 先進封裝技術:3.5D封裝、AMD、AI訓練降本
先進封裝技術:3.5D封裝、AMD、AI訓練降本

隨著深度神經網絡(DNN)和機器學習(ML)模型參數數量的指數級增長,AI訓練和推理應用對計算資源(如CPU、GPU和內存)的需求不斷增加。
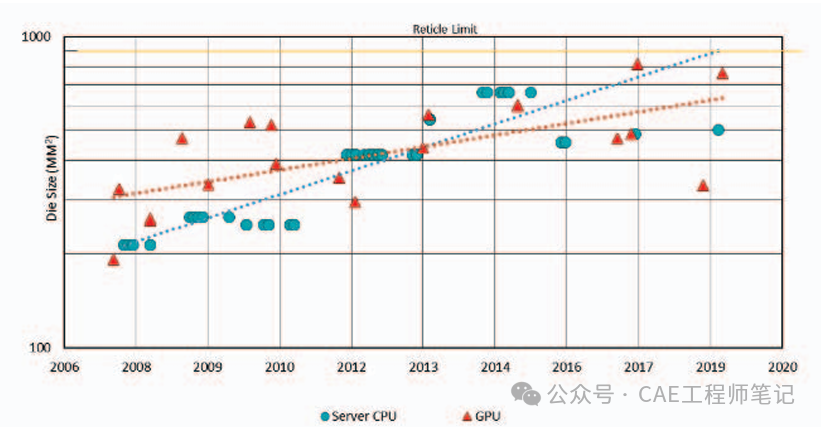
摩爾定律的放緩使得傳統單片系統芯片(SoC)的性能提升受限,而芯片級架構通過將SoC分解為多個小芯片(chiplets),利用先進封裝技術實現高性能和低成本。
芯片級架構通過將傳統單片系統芯片(SoC)分解為多個小芯片(chiplets),利用先進封裝技術實現高性能和低成本。
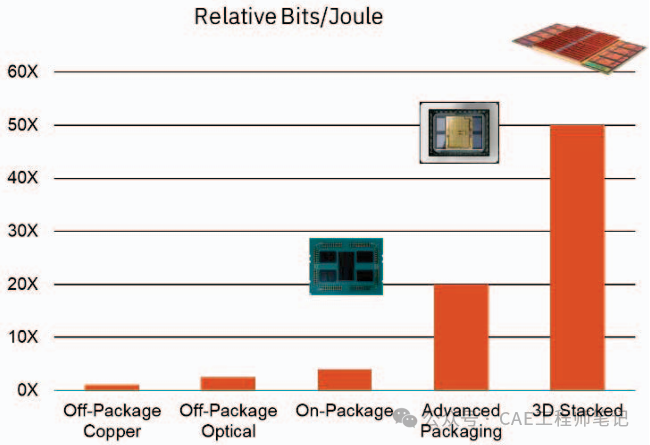
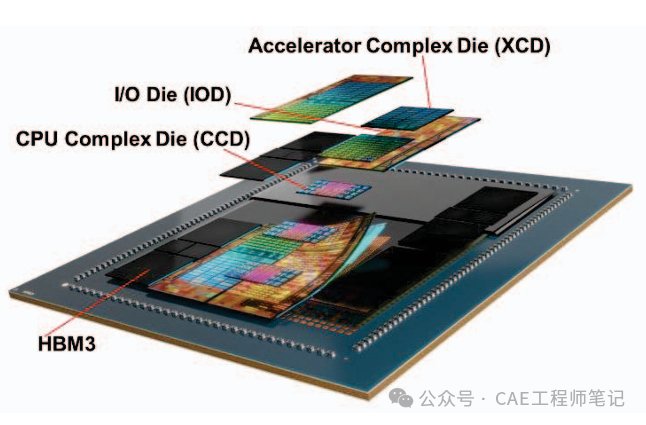
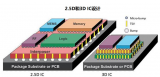
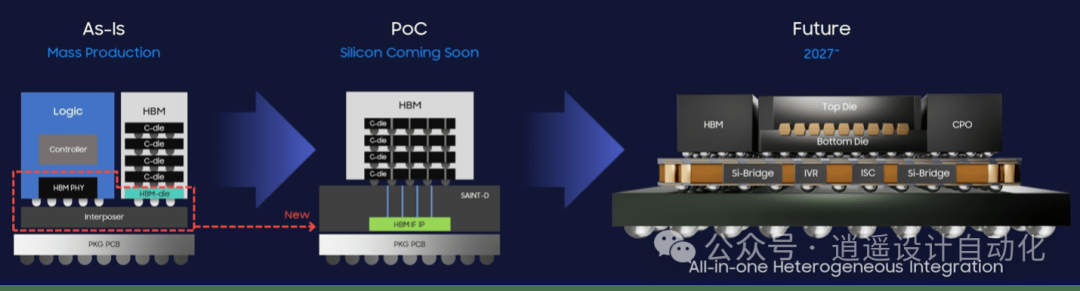
3.5D封裝結合了2.5D和3D封裝技術的優點,通過硅中介層將多個3D堆疊芯片(如CPU、GPU、HBM等)連接在一起。
3.5D封裝技術最簡單的理解就是3D+2.5D,通過垂直堆疊芯片并使用銅-銅混合鍵合技術,實現了更高的性能和密度,創造了一種新的架構。能夠縮短信號傳輸的距離,大幅提升處理速度,這對于人工智能和大數據應用尤為重要。
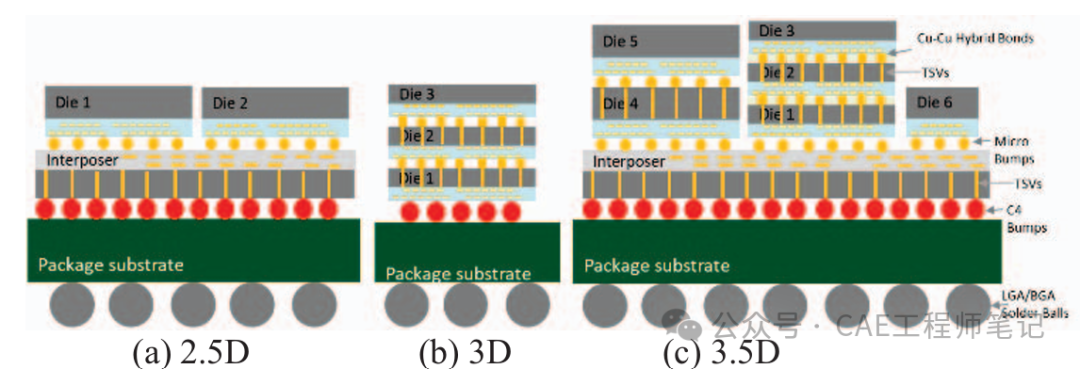
2.5D封裝:多個芯片并排放置,通過硅中介層或高密度橋接實現芯片間互連。
3D封裝:多個芯片垂直堆疊,通過銅-銅混合鍵合或微凸點(μbump)實現互連。
3.5D創新:將3D堆疊芯片與2.5D硅中介層結合,實現更高密度的互連。
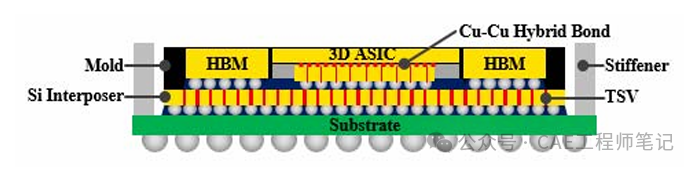

混合鍵合(Hybrid Bonding)技術成為關鍵使能者,其特點包括:
微縮互連間距:將傳統40μm凸點間距縮小至1μm級
三維互連密度:單位面積互連通道提升10倍以上
熱管理優化:減少界面材料層,提升散熱效率
3.5D封裝技術的關鍵優勢在于:
