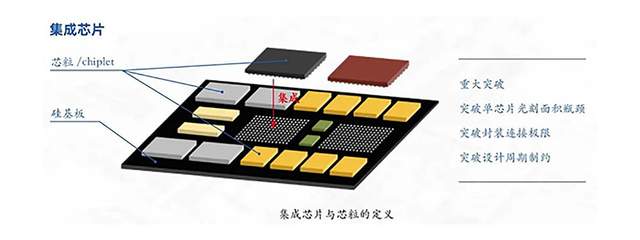
 3.5D Chiplet技術典型案例解讀
3.5D Chiplet技術典型案例解讀

大模型訓練集群的有效算力
DeepSeek的創新引領大模型基座模型向MoE專家模型進一步演進,未來大模型的參數將從千億級別向萬億參數邁進,開啟人工智能的新紀元。在這一過程中,端側推理模型的誕生離不開原研基座模型的精心訓練。隨著模型參數的不斷擴大以及AI模型的百舸爭流,訓練側所需的算力也將進一步激增。由此所依托的AI基礎設施的有效算力已成為下一代AI應用的堅實基石。
智算集群的有效算力由包括單個加速卡的基礎算力、集群規模、Scale Out與Scale Up所共同構筑的集群線性加速比以及集群有效運營的時間等多個維度因素構建。在不設資源限制的情況下,我們希望擁有最強大的單個計算卡系統來運行整個AI任務,因為,AI任務作為一個單一實體運行。因此,直接獲取最大能力的GPU/xPU是符合邏輯的選擇。
3D IC : 下一代AI芯片的加速引擎
后摩爾時代,算力的增長和芯片的性能提升之間面臨著內存墻、功耗墻、面積墻等幾大瓶頸, 采用基于先進封裝的3D Chiplet堆疊芯片帶來的重大升級將有效解決這些瓶頸。
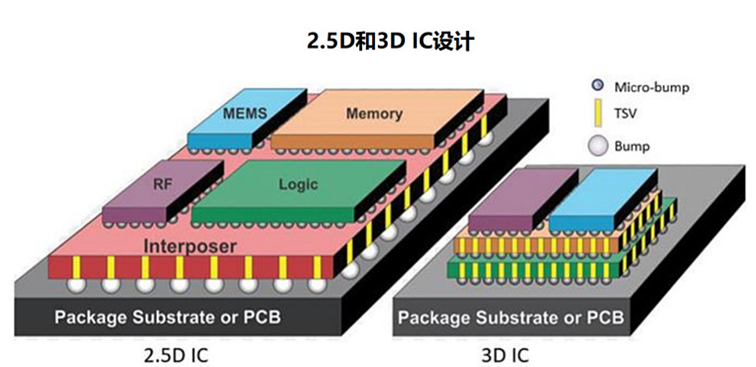
3D-IC 的優勢可概括為以下幾點:
1可以降低成本,Chiplet的解耦特性讓先進制程節點更靈活,讓非所有功能(包括模擬和存儲器)都需要遷移到先進制程節點;
2更容易滿足高速互連和帶寬要求,幫助先進存儲器技術達到 100Gbps的速度;
33D-IC 支持更小的尺寸,可以節省電路板和終端產品的空間;
