") 恩智浦eIQ Time Series Studio工具使用教程之模型訓(xùn)練
恩智浦eIQ Time Series Studio工具使用教程之模型訓(xùn)練

大家好,eIQ Time SeriesStudio又和大家見面啦!本章為大家?guī)砉ぞ吆诵牟糠?模型訓(xùn)練。
Training模塊,用于Dataset模塊加載數(shù)據(jù)集后的模型訓(xùn)練。Training功能是核心技術(shù),包括數(shù)據(jù)預(yù)處理、算法超參數(shù)自動化搜索、基準測試以及針對有限的Flash和RAM大小進行最佳精度擬合優(yōu)化。模型性能也可以通過各種基準指標進行評估。
功能布局
下圖顯示了“Training”模塊的布局,分為三個部分:
左側(cè)框架顯示了訓(xùn)練的所有記錄
中間的框架顯示了訓(xùn)練的配置信息和優(yōu)化過程
右側(cè)框架顯示了指定模型的驗證集的基準結(jié)果
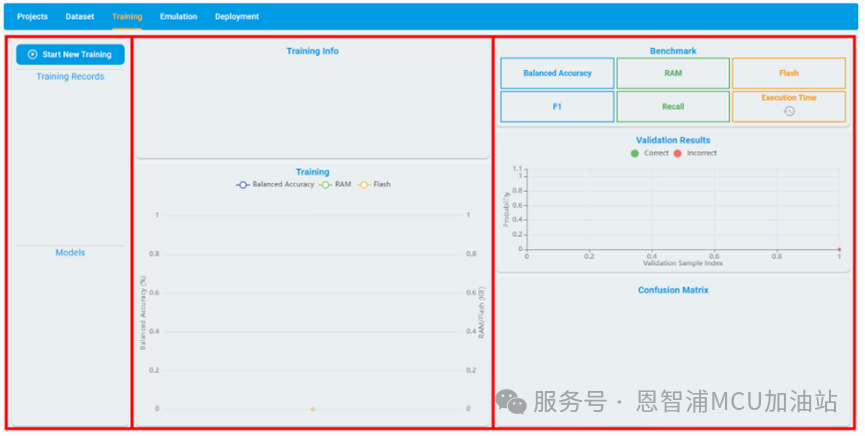
左側(cè)框包含兩部分:Training Records和Models。
Training Records:記錄了用戶創(chuàng)建的所有訓(xùn)練任務(wù)。