高帶寬與低功耗:3D混合鍵合技術提供了比傳統μbump互連更高的互連密度和更低的功耗。
系統級效率:通過緊密集成不同功能的芯片,減少了數據傳輸的延遲和功耗。
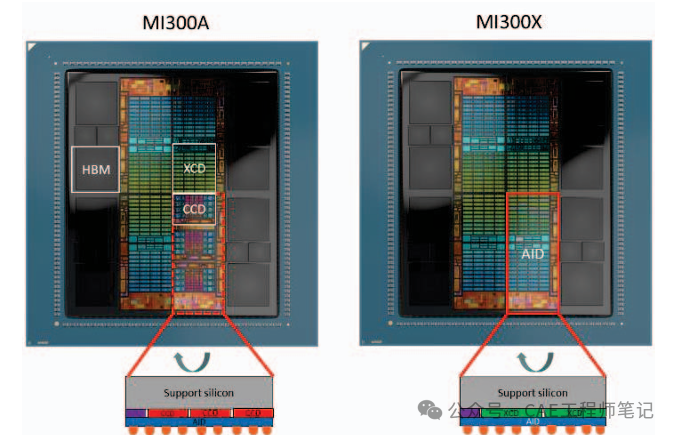
模塊化設計:允許靈活配置不同的芯片組合,如MI300A(CPU+GPU)和MI300X(純GPU)。
AMD的3.5D封裝技術與AI加速器性能提升
AMD的3.5D技術通過結合2.5D和3D封裝技術的優勢,實現了高性能計算(HPC)和人工智能(AI)加速器的異構集成。具體來說,AMD的3.5D技術利用了以下三種關鍵技術來實現異構集成:
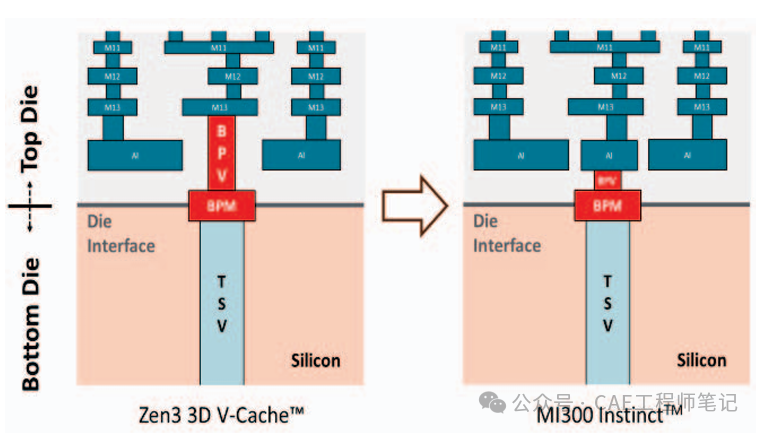
1.直接銅-銅混合鍵合(Cu-Cu Hybrid Bonding)
銅-銅混合鍵合技術是實現3D堆疊芯片之間高密度、低功耗互連的關鍵。AMD在MI300X Instinct加速器中使用了銅-銅混合鍵合技術,將多個CPU或GPU芯片垂直堆疊在一起。這種技術的主要優勢包括:
高互連密度:相比傳統的微凸點(μbump)技術,銅-銅混合鍵合可以實現更高的互連密度,從而顯著提高芯片之間的數據傳輸速率。
低功耗:銅-銅混合鍵合技術能夠降低互連的功耗,提高系統的能效。
低延遲:由于互連距離的縮短,數據傳輸延遲也相應降低。
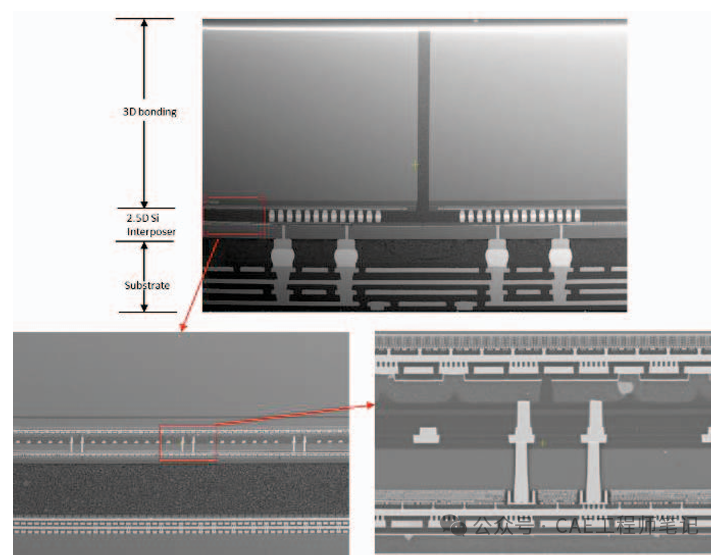
2.2.5D集成在大型硅中介層上
AMD開發了一種大型硅中介層(Silicon Interposer),用于連接多個3D堆疊芯片和其他組件。硅中介層的主要作用包括:
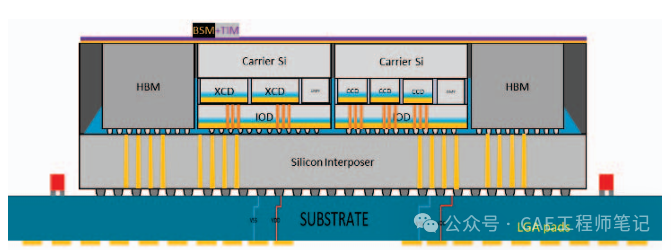
高帶寬互連:通過硅中介層,可以實現多個芯片之間的高速互連。例如,AMD的MI300X加速器使用了2.5D硅中介層來連接3D堆疊的CPU/GPU芯片、高帶寬存儲器(HBM)和無源元件。
模塊化設計:硅中介層允許將不同的功能模塊(如CPU、GPU、HBM等)集成到一個封裝中,從而實現靈活的系統設計。例如,MI300A和MI300X是兩種不同的產品配置,分別針對高性能計算(HPC)和人工智能(AI)應用進行了優化。
