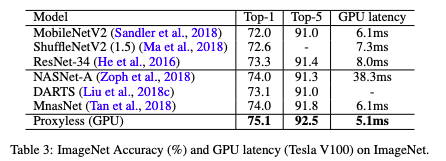
ImageNet上精度和延遲的結果
在訓練中,所有路徑最初都被賦予相同的選擇概率。然后,該算法跟蹤路徑——一次只存儲一個路徑——以記錄輸出的準確性和損失(對錯誤預測的數字懲罰)。然后,它調整路徑的概率,以優化精度和效率。最后,該算法修剪掉所有低概率路徑,只保留了概率最高的路徑——這就是最終的CNN架構。
硬件感知:測試延遲只需一部手機
韓松表示,該研究另一個關鍵的創新是使NAS算法具備“硬件感知”(hardware-aware),這意味著它將每個硬件平臺上的延遲作為反饋信號來優化架構。
例如,為了測量移動設備上的延遲,Google這樣的大公司會使用大量的移動設備,這是非常昂貴的。相反,研究人員構建了一個模型,只使用一部手機就能預測延遲。
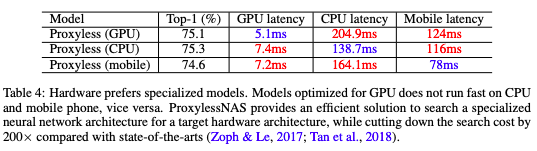
不同硬件的延遲結果
對于網絡的每個所選層,算法都對該延遲預測模型的架構進行采樣。然后,使用這些信息來設計一個盡可能快地運行的架構,同時實現高精度。在實驗中,研究人員的CNN在移動設備上的運行速度幾乎是標準模型的兩倍。
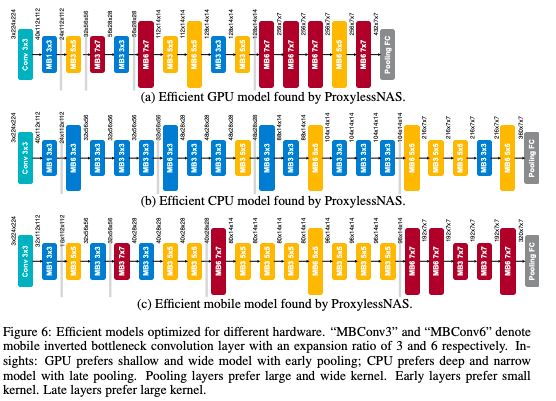
針對不同硬件優化的高效模型
韓松說,一個有趣的結果是,他們的NAS算法設計的CNN架構長期以來被認為效率太低,但在研究人員的測試中,它們實際上針對特定的硬件進行了優化。
例如,工程師基本上已經停止使用7x7過濾器,因為它們的計算成本比多個更小的過濾器更昂貴。然而,研究人員的NAS算法發現,具有部分7x7過濾器層的架構在GPU上運行得最快。這是因為GPU具有高并行性——意味著它們可以同時進行許多計算——所以一次處理一個大過濾器比一次處理多個小過濾器效率更高。
“這與人類以前的思維方式背道而馳,”韓松說。“搜索空間越大,你能找到的未知事物就越多。你不知道是否會有比過去的人類經驗更好的選擇。那就讓AI來解決吧。”
-
神經網絡
+關注
關注
42文章
4812瀏覽量
103281 -
自動化
+關注
關注
29文章
5769瀏覽量
83936 -
數據集
+關注
關注
4文章
1223瀏覽量
25377
原文標題:MIT華人助理教授新作:加快神經網絡設計自動化的步伐
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
百度搜索與文心智能體平臺接入DeepSeek及文心大模型深度搜索
什么是BP神經網絡的反向傳播算法
BitEnergy AI公司開發出一種新AI處理方法
一種新型全光學智能光譜儀





 工商網監
工商網監
評論