43D-IC 可以降低功耗,因為不再需要大型驅動器。3D 堆疊可以使用小型 I/O 驅動器,功耗更低。此外,減少電阻-電感-電容 (RLC)寄生參數也有助于進一步降低功耗;
5減少了跨封裝之間的互連,可以實現更快的性能和更好的功耗表現。
3.5D技術的引入將顯著提升AI集群的計算密度和功耗效率,使得數據中心能夠以更低的能耗處理更大的工作負載。這對于應對生成式AI模型的指數級增長需求至關重要。本期主要介紹幾個3.5D Chiplet典型案例,分享3D IC設計架構趨勢。
典型案例1
AMD MI300 系列開創3.5D IC先河
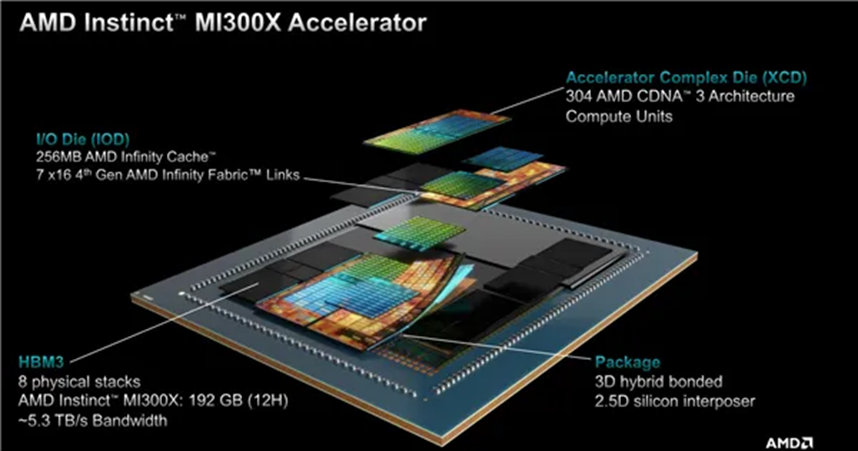
(來源:AMD)
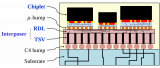
AMD是首批采用3.5D IC設計及工藝的芯片公司,2024年發布的MI300 X GPU加速器,基于新一代CDNA計算架構。其采用臺積電5nm/6nm FinETH技術,總共1530億個晶體管。
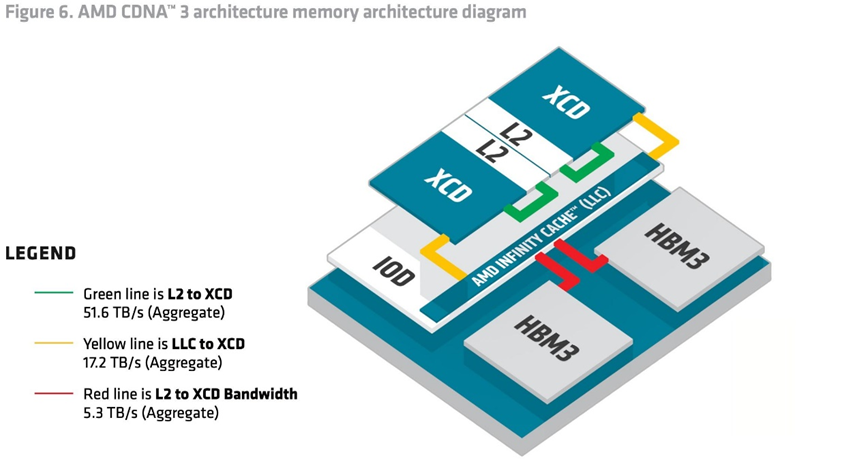
(來源:AMD Whitepaper)
XCD計算模塊:共計8個XCD加速計算模塊,每一個XCD擁有38個CU計算單位,所以總共304個計算單元。
IOD互聯模塊:每兩個XCD為一組,在它們底部放置一個IOD模塊,負責輸入輸出與通信連接,總共4個IOD提供了第四代Infinity Fabric連接通道,總帶寬最高896GB/s,還有多達256MB Infinity Cache無限緩存。該模塊實際上屬于一種3D Base Die,通過TSV硅通孔技術與XCD計算Die模塊形成高密度互聯。