擴展性:大型硅中介層可以容納更多的芯片和組件,從而支持更復雜的系統集成。AMD的MI300X加速器使用了約3000mm2的硅中介層,是光刻掩模面積的3.6倍。
3.基于金屬熱界面材料(TIM)的冷卻解決方案
為了確保高性能計算和人工智能應用中的散熱需求,AMD采用了金屬熱界面材料(TIM)來提高散熱效率。這種冷卻解決方案的主要特點包括:
高效散熱:金屬TIM材料具有較高的熱導率,能夠有效傳導熱量,確保芯片在高負載下的穩定運行。
可靠性:金屬TIM材料在高溫和長時間運行中表現出良好的可靠性,能夠滿足高性能計算和人工智能應用的需求。
AMD的3.5D技術為高性能計算和人工智能應用提供了一種高效、靈活且可靠的解決方案,顯著提升了系統的性能和能效。
高性能:通過高密度的銅-銅混合鍵合和2.5D硅中介層,實現了CPU、GPU和HBM之間的高速互連,顯著提高了系統的性能。
高能效:銅-銅混合鍵合技術降低了互連功耗,提高了系統的能效。
靈活性:模塊化設計允許根據不同的應用需求進行定制,如MI300A和MI300X分別針對HPC和AI應用進行了優化。
擴展性:大型硅中介層可以容納更多的芯片和組件,支持更復雜的系統集成。
AMD的3.5D技術在AI加速器性能提升方面表現顯著,主要體現在以下幾個關鍵方面:
1.計算性能提升
更高的互連密度:通過銅-銅混合鍵合技術,3.5D技術實現了比傳統微凸點(μbump)技術更高的互連密度。這使得CPU、GPU和內存之間的數據傳輸速率大幅提高,從而顯著提升了計算性能。
多芯片集成:3.5D技術允許將多個CPU或GPU芯片垂直堆疊在一起,形成3D堆疊結構。這種結構不僅提高了計算密度,還通過縮短互連距離降低了延遲。例如,AMD的MI300X加速器通過3D堆疊技術集成了多個GPU芯片,顯著提升了并行計算能力。
2.內存帶寬提升
高帶寬存儲器(HBM)集成:3.5D技術通過2.5D硅中介層將高帶寬存儲器(HBM)與CPU/GPU緊密集成在一起。HBM提供了極高的內存帶寬,這對于AI訓練和推理任務中的大規模并行數據操作至關重要。例如,MI300X加速器支持高達5324.8 GB/s的HBM3峰值內存帶寬,相比上一代產品(如MI250X)提升了約62%。
