") 用Chiplet解決ASIC在LLM上的成本問題
用Chiplet解決ASIC在LLM上的成本問題

電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))雖說最近靠著GPT大語言模型的熱度,英偉達(dá)之類的主流GPU公司賺得盆滿缽滿,但要說仗著GPU的高性能就能高枕無憂的話,也就未免有些癡人說夢了。未來隨著LLM的繼續(xù)發(fā)展,訓(xùn)練與推理如果要花費(fèi)同樣的硬件成本,那么即便是大廠也難以負(fù)擔(dān)。
所以不少廠商都在追求如何削減TCO(總擁有成本)的辦法,有的從網(wǎng)絡(luò)結(jié)構(gòu)出發(fā),有的從自研ASIC出發(fā)的,但收效甚微,到最后還是得花大價(jià)錢購置更多的GPU。而來自華盛頓大學(xué)和悉尼大學(xué)的幾位研究人員,在近期鼓搗出的Chiplet Cloud架構(gòu),卻有可能顛覆這一現(xiàn)狀。
TCO居高不下的因素
對于大部分廠商來說,純粹的TCO并不是他們考慮的首要因素,他們更關(guān)注的是同一性能下如何實(shí)現(xiàn)更低的TCO。當(dāng)下,限制GPU在LLM推理性能上的主要因素之一,不是Tensor核心的利用率,而是內(nèi)存帶寬。
比如在更小的batch size和普通的推理序列長度下,內(nèi)存帶寬就會限制對模型參數(shù)的讀取,比如把參數(shù)從HBM加載到片上寄存器,因?yàn)槿B接層中的GeMM(通用矩陣乘)計(jì)算強(qiáng)度不高,幾乎每次計(jì)算都需要加載新的參數(shù)。
而Chiplet Cloud為了獲得更好的TCO與性能比,選擇了片上SRAM而不是HBM的外部內(nèi)存方案,將所有模型參數(shù)和中間數(shù)據(jù)(比如K和V向量等)緩存到片上內(nèi)存中去,從而實(shí)現(xiàn)了比傳統(tǒng)的DDR、HBM2e更好的單Token TCO表現(xiàn),同時(shí)也獲得了更大的內(nèi)存帶寬。
Chiplet Cloud,作為基于chiplet的ASIC AI超算架構(gòu),正是專為LLM減少生成單個(gè)Token所需的TCO成本設(shè)計(jì)的。從他們給出的評估數(shù)據(jù)對比來看,與目前主流的GPU和TPU對比,只有Chiplet Cloud對于TCO/Token做了極致的優(yōu)化。比如在GPT-3上,32個(gè)Chiplet Cloud服務(wù)器相較32個(gè)DGX A100服務(wù)器的TCO成本改善了94倍,在PaLM 540B上,30個(gè)Chiplet Cloud服務(wù)器相較64個(gè)TPUv4芯片將TCO改善了15倍。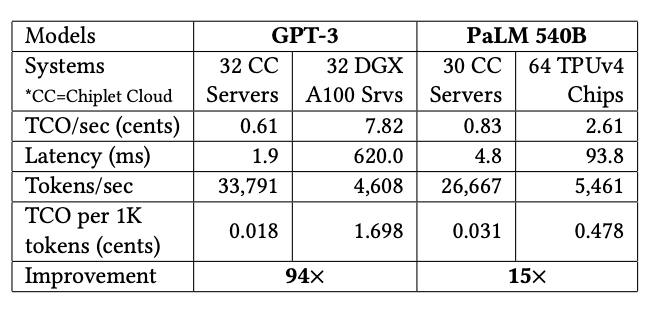
更靈活的Chiplet方案
為什么選擇Chiplet呢?我們先來看一個(gè)極端的堆片上內(nèi)存的例子,也就是直接選擇晶圓級的“巨芯”,比如Cerebras Systems打造的WSE-2芯片。該芯片基于7nm工藝下的一整片12英寸晶圓打造,集成了2.6萬億個(gè)晶體管,面積達(dá)到46255mm2,片上內(nèi)存更是達(dá)到了40GB。
但這樣的巨芯設(shè)計(jì)意味著高昂的制造成本,所以Chiplet Cloud的研究人員認(rèn)為更大的SRAM應(yīng)該與相對較小的芯片對應(yīng),這樣才能減少制造成本,所以他們選擇了chiplet的設(shè)計(jì)方式。近來流行的Chiplet方案提高了制造良率,也減少了制造成本,允許在不同的系統(tǒng)層級上進(jìn)行設(shè)計(jì)的重復(fù)利用。
以臺積電7nm工藝為例,要想做到0.1/cm2的缺陷密度,一個(gè)750mm2芯片的單價(jià)是一個(gè)150mm2芯片單價(jià)的兩倍,所以Chiplet的小芯片設(shè)計(jì)成本更低。重復(fù)利用的設(shè)計(jì)也可以進(jìn)一步降低成本,加快設(shè)計(jì)周期,為ASIC芯片提供更高的靈活性。
Chiplet Cloud更適合哪些廠商
雖然論文中提到了不少Chiplet Cloud的優(yōu)點(diǎn),但這依然是一個(gè)尚未得到實(shí)際產(chǎn)品驗(yàn)證的架構(gòu),擁有驗(yàn)證實(shí)力的公司往往也只有微軟、谷歌、亞馬遜以及阿里巴巴這類具備芯片設(shè)計(jì)實(shí)力的公司。況且ASIC終究是一種特化的方案,最清楚云平臺計(jì)算負(fù)載需要哪些優(yōu)化,還得是云服務(wù)廠商自己。
-
芯片
+關(guān)注
關(guān)注
459文章
52414瀏覽量
439452 -
asic
+關(guān)注
關(guān)注
34文章
1245瀏覽量
122259 -
chiplet
+關(guān)注
關(guān)注
6文章
454瀏覽量
12957 -
LLM
+關(guān)注
關(guān)注
1文章
325瀏覽量
803
發(fā)布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實(shí)踐

無法在OVMS上運(yùn)行來自Meta的大型語言模型 (LLM),為什么?
小白學(xué)大模型:構(gòu)建LLM的關(guān)鍵步驟

Neuchips展示大模型推理ASIC芯片
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

Chiplet技術(shù)有哪些優(yōu)勢
什么是LLM?LLM在自然語言處理中的應(yīng)用
LLM技術(shù)對人工智能發(fā)展的影響
LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
IMEC組建汽車Chiplet聯(lián)盟

創(chuàng)新型Chiplet異構(gòu)集成模式,為不同場景提供低成本、高靈活解決方案
將ASIC IP核移植到FPGA上——更新概念并推動(dòng)改變以完成充滿挑戰(zhàn)的任務(wù)!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論