Models:記錄了特定訓(xùn)練任務(wù)生成的算法模型;默認情況下,模型按得分降序排列。得分取決于 RAM/Flash 占用大小以及基準測試的一些常見評估指標。
中間框包含兩部分:Training Info和Training。
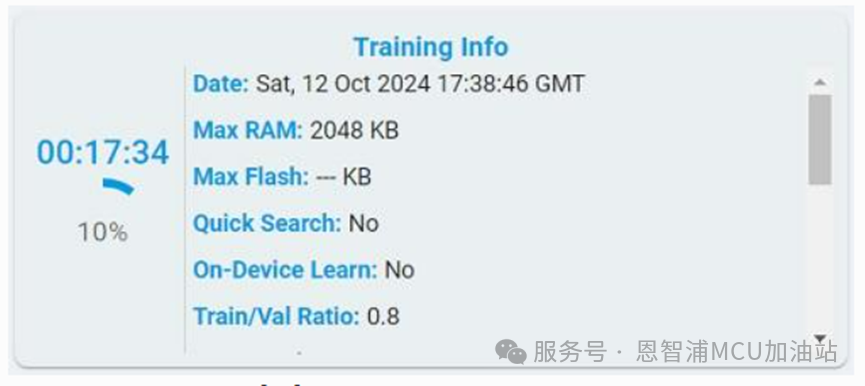
Training Info:記錄了訓(xùn)練的時間、進度和配置信息,包括日期、最大 RAM、最大 Flash、是否使用快速搜索、on-Device learn(僅用于異常檢測)、訓(xùn)練/驗證集比例和訓(xùn)練所用的數(shù)據(jù)文件。
Training:記錄了自動機器學(xué)習(xí)的平衡準確率、Flash 和 RAM 使用的變化曲線。
右側(cè)框架中的信息因不同的任務(wù)類型而異,將在后續(xù)內(nèi)容中詳細介紹(基準信息)。
訓(xùn)練過程
介紹如何開始、暫停、停止和管理訓(xùn)練。
點擊“Start New Training”按鈕,會出現(xiàn)一個彈框供用戶配置。在點擊“Start”按鈕之前,請檢查針對不同算法任務(wù)可配置的選項。通常,用戶可以在不更改配置的情況下進行訓(xùn)練并獲得最佳結(jié)果。
配置選項
異常檢測的配置選項如下。異常檢測算法基于半監(jiān)督機器學(xué)習(xí),它支持在設(shè)備上進行增量學(xué)習(xí)。