統一內存架構:在MI300A加速器中,CPU和GPU共享統一的HBM內存空間,消除了傳統APU中CPU和GPU使用不同內存類型導致的數據傳輸延遲和冗余內存拷貝問題。這種統一內存架構簡化了HPC編程,提高了數據傳輸效率。
3.能效提升
低功耗互連:銅-銅混合鍵合技術不僅提高了互連密度,還顯著降低了互連功耗。相比傳統的μbump技術,銅-銅混合鍵合技術可以實現更高的能效比。
模塊化設計:3.5D技術的模塊化設計允許根據不同的應用需求進行靈活配置,從而在性能和功耗之間實現更好的平衡。例如,MI300A和MI300X分別針對HPC和AI應用進行了優化,以滿足不同的性能和功耗需求。
4.系統級性能提升
緊密集成:3.5D技術通過將多個功能模塊(如CPU、GPU、HBM等)緊密集成在一個封裝內,減少了芯片之間的通信延遲,提高了系統的整體性能。
更高的計算密度:通過3D堆疊和2.5D硅中介層的結合,3.5D技術在相同的封裝尺寸內集成了更多的計算資源,從而提高了計算密度和性能。
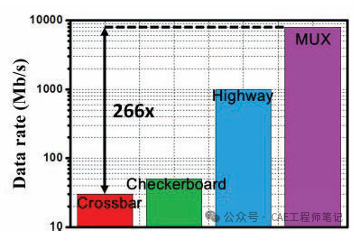
AI加速器性能提升具體數據:
矩陣FMA FP16 KOPS/CLK:MI300X加速器相比上一代MI250X加速器,矩陣FMA FP16 KOPS/CLK性能提升了2.5倍。
HBM容量和帶寬:MI300X加速器的HBM容量和峰值帶寬相比MI250X提升了1.5倍。
系統級性能:MI300X加速器在AI訓練和推理任務中的整體性能顯著提升,特別是在處理大規模并行數據操作時表現尤為突出。
AMD的3.5D技術通過高密度互連、多芯片集成、高帶寬內存和模塊化設計,顯著提升了AI加速器的性能。具體來說,3.5D技術在計算性能、內存帶寬和能效方面都取得了顯著的提升,使得AI加速器能夠更高效地處理復雜的AI訓練和推理任務。這種技術不僅提高了系統的整體性能,還為未來的高性能計算和人工智能應用提供了強大的支持。
3.5D封裝與AI訓練降本
3.5D技術通過多種方式降低了AI訓練的成本,主要體現在硬件設計、制造成本、功耗和運營成本等方面。
1.硬件設計與制造成本
模塊化設計:3.5D技術采用模塊化設計,允許將不同的功能模塊(如CPU、GPU、HBM等)集成到一個封裝中。這種設計不僅提高了系統的靈活性,還降低了開發和制造成本。例如,AMD的MI300A和MI300X加速器分別針對HPC和AI應用進行了優化,通過模塊化設計,可以在不同的產品中復用相同的芯片模塊,減少了開發成本。