HBM 部分:IOD與XCD外圍一共有8個HBM3共192GB內存(每個HBM3內存大小為24GB)。IOD部分又一次采用的是6nm工藝,XCD部分則使用5nm工藝實現計算與IO芯粒解耦,這也是AMD公司常用的一種IO Die芯粒技術。
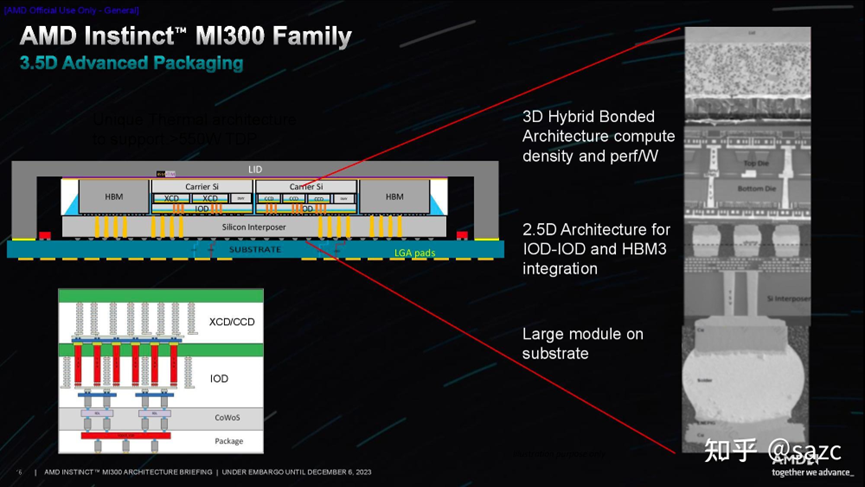
(來源:知乎@sazc)
封裝工藝:上圖顯示的是MI300A APU的封裝工藝,兩者區別主要在計算Die部分,APU系列是異構芯粒技術同時包含GPU與CPU功能。但在封裝工藝上與MI300X雷同。
8個HBM與其他芯粒使用2.5D先進封裝工藝進行互聯,而IOD模塊(Base Die)與XCD (MI300A還包括CCD)之間直接通過3D TSV堆疊封裝工藝互聯。
因此,MI300系列無論是A系列還是X系列制造工藝同時覆蓋2.5D和3D先進工藝,總稱3.5D混合封裝。
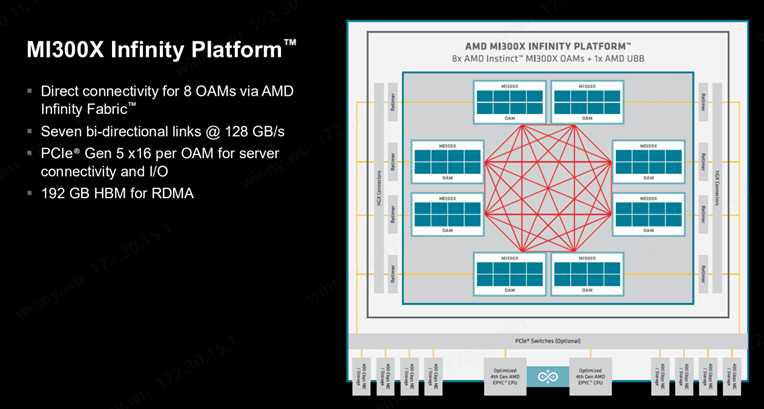
(來源:AMD)
Scale Up互聯簡介:AMD Instinct MI300X 加速器提供了采用 UBB 業界標準 OCP 平臺設計的普適性解決方案,支持將 8 個 GPU 整合為一個性能主導型節點,并且具有全互聯式點對點環形設計,單一平臺內的 HBM3 顯存總計可達到 1.5 TB提供足以應對各類 AI 或 HPC 工作負載部署的性能密集型解決方案。
典型案例2
CPO帶動Scale Out 互聯進軍百萬卡集群時代
規模生成式 AI 模型(如 DeepSeek,Grok3 系列等)的興起,對計算能力的需求呈現出了爆炸式增長。訓練這些復雜的模型往往需要龐大的計算資源,動輒依賴于 100,000 個甚至 100 萬個 XPU 的大規模集群。近期才發布的Grok 3模型,馬斯克預計下一代將搭建百萬卡AI數據中心,隨著大模型軍備賽在DeepSeek背景下展開地更加劇烈,新的互聯技術必須為未來百萬卡集群的互聯構筑可靠的基礎。
