完善資料讓更多小伙伴認識你,還能領取20積分哦,立即完善>
電子發(fā)燒友網技術文庫為您提供最新技術文章,最實用的電子技術文章,是您了解電子技術動態(tài)的最佳平臺。
人類對計算機視覺感興趣的最重要的問題是圖像分類 (Image Classification)、目標檢測 (Object Detection) 和圖像分割 (Image Segmentation),同時它們的難度也是依次遞增。...

面向計算機視覺、自然語言處理、推薦系統(tǒng)、類機器人等領域量身打造了基于“達芬奇(DaVinci)架構”的昇騰(Ascend)AI處理器,開啟了智能之旅。...
生成式AI是一種特定類型的AI,專注于生成新內容,如文本、圖像和音樂。這些系統(tǒng)在大型數(shù)據(jù)集上進行訓練,并使用機器學習算法生成與訓練數(shù)據(jù)相似的新內容。這在各種應用程序中都很有用,比如創(chuàng)建藝術、音樂和聊天機器人生成文本等。最近網絡爆火的AI繪畫,就是屬于生成式 AI的推廣應用。...
? ? 先前在為大家介紹OCR識別技術時,在圖像預處理部分提到了灰度化,大家可能會產生疑惑: 為什么做圖片識別要將彩色圖像灰度化呢? ? 正式解釋這個問題之前,我們需要了解, 什么是灰度化? ? 什么是灰度化 ? 簡單地說, 灰度化處理就是將一幅彩色圖像轉化為灰度圖像的過程。 ? 當我們在電腦、電視...
卷積神經網絡是目前計算機視覺中使用最普遍的模型結構。引入卷積神經網絡進行特征提取,既能提取到相鄰像素點之間的特征模式,又能保證參數(shù)的個數(shù)不隨圖片尺寸變化。...

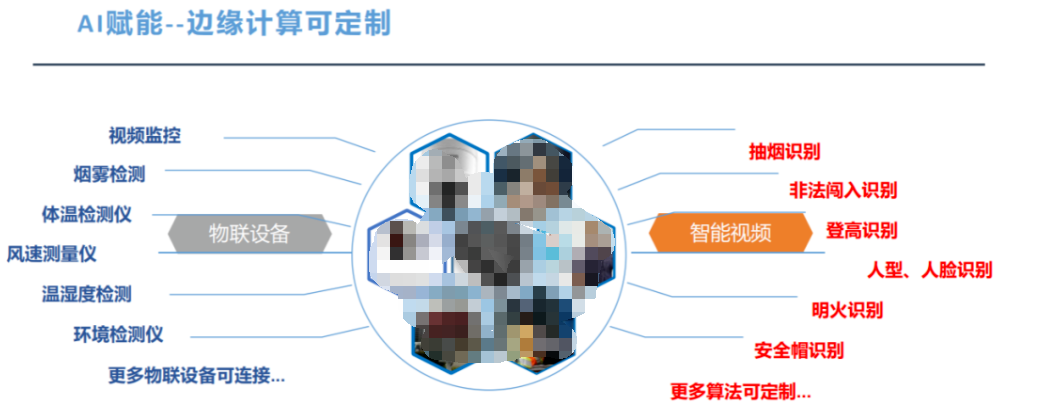
微智科技聯(lián)合江蘇禹新航運科技有限公司應用5G、物聯(lián)網、大數(shù)據(jù)、云計算、AI技術等高科技技術,通過視頻監(jiān)控、體溫檢測儀、煙霧檢測、風速測量儀、溫濕度檢測、...
AI的一大優(yōu)勢是可以對算法問題做極度的抽象,抽象之后較為復雜的工業(yè)視覺問題就會變得比較簡單,還有一個就是通用化。很多工業(yè)視覺里面比較復雜的算法問題,后面實際上用兩到三個比較通用的算法模塊去訓練數(shù)據(jù),結果就出來了,并且這個指標還非常優(yōu)秀。...

為了建立可信、可控、安全的人工智能,學術界與工業(yè)界致力于增強人工智能系統(tǒng)與算法的可解釋性。具體地,可信人工智能旨在增強人工智能系統(tǒng)在知識表征、表達能力、優(yōu)化與學習能力等方面的可解釋性與可量化性以及增強人工智能算法內在機理的可解釋性。...

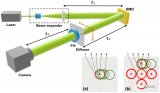
卷積神經網絡(CNN)是一種用于對目標進行重建、分類等處理的深度學習方法。自2016年深度學習被首次應用于散射成像,該研究一直是光學成像領域的熱門方向。...
與歐盟(EU)不同,英國在人工智能方面的做法短期內不會專注于新的立法。取而代之的是,它將專注于制定指導方針,賦予監(jiān)管者權力,并只在必要時采取法定行動。...
OpenCV 是 Intel 開源計算機視覺庫。它由一系列 C 函數(shù)和少量 C++ 類構成,實現(xiàn)了圖像處理和計算機視覺方面的很多通用算法。 OpenCV 擁有包括 300 多個C函數(shù)的跨平臺的中、高層 API。它不依賴于其它的外部庫——盡管也可以使用某些外部庫。...

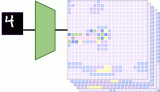
一方面AMD的半定制芯片領域將會是未來人工智能領域公司的重點投入方向之一,因為人工智能應用的大客戶(主要是互聯(lián)網科技巨頭)對于這個領域有非常大的興趣...
關于AI在軍事領域的應用已逐漸成為學術研究的焦點。從早期計算機在戰(zhàn)術決策輔助中的應用,到21世紀無人作戰(zhàn)系統(tǒng)的廣泛運用,人工智能在軍事領域得到了長足的發(fā)展,這一歷程可大致劃分為三個階段。...
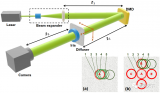
彈道光與散射光在散射成像中不同作用的發(fā)現(xiàn)解釋了深度學習散射成像無法突破厚度限制的物理原因,對今后深度學習散射成像的應用研究具有指導意義。...
通過自定義魔法命令,可以在notebook中直接調