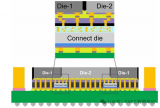
小芯片(Chiplet)架構:3.5D技術通過將傳統的單片系統芯片(SoC)分解為多個小芯片(Chiplet),并利用先進封裝技術將它們重新連接在一起。這種架構不僅提高了性能,還降低了制造成本。小芯片可以在不同的工藝節點上制造,從而優化性能和成本。例如,某些高性能計算模塊可以采用先進的工藝節點,而其他模塊可以采用更成熟的工藝節點,從而在性能和成本之間實現更好的平衡。
大規模集成:通過3D堆疊和2.5D硅中介層的結合,3.5D技術在相同的封裝尺寸內集成了更多的計算資源。這種大規模集成不僅提高了性能,還降低了單位計算能力的成本。例如,MI300X加速器通過3D堆疊技術集成了多個GPU芯片,顯著提升了并行計算能力,同時降低了單位計算能力的制造成本。
2.功耗與運營成本
低功耗互連:3.5D技術通過銅-銅混合鍵合技術實現了高密度、低功耗的互連。相比傳統的微凸點(μbump)技術,銅-銅混合鍵合技術可以顯著降低互連功耗。這對于長時間運行的AI訓練任務尤為重要,因為低功耗意味著更低的運營成本和更高的系統穩定性。
高能效:3.5D技術通過緊密集成和低延遲互連,提高了系統的整體能效。例如,MI300X加速器在AI訓練任務中的能效比顯著高于上一代產品。高能效不僅降低了功耗,還減少了散熱需求,進一步降低了運營成本。
統一內存架構:在MI300A加速器中,CPU和GPU共享統一的HBM內存空間,消除了傳統APU中CPU和GPU使用不同內存類型導致的數據傳輸延遲和冗余內存拷貝問題。這種統一內存架構不僅提高了數據傳輸效率,還減少了內存需求,從而降低了硬件成本。
3.系統級優化
緊密集成:3.5D技術通過將多個功能模塊(如CPU、GPU、HBM等)緊密集成在一個封裝內,減少了芯片之間的通信延遲,提高了系統的整體性能。這種緊密集成不僅提高了性能,還減少了系統復雜性和維護成本。
高性能與高密度:通過3D堆疊和2.5D硅中介層的結合,3.5D技術在相同的封裝尺寸內集成了更多的計算資源,從而提高了計算密度和性能。這種高性能和高密度的集成不僅提高了系統的整體性能,還減少了數據中心的物理空間需求,降低了數據中心的建設和運營成本。
