 谷歌研究人員利用3D卷積網絡打造視頻生成新系統
谷歌研究人員利用3D卷積網絡打造視頻生成新系統

谷歌研究人員利用3D卷積網絡打造視頻生成新系統,只需要視頻的第一幀和最后一幀,就能生成完整合理的整段視頻,是不是很神奇?
漫畫書秒變動畫片了解一下?
想象一下,現在你的手中有一段視頻的第一幀和最后一幀圖像,讓你負責把中間的圖像填進去,生成完整的視頻,從現有的有限信息中推斷出整個視頻。你能做到嗎?
這可能聽起來像是一項不可能完成的任務,但谷歌人工智能研究部門的研究人員已經開發出一種新系統,可以由視頻第一幀和最后一幀生成“似是而非的”視頻序列,這個過程被稱為“inbetween”。
“想象一下,如果我們能夠教一個智能系統來將漫畫自動變成動畫,會是什么樣子?如果真實現了這一點,無疑將徹底改變動畫產業。“該論文的共同作者寫道。“雖然這種極其節省勞動力的能力仍然超出目前最先進的水平,但計算機視覺和機器學習技術的進步正在使這個目標的實現越來越接近。”
原理與模型結構
這套AI系統包括一個完全卷積模型,這是是受動物視覺皮層啟發打造的深度神經網絡,最常用于分析視覺圖像。它由三個部分組成:2D卷積圖像解碼器,3D卷積潛在表示生成器,以及視頻生成器。
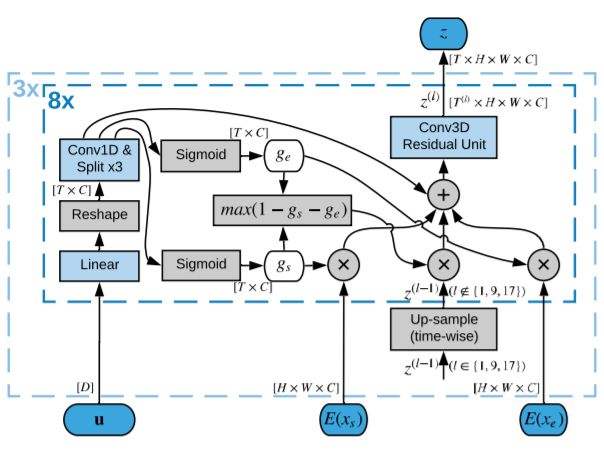
圖1:視頻生成模型示意圖
圖像解碼器將來自目標視頻的幀映射到潛在空間,潛在表示生成器學習對包含在輸入幀中的信息進行合并。最后,視頻生成器將潛在表示解碼為視頻中的幀。
研究人員表示,將潛在表示生成與視頻解碼分離對于成功實現中間視頻至關重要,直接用開始幀和結束幀的編碼表示生成視頻的結果很差。為了解決這個問題,研究人員設計了潛在表示生成器,對幀的表示進行融合,并逐步增加生成視頻的分辨率。
圖2:模型生成的視頻幀序列圖,對于每個數據集上方的圖表示模型生成的序列,下方為原視頻,其中首幀和尾幀用于生成模型的采樣。
實驗結果
為了驗證該方法,研究人員從三個數據集中獲取視頻 - BAIR機器人推送,KTH動作數據庫和UCF101動作識別數據集 - 并將這些數據下采樣至64 x 64像素的分辨率。每個樣本總共包含16幀,其中的14幀由AI系統負責生成。
研究人員為每對視頻幀運行100次模型,并對每個模型變量和數據集重復10次,在英偉達Tesla V100顯卡平臺上的訓練時間約為5天。結果如下表所示:

表1:我們報告了完整模型和兩個基線的平均FVD,對每個模型和數據集重復10次,每次運行100個epoch,表中FVD值越低,表示對應生成視頻的質量越高。
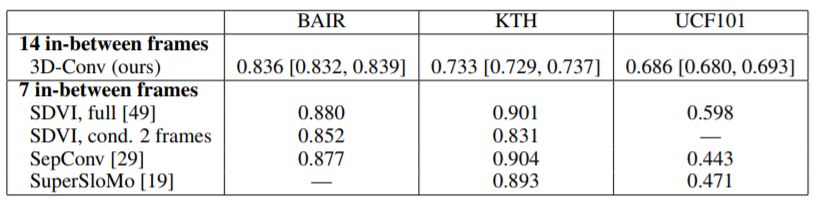
表2:使用直接3D卷積和基于的替代方法的模型的平均SSIM
RNN(SDVI)或光流(SepConv和SuperSloMo),數值越高越好。
研究人員表示,AI生成的視頻幀序列在風格上與給定的起始幀和結束幀保持一致,而且看上去說得通。“令人驚喜的是,這種方法可以在如此長的時間段內實現視頻生成,”該團隊表示,“這可能給未來的視頻生成技術研究提供了一個有用的替代視角。”
-
解碼器
+關注
關注
9文章
1166瀏覽量
41858 -
谷歌
+關注
關注
27文章
6231瀏覽量
107905 -
智能系統
+關注
關注
2文章
407瀏覽量
73232
原文標題:谷歌AI動畫接龍:只用頭尾兩幀圖像,片刻生成完整視頻!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
4K、多模態、長視頻:AI視頻生成的下一個戰場,誰在領跑?
NVIDIA助力影眸科技3D生成工具Rodin升級
騰訊混元3D AI創作引擎正式上線
阿里云通義萬相2.1視頻生成模型震撼發布
OpenAI暫不推出Sora視頻生成模型API
OpenAI推出AI視頻生成模型Sora
OpenAI開放Sora視頻生成模型
卷積神經網絡的實現工具與框架
字節跳動自研視頻生成模型Seaweed開放
今日看點丨Vishay裁員800人,關閉上海等三家工廠;字節跳動發布兩款視頻生成大模型
火山引擎推出豆包·視頻生成模型
阿里通義將發布視頻生成大模型
歡創播報 騰訊元寶首發3D生成應用






 工商網監
工商網監
評論