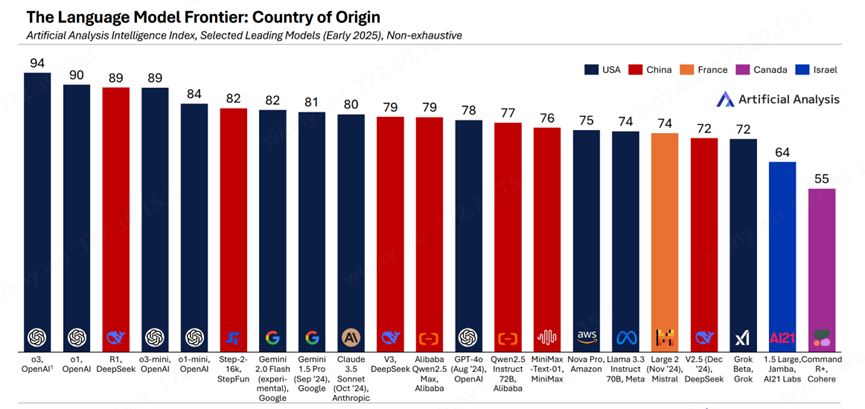
(圖:各國AI大模型軍備賽進行時)
Scale Out互聯甚至是更大規模的GPU HBD高帶寬域光進銅退的趨勢越發明顯,一種在2018年前后就被提及的光互聯技術CPO隨著AI對訓練的極高要求演進速度加快。
如果要在長程范圍集成更強大的算力/存力(Scale Out互聯),就需要借助更高帶寬的光互連技術。這也是為何目前光模塊在計算集群中廣泛使用的重要原因。集群要上升到百萬卡互聯規模,光互聯技術將發揮重要作用,傳統光模塊芯片和交換機芯片在PCB上的電信號傳輸以及GPU卡間互聯的信號損耗、功耗都遠大于單個Die to Die 互聯。目前,光模塊成為整個大型集群訓推時出現故障延遲的主要硬件之一。
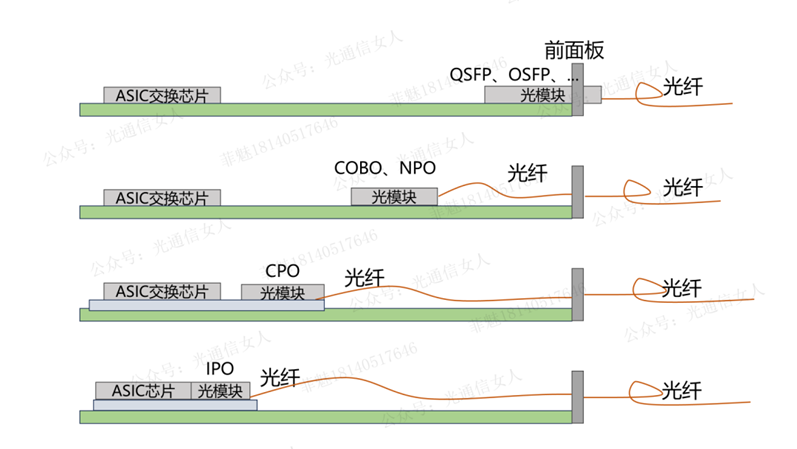
(來源:公眾號光通信女人)
CPO技術可以以解決射頻損耗的方式,將CPO光模塊與交換機主芯片ASIC專有集成電路芯片封裝在一起,降低電信號的互聯距離,從而降低射頻損耗。
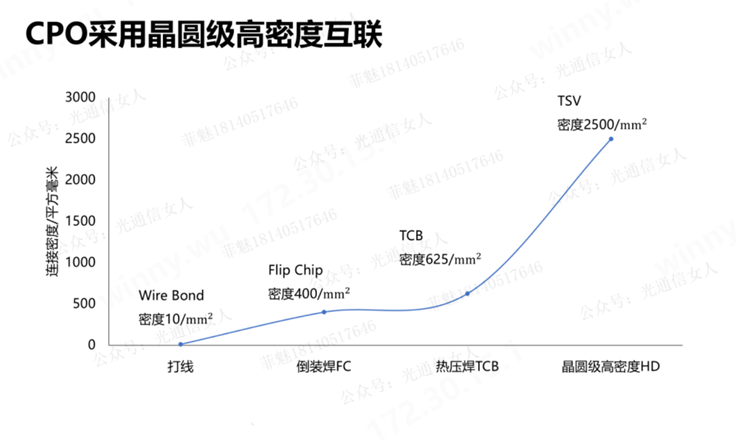
(來源:公眾號光通信女人)
目前產業界都在研究晶圓級封裝工藝,2024、2025年基于晶圓級扇出式結構,在逐步克服工藝難點,接近商用。上圖我們可以看到基于晶圓級別的3D TSV工藝實現相比其他工藝實現了更高的互聯密度。
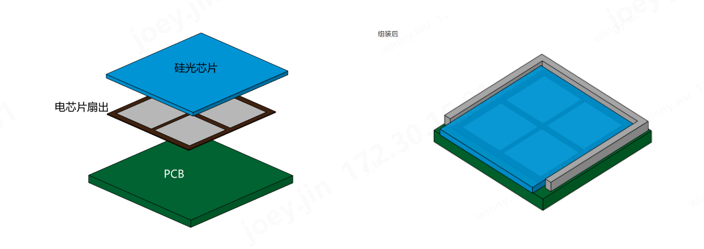
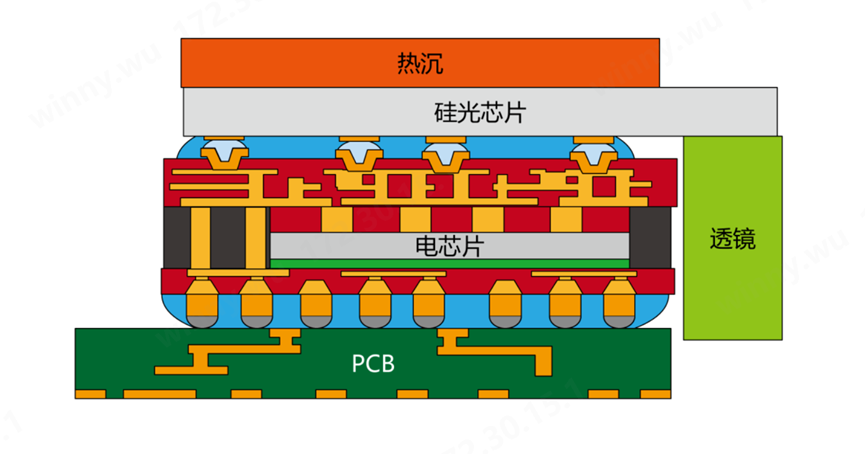