快速上市時間:3.5D技術的模塊化設計和小芯片架構允許快速開發和部署新的產品,從而縮短了產品上市時間。快速上市時間不僅提高了市場競爭力,還降低了開發和運營成本。
3.5D技術通過模塊化設計、小芯片架構、低功耗互連、高能效設計和系統級優化,顯著降低了AI訓練的成本。具體來說,3.5D技術在硬件設計、制造成本、功耗和運營成本方面都取得了顯著的提升,使得AI加速器能夠更高效地處理復雜的AI訓練任務。這種技術不僅提高了系統的整體性能,還為未來的高性能計算和人工智能應用提供了強大的支持。
采用3.5D封裝架構創新不僅延續了摩爾定律的經濟效益,更開創了"超越摩爾"的新技術路徑,為下一代計算平臺提供核心支撐。
-
soc
+關注
關注
38文章
4363瀏覽量
222192 -
先進封裝
+關注
關注
2文章
467瀏覽量
576
原文標題:先進封裝技術(Semiconductor Advanced Packaging) - 20 3.5D封裝、AMD、AI訓練降本
文章出處:【微信號:深圳市賽姆烯金科技有限公司,微信公眾號:深圳市賽姆烯金科技有限公司】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
2.5D/3D封裝技術升級,拉高AI芯片性能天花板
3.5D Chiplet技術典型案例解讀
先進封裝技術-19 HBM與3D封裝仿真

3.5D封裝來了(上)
3.5D封裝來了(下)

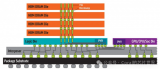
一顆芯片面積頂4顆H200,博通推出3.5D XDSiP封裝平臺
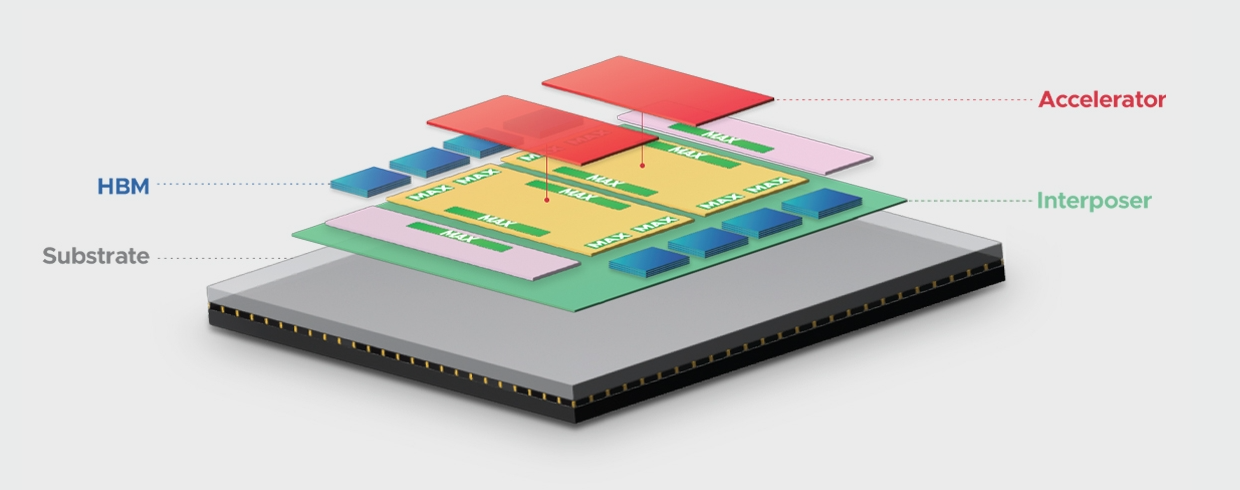
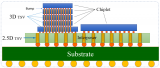
先進封裝的技術趨勢
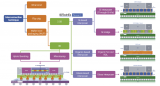
什么是3.5D封裝?它有哪些優勢?
先進封裝技術的類型簡述

AI應用致復雜SoC需求暴漲,2.5D/Chiplet等先進封裝技術的機遇和挑戰






 工商網監
工商網監
評論