 TableBank:高質量的標注表格數據集
TableBank:高質量的標注表格數據集

近年來,自然語言處理(NLP,Natural Language Processing)技術的快速發展大力推動了人工智能的整體進展。尤其是在過去三年,機器學習給NLP所帶來的進步,使計算機在機器翻譯、閱讀理解、語法檢查等任務上,都達到了可以媲美人類的水平。
不過相比現實世界中的實際應用環境,研究中的NLP任務相對單純。事實上,在NLP已經取得很多突破的今天,機器卻連企業文檔中最常見的Word、PDF也無法從頭“讀”到尾。如何能夠讓機器理解文檔中的標題、段落、腳注、圖片、表格等內容信息,是NLP能夠處理更多實際應用場景的第一步。
最近,微軟亞洲研究院自然語言計算組發表了一篇論文——TableBank: Table Benchmark for Image-based Table Detection and Recognition,致力于解決文檔中的表格檢測與表格信息識別,并首次在業界同時開源表格檢測和表格結構識別數據集,供研究人員使用。
TableBank:高質量的標注表格數據集
雖然人類在視覺上可以很容易地判斷出一個表格,但由于表格的布局、樣式多種多樣,對于機器而言判斷“何為表格”以及表格中內容之間的關系卻并不容易。傳統的基于規則的表格識別方式,一旦換一份文檔就需要大量在文檔后臺的手工操作;而現有的機器學習方法,又無法獲得大量有效的標注數據,很難支持實際場景中的應用。于是,TableBank應運而生。
TableBank是一個表格檢測與識別的數據集,基于公開的、大規模的Word文檔和LaTex文檔,通過弱監督方法創建而來。與傳統的弱監督訓練集不同,TableBank不僅數據質量高,而且數據規模比之前的人工標記的表格分析數據集大幾個數量級,其表格數據量達到了41.7萬。
然而要讓機器讀懂表格,首先要能夠從文檔中識別哪些是表格,隨后再去識別表格區域內的信息。因此TableBank的實現主要分兩步走:一,表格檢測(Table Detection);二,表格結構識別(Table Structure Recognition)。
表格檢測
如何能自動檢測到文檔中的表格?
通常每個Word文檔都有一個對應的Office XML源代碼文件,在代碼中對應表格的位置,可以對其進行修改,讓表格加上邊框,以此來區分表格與文檔的其他部分。對于LaTex文檔(由LaTex編輯器生成的文檔),則可以直接使用特殊命令將邊界框添加到表格中,以此來確定表格在文檔中的位置。
然后再將Word和LaTex文檔中的表格轉化為相對應的PDF頁面(如下圖所示),便可獲得帶有表格信息的PDF頁面,且該文檔對表格的位置已經進行了標注。這些標注過的表格,都可以放到訓練數據集中,并且越來越多。目前,該表格檢測模型采用了計算機視覺研究中常用的Faster R-CNN 算法。

表格結構識別
表格結構識別的目的是識別表格文檔中的文字信息、表格中行和列的布局信息,以及理解行與列之間的關系。從PDF或圖像中識別出文字,大家的第一反應都是使用OCR(光學字符識別)技術,確實OCR技術可以識別出文字,但它只能將其轉換成文本格式,再按照在圖像中出現的先后順序依次填入到可編輯的文檔中,而無法確定文字之間的邏輯關系,更難于理解表格的行、列信息。
在TableBank的論文里,研究員們一方面結合OCR技術,識別出表格里每個單元格中的文本內容,另一方面,使用了創新方法去自動識別出表格在文檔中的位置,以及行與列的布局,明確表格中行列交叉所形成的單元格之間的關系。
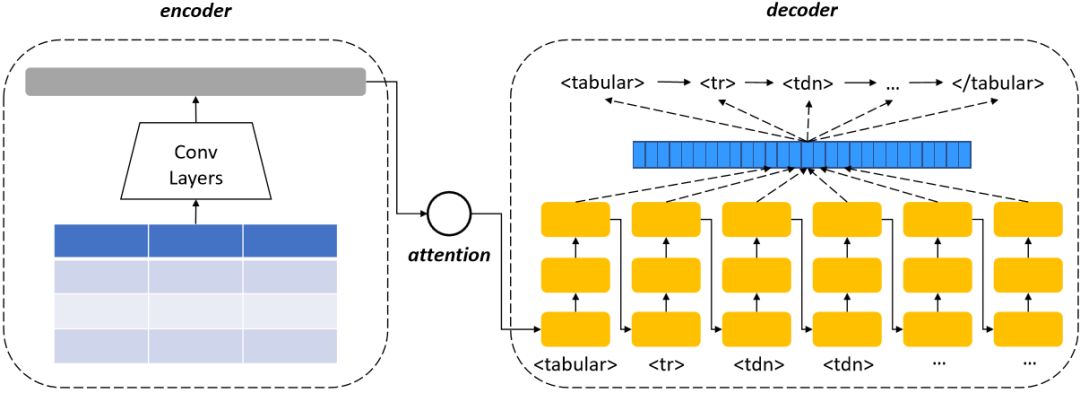
對于形式、來源不同的表格,研究員們給出了相應的方法來實現表格結構的識別。Word文檔中的表格可直接將XML源代碼文件轉換為HTML標記序列;LaTex文檔則先生成XML再轉換為HTML,然后框定表格中行和列的位置。這樣表格中的行、列信息也就有了標注數據。
目前,TableBank數據集已經在GitHub社區開源,其中表格檢測數據有41.7萬個,表格結構識別數據有14.5萬個。
數據集地址:https://github.com/doc-analysis/TableBank。
表格檢測與識別:文檔智能分析的第一步
高質量、大規模、帶有標注的表格數據集的建立,意味著表格識別相關的機器學習訓練可大規模開展,并將逐步提升表格識別的準確率。集成了計算機視覺、OCR等跨領域技術的TableBank為NLP在實際場景中的應用,做好了智能分析表格數據的前期準備。
未來,在企業文檔分析中,無論是掃描件還是紙質文件中的表格識別,都可以基于TableBank訓練的模型進行。同樣的場景也可以延伸到由PDF轉成Word的文檔中的表格轉換,企業年報、員工報銷發票中的表格信息提取等等。
當然,表格只是各類文檔中的一小部分,表格檢測與識別是NLP在文檔分析研究領域的第一步,文檔中的標題、段落、腳注、圖片等其他非結構化數據的檢測與識別,也是微軟亞洲研究院自然語言計算組的研究范疇。要想真正實現對文檔里的內容的智能分析和理解,還有很多研究課題亟待解決。
-
數據集
+關注
關注
4文章
1223瀏覽量
25386 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14113 -
nlp
+關注
關注
1文章
490瀏覽量
22578
原文標題:這是一份數據量達41.7萬開源表格數據集
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
MIND:高質量的新聞推薦數據集
要實現高質量AI診斷,需要大量的高質量標注圖像進行前期的算法訓練
如何構建高質量的大語言模型數據集
標貝科技“4D-BEV上億點云標注系統”入選國家數據局首批數據標注優秀案例






 工商網監
工商網監
評論