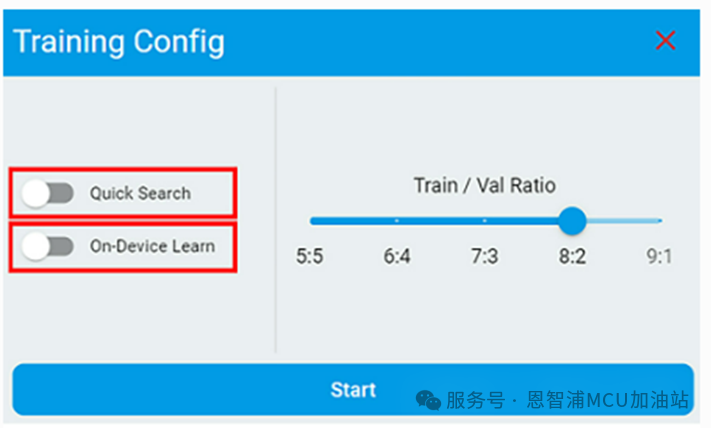
如果算法僅用于預(yù)測,請不要使能“On-Device Learn”這將會導(dǎo)致更大的 RAM/Flash占用
如果使用的數(shù)據(jù)集存在變化,可以啟用“On-Device Learn”以允許在設(shè)備上進行訓(xùn)練
如果想快速獲得訓(xùn)練結(jié)果,請啟用“Quick Search”。此模式的搜索范圍不如默認模式大
以下是分類和回歸的配置選項:
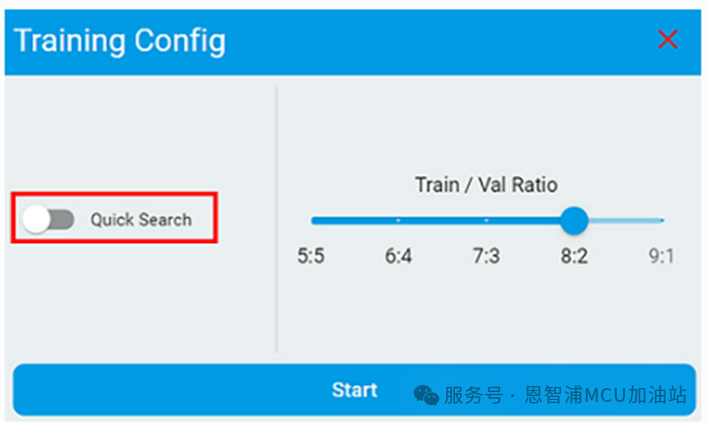
共同的選項:
配置Train/Val Ratio,如果train/emulation準確率不匹配或超出范圍,則調(diào)整數(shù)據(jù)文件中訓(xùn)練集和驗證集的比例并再次訓(xùn)練和仿真。
訓(xùn)練配置完成或設(shè)置為默認值后,單擊“Start”按鈕開始訓(xùn)練,等待訓(xùn)練完成。
完成培訓(xùn)的時間取決于:
數(shù)據(jù)集的大小
選擇了什么樣的算法任務(wù)
不同的訓(xùn)練配置也可能導(dǎo)致不同的時間開銷