PIC(硅光芯片)通過與EIC(電芯片)進行3D堆疊,從而實現電連接更短、尺寸小、功耗低且高帶寬密度的性能。在此配置中,PIC 位于 EIC 頂部。然而,在 EIC 中創建 TSV 可能具有挑戰性,因為它通常需要在先進的晶圓節點上制造。為了克服這個問題,往往采用晶圓級扇出工藝,形成高銅柱以實現與頂部 PIC 的垂直互連。由此產生的光子 FOPOP 在光耦合方面表現出色,因為 PIC 的懸垂部分允許光邊緣耦合。
實際上,ASIC與CPO的共同封裝同樣屬于一種3.5D IC技術,從光芯片內部通過3D堆疊實現高互聯的密度,更佳的傳輸性能。在交換機芯片側,CPO OE Chiplet封裝在ASIC芯片周圍形成一個系統級的IC。以博通的典型CPO方案為例,整體封裝結構為CoWoS,計算Die(ASIC)通過Interposer/Package Substrate與CPO互連,互聯接口為高速IO(例如Serdes/D2D)。

(來源:Broadcom CPO )
目前,Nvidia也在研究基于硅光集成的CPO光學,并預計2025 Q3針對一款IB交換機啟動CPO方案的驗證。產業界更多廠家也在不斷研究并推出CPO光模塊樣機如Cisco、博通、Marvell都推出了基于CPO的交換機方案。
典型案例3
博通下一代3.5D IC大規模提升單卡算力
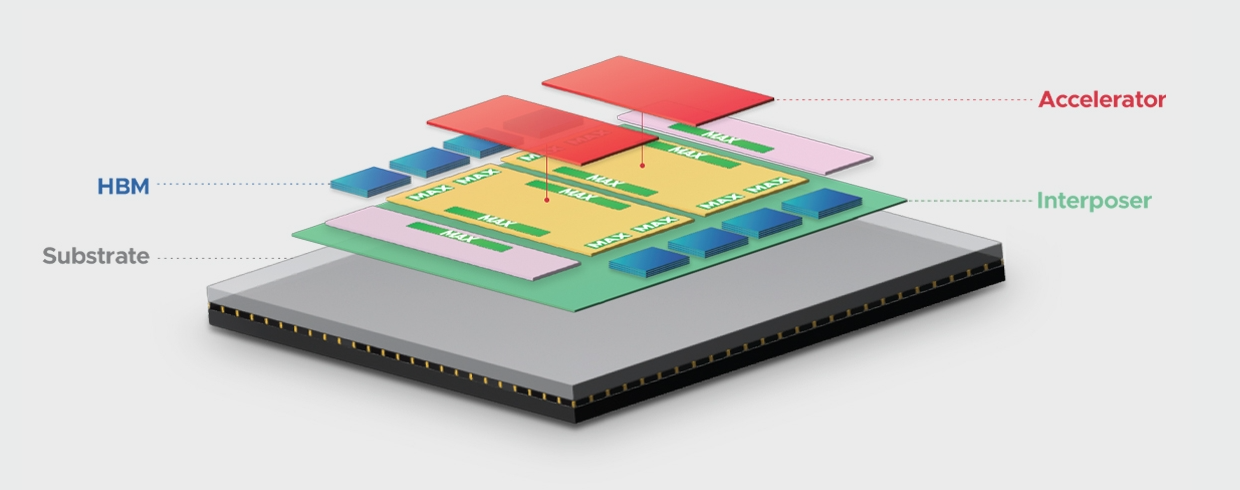
去年底Broadcom 推出了其 3.5D eXtreme Dimension 系統級封裝 (3.5D XDSiP) 平臺,該平臺適用于適用于 AI 和 HPC 工作負載的超高性能處理器。新平臺依賴于 TSMC 的 CoWoS 和其他先進封裝技術。