訓(xùn)練開始時,訓(xùn)練進度條會不斷更新,計時器會一直計時,直到100%完成。
暫停/停止訓(xùn)練 在訓(xùn)練過程中,可以選擇點擊“Stop”按鈕停止訓(xùn)練或點擊“Pause”按鈕暫停訓(xùn)練,左側(cè)模型列表中存在的算法,可以被使用。
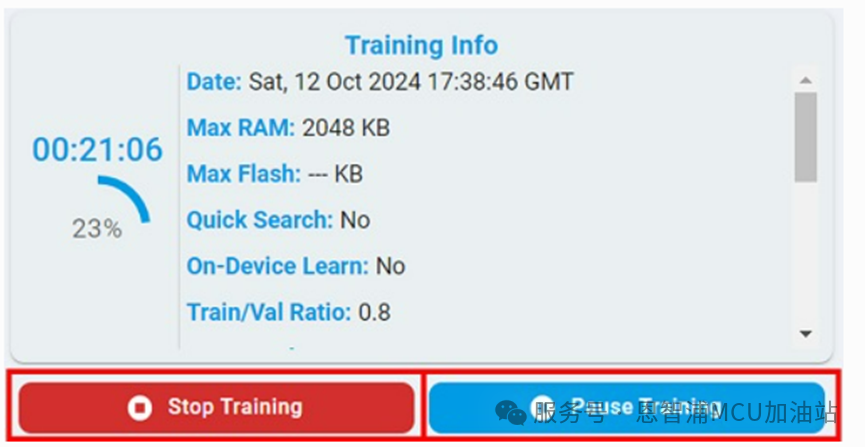
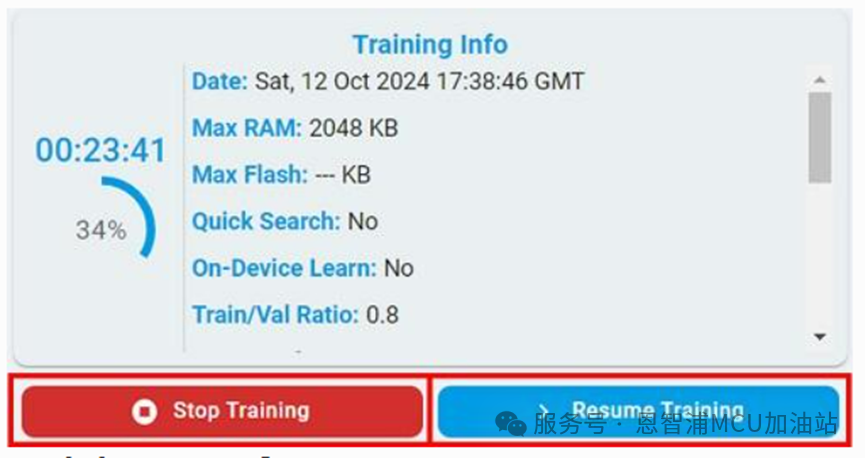
暫停后,可以在左側(cè)模型列表中查看任意模型的訓(xùn)練結(jié)果,或者點擊“Resume”按鈕繼續(xù)訓(xùn)練。
訓(xùn)練記錄管理
任務(wù)完成后,此次的訓(xùn)練信息將被記錄到訓(xùn)練記錄中,訓(xùn)練出的算法模型將會按照性能排序出現(xiàn)在模型列表中。
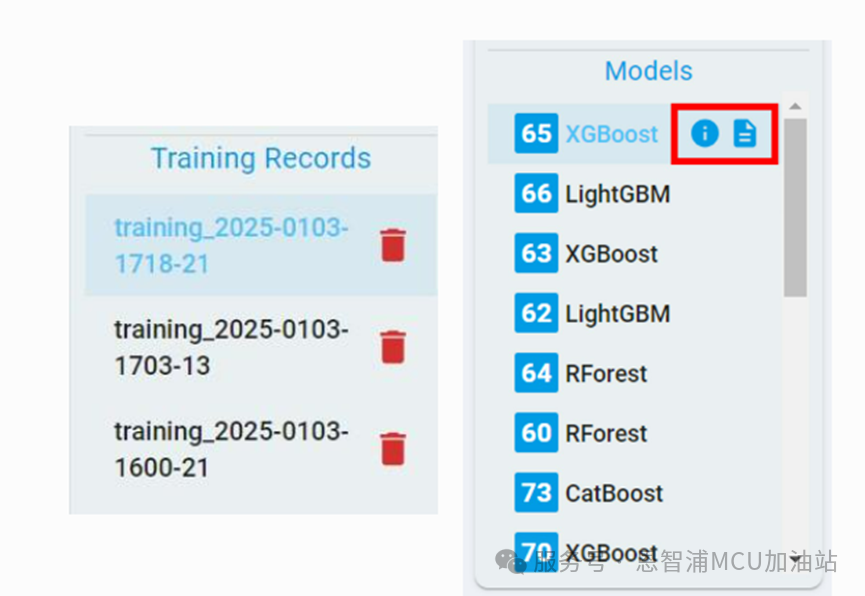
點擊“flowchart”和“report”按鈕,查看或下載相應(yīng)模型的流程圖和報告,以供進一步參考。
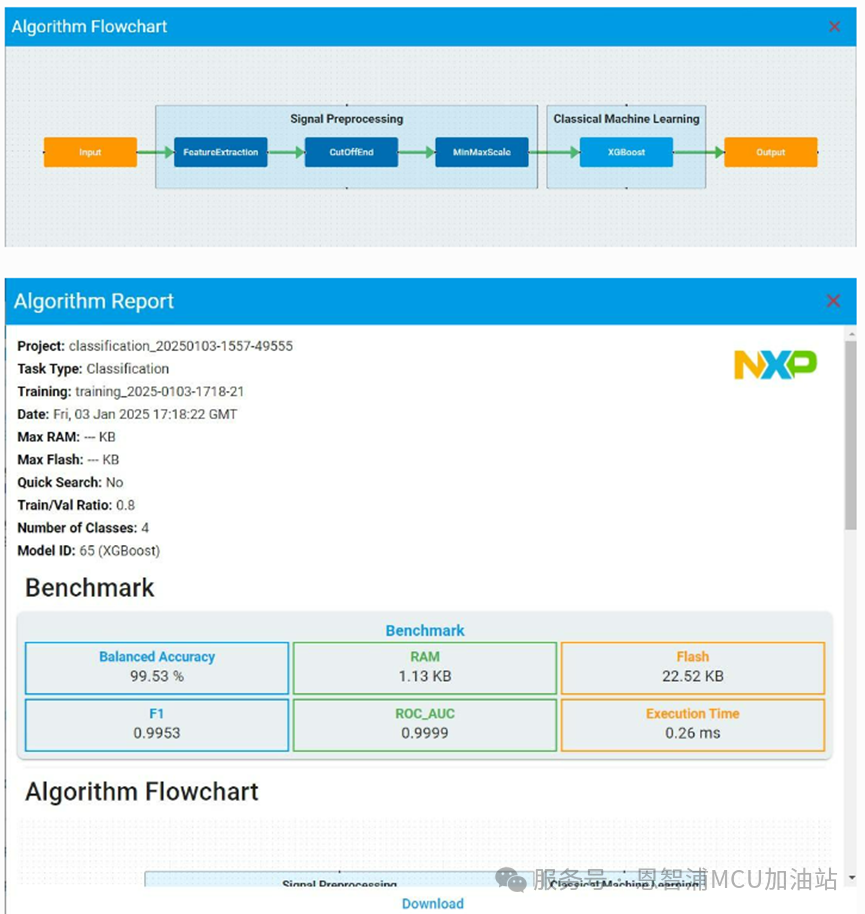
從列表中選擇任意算法并點擊,可獲取如下基準詳細信息。在訓(xùn)練圖中,紫色箭頭坐標指示當(dāng)前選定的算法模型,用戶可以查看自動機器學(xué)習(xí)訓(xùn)練曲線以及每個模型對應(yīng)的平衡準確率、Flash和RAM使用情況。
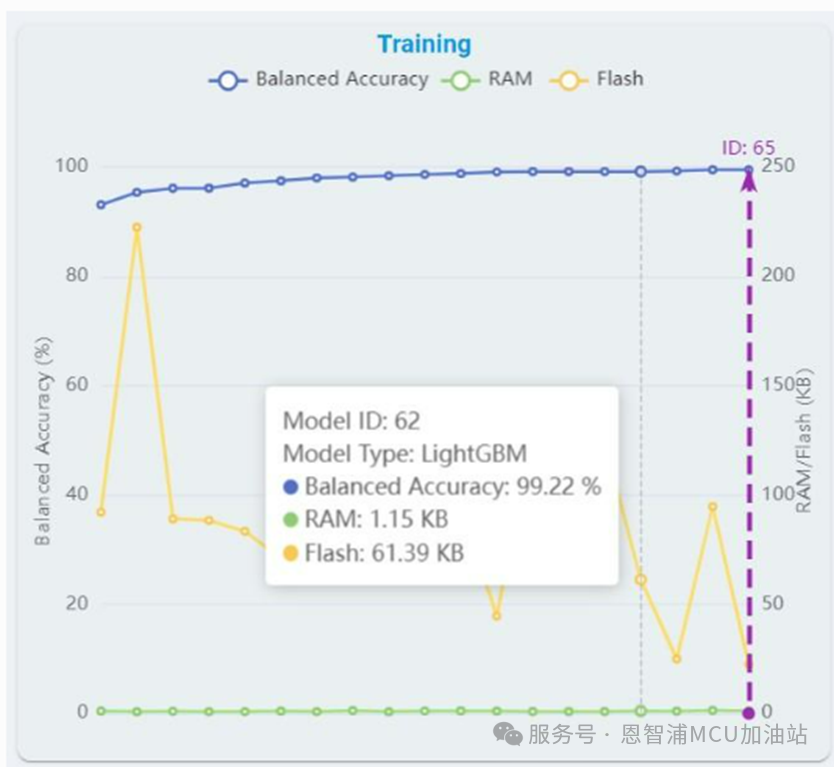
另外,可以點擊“Delete”按鈕刪除相應(yīng)的訓(xùn)練記錄,刪除后該訓(xùn)練記錄下的所有模型信息也會同時被刪除。
模型列表與代碼許可
為了滿足用戶對算法透明度的要求,我們會根據(jù)發(fā)布版本保持所有支持模型的列表更新:
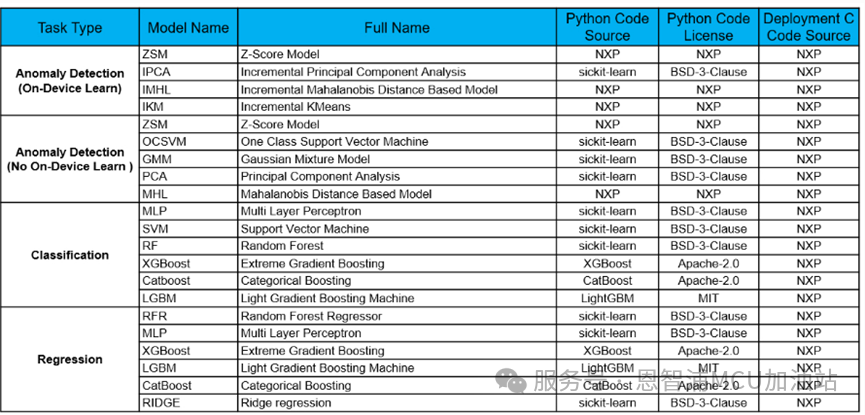
該表格重點展示了以下信息:
每項任務(wù)對應(yīng)的模型
用于訓(xùn)練的Python代碼源
Python代碼的許可證類型
C代碼來源
基準信息
支持時間序列的數(shù)據(jù)集的算法有三類,分別是異常檢測、分類和回歸。基準信息因算法類型的不同而不同。
異常檢測基準信息

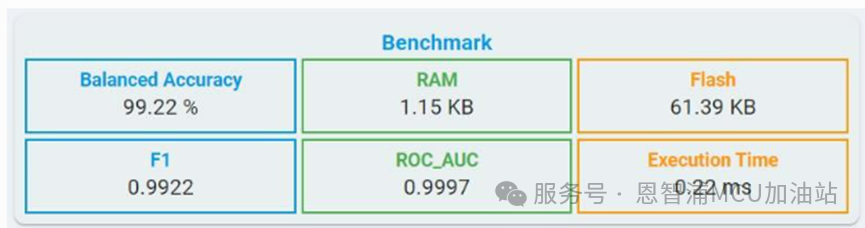
Balanced Accuracy: 從類別中獲得平衡準確率。
F1: F1分數(shù)是反映分類器全局性能的指標,其值范圍為0到1。
Recall:召回率是分類器找出所有正樣本的能力,值的范圍是0~1。
Flash:所選算法所需的最小Flash。
RAM:所選算法所需的最小RAM.