它使芯片設計人員能夠構建 3D 堆棧邏輯、網絡和 I/O 小芯片以及 HBM 內存堆棧的系統級封裝 (SiP)。該平臺允許使用多達 12 個 HBM 模塊實現高達 6000mm2 的 3D 堆疊硅的 SiP。首批 3.5D XDSiP 產品將于 2026 年推出。
博通首次使用F2F(面對面)將一個邏輯Die堆疊到另外一個邏輯Die上;這種使用無凸塊混合銅鍵合直接連接頂部和底部硅芯片的上層金屬層的面對面 (F2F) 堆疊方法,是博通的 3D XDSiP 平臺的主要優勢。據 Broadcom 稱,F2F 方法可實現高達 7 倍的信號連接和更短的信號路由,將晶粒間接口的功耗降低 90%,最大限度地減少 3D 堆棧內的延遲,并為設計團隊提供額外的靈活性,成就更低功耗更低延遲的ASIC芯片性能。
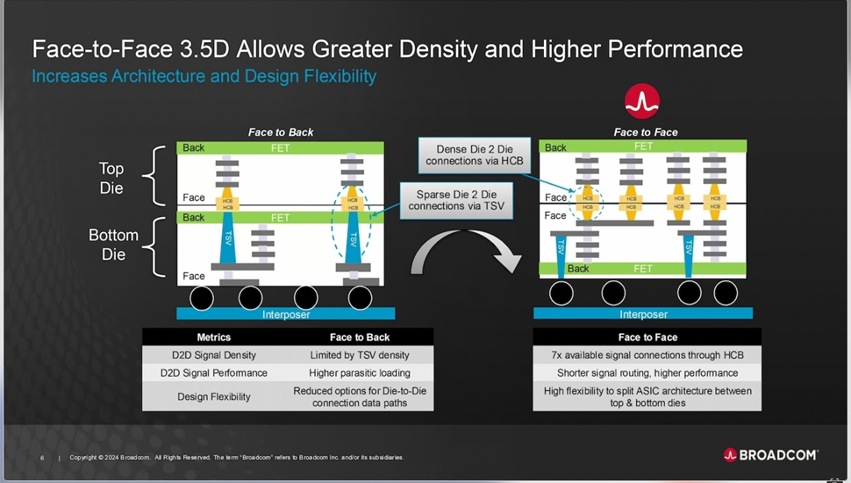
(來源:Broadcom)
此外,它巧妙地融合了 3D 硅片堆疊與 2.5D 封裝技術的精髓。該3.5D xPU計算Die與邏輯Die Face to Face進行鍵合,每個邏輯Die與多組HBM互聯,又與IOD通過D2D互聯。(更多閱讀:Chiplet&互聯專題:AI時代變革下 3D IC 芯粒技術的最新應用趨勢解讀)
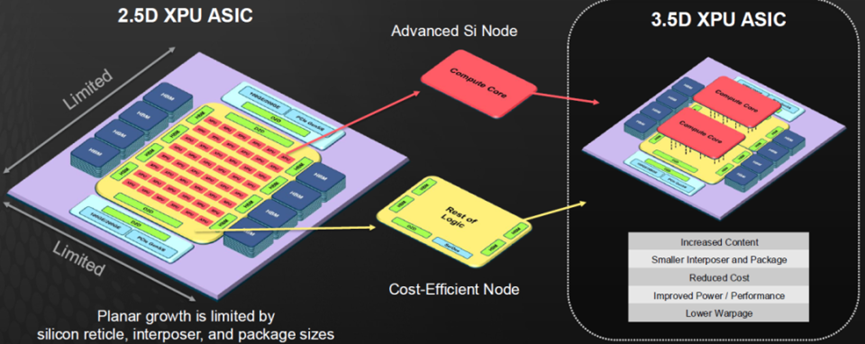
(來源:Broadcom)
總的來說,3.5D 集成技術通過將 3D 與 2.5D封裝相結合,能夠在不單純依賴制程工藝提升的情況下,實現芯片性能的顯著提升、功耗的有效降低以及成本的合理控制,從而成為了下一代 XPU 發展的必然趨勢。預計博通將繼續加大市場推廣力度,針對不同客戶的需求,提供定制化的 3.5D XPU 解決方案。
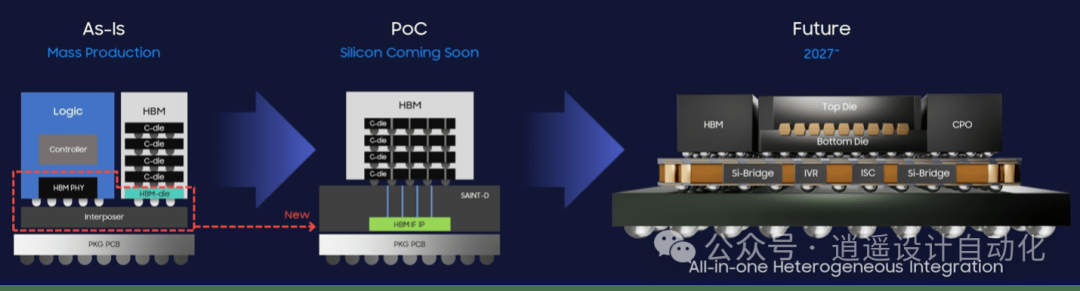
3.5D IC技術是Chiplet小芯片發展旅程中的又一重要里程碑,通過獨特的技術架構和卓越的性能表現,為 AI 芯片的發展開辟了新的道路。在技術原理層面,其高密度互連、低功耗設計、多功能集成以及緊湊尺寸與穩定性等核心要素相互協同,構成了強大的技術競爭力。
奇異摩爾自2021年成立以來先從片內互聯產品系列研發出發,目前可以提供包括2.5D Central IO Die及3D Base Die等AI單個計算卡算力擴展芯粒方案,未來通過持續性的行業標準共建、產業鏈生態的互聯互通,相信在不久的將來,隨著國產Chiplet技術的突破,我們將與產業鏈伙伴為國產AI算力的釋放潛能鋪就一條寬廣的道路,共同書寫AI智能時代的輝煌篇章。
關于我們
AI網絡全棧式互聯架構產品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業領先的AI網絡全棧式互聯產品及解決方案提供商。公司依托于先進的高性能RDMA 和Chiplet技術,創新性地構建了統一互聯架構——Kiwi Fabric,專為超大規模AI計算平臺量身打造,以滿足其對高性能互聯的嚴苛需求。
我們的產品線豐富而全面,涵蓋了面向不同層次互聯需求的關鍵產品,如面向北向Scale out網絡的AI原生智能網卡、面向南向Scale up網絡的GPU片間互聯芯粒、以及面向芯片內算力擴展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產品共同構成了全鏈路互聯解決方案,為AI計算提供了堅實的支撐。