Execution Time: 基于LPC55S36(Cortex-M33,150 MHz,啟用硬浮點)平臺進行一次推理的估計時間,同時您可以通過點擊時鐘按鈕來獲取執(zhí)行時間。
將鼠標懸浮在指標上,可查看它的解釋說明和對應(yīng)的計算公式。
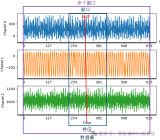
驗證集結(jié)果分析:
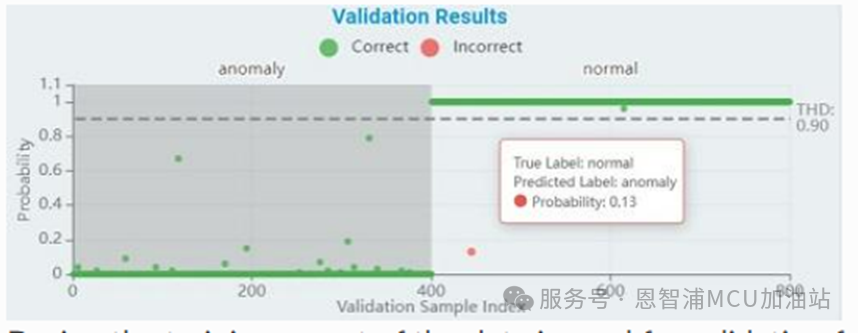
在訓(xùn)練過程中,部分數(shù)據(jù)會不時用于驗證。訓(xùn)練曲線反映了這些結(jié)果,并作為準確性指標來衡量模型的性能。
x 軸表示驗證樣本的索引(對于異常檢測,所有樣本都用于驗證,而分類則根據(jù)訓(xùn)練/驗證比例來驗證)
y 軸表示概率,其值標準化為0到1之間
綠點表示預(yù)測正確的樣本點,紅色表示預(yù)測異常的樣本點
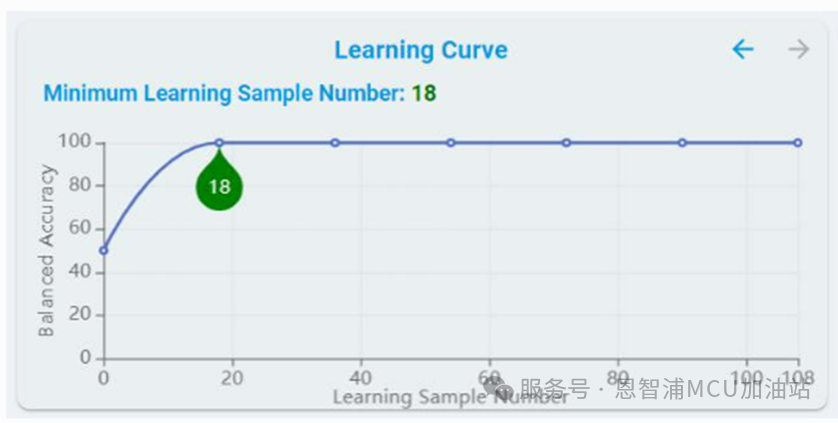
學(xué)習(xí)曲線:
對于支持“On-DeviceLearn”的模型,提供了學(xué)習(xí)曲線,展示了在訓(xùn)練過程中添加更多樣本的效果。
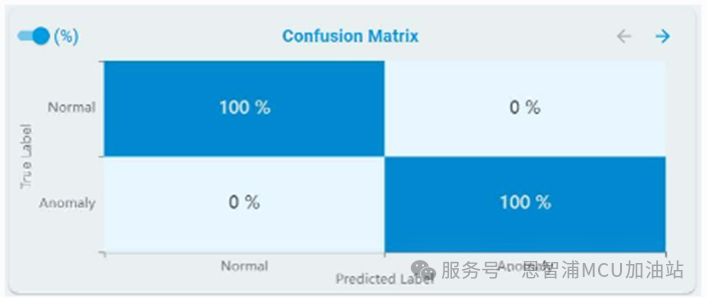
混淆矩陣:
對于異常檢測,混淆矩陣表包含正常和異常結(jié)果:

同時,您可以通過點擊百分比(%)按鈕來獲取百分比結(jié)果:
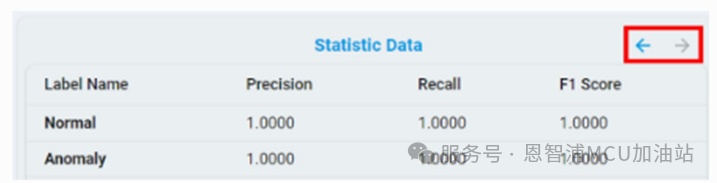
也可以通過點擊箭頭按鈕來查看統(tǒng)計結(jié)果:
分類算法基準信息 對于分類任務(wù),一些評估指標與異常檢測一致,例如平衡準確率、RAM、Flash和F1。
混淆矩陣:
對于分類,混淆矩陣表重新縮放以適應(yīng)所有類別,如下圖所示:

回歸算法基準信息
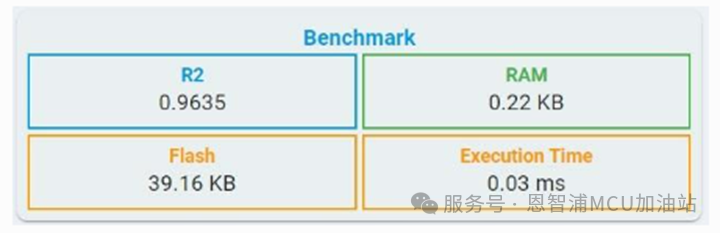
R2:決定系數(shù):
其公式可在回歸仿真指標部分找到。
算法驗證結(jié)果:
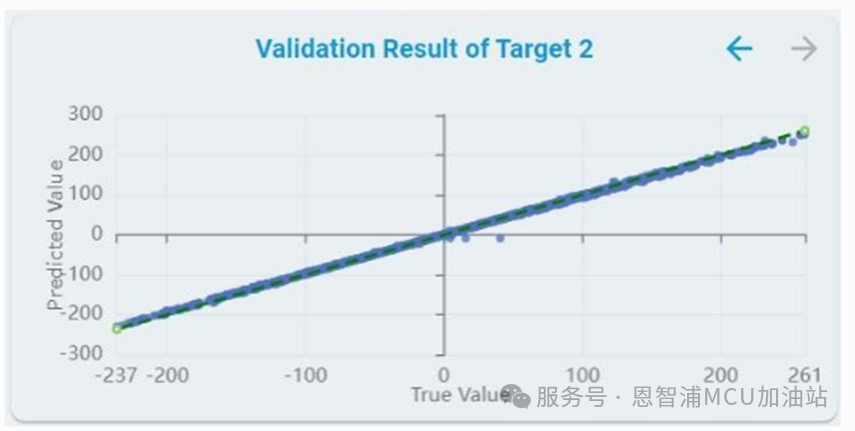
對每個target,都繪制了驗證集的預(yù)測目標值。
x軸表示驗證樣本的索引。訓(xùn)練/驗證比例決定了用于驗證的樣本數(shù)量
y軸表示預(yù)測值
虛線表示真實值
評估指標:
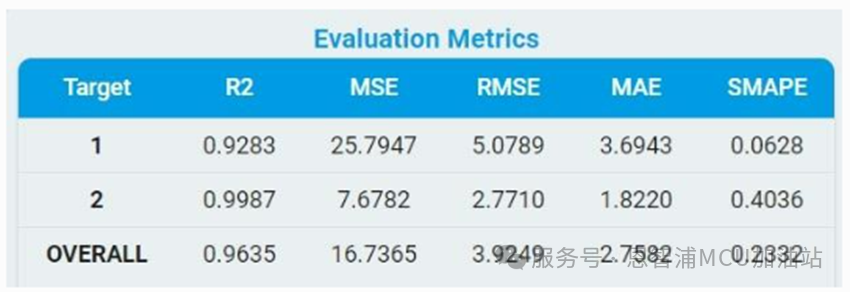
對于回歸任務(wù),給出了所有回歸目標的MSE、RMSE、MAE、R2和SMAPE值。
MSE:均方誤差
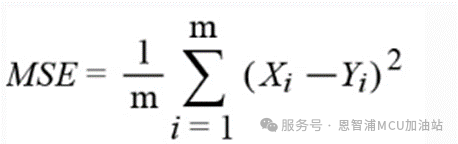
RMSE:均方根誤差
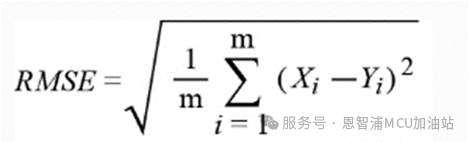
MAE:平均絕對誤差
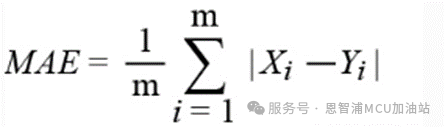
R2:決定系數(shù)
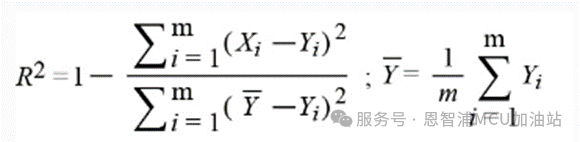
SMAPE:對稱平均絕對百分比誤差
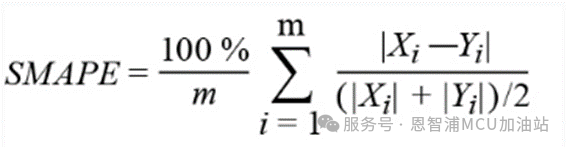
*注:公式中Yi 是第i個樣本點的真實值,Xi 為第i個樣本點的預(yù)測值。
-
恩智浦
+關(guān)注
關(guān)注
14文章
5964瀏覽量
115080 -
算法
+關(guān)注
關(guān)注
23文章
4705瀏覽量
95137 -
模型
+關(guān)注
關(guān)注
1文章
3506瀏覽量
50234 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134368
原文標題:eIQ Time Series Studio工具使用攻略(五)-模型訓(xùn)練
文章出處:【微信號:NXP_SMART_HARDWARE,微信公眾號:恩智浦MCU加油站】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
恩智浦eIQ Time Series Studio工具使用教程之數(shù)據(jù)記錄
如何訓(xùn)練一個有效的eIQ基本分類模型

恩智浦eIQ Time Series Studio 工具使用全攻略
恩智浦 eIQ Time Series Studio 工具使用攻略(七)-部署
NXP eIQ Time Series Studio 工具使用攻略(九)-數(shù)據(jù)標簽
恩智浦eIQ Time Series Studio工具使用教程之數(shù)據(jù)智能
恩智浦eIQ Time Series Studio工具使用教程之數(shù)據(jù)操作
恩智浦最新的應(yīng)用處理器 i.MX 95采用專有NPU IP進行片上AI加速
恩智浦eIQ? Neutron神經(jīng)處理單元
如何使用eIQ門戶訓(xùn)練人臉檢測模型?
防范機器學(xué)習(xí)IP失竊,恩智浦推出一款“防偷”神器!
NVIDIA TAO工具套件功能與恩智浦eIQ機器學(xué)習(xí)開發(fā)環(huán)境的集成
恩智浦eIQ AI和機器學(xué)習(xí)開發(fā)軟件增加兩款新工具
eIQ Time Series Studio工具使用教程
恩智浦eIQ Time Series Studio工具使用教程之仿真





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論