奇異摩爾的核心團隊匯聚了來自全球半導體行業巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯產品研發和管理經驗,致力于推動技術創新和業務發展。團隊擁有超過50個高性能網絡及Chiplet量產項目的經驗,為公司的產品和服務提供了強有力的技術保障。我們的使命是支持一個更具創造力的芯世界,愿景是讓計算變得簡單。奇異摩爾以創新為驅動力,技術探索新場景,生態構建新的半導體格局,為高性能AI計算奠定穩固的基石。
-
人工智能
+關注
關注
1805文章
48904瀏覽量
248001 -
IC技術
+關注
關注
0文章
9瀏覽量
2366 -
AI芯片
+關注
關注
17文章
1978瀏覽量
35785 -
大模型
+關注
關注
2文章
3086瀏覽量
3974
原文標題:芯粒案例解讀 | 3.5D IC技術構建下一代大模型訓練集群有效算力
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
先進封裝技術:3.5D封裝、AMD、AI訓練降本

2.5D集成電路的Chiplet布局設計
解鎖Chiplet潛力:封裝技術是關鍵

3.5D封裝來了(上)
3.5D封裝來了(下)

一顆芯片面積頂4顆H200,博通推出3.5D XDSiP封裝平臺
高帶寬Chiplet互連的技術、挑戰與解決方案

Chiplet技術有哪些優勢
一文理解2.5D和3D封裝技術
最新Chiplet互聯案例解析 UCIe 2.0最新標準解讀

什么是3.5D封裝?它有哪些優勢?
IMEC組建汽車Chiplet聯盟

Primemas選擇Achronix eFPGA技術用于Chiplet平臺
國產半導體新希望:Chiplet技術助力“彎道超車”!






 工商網監
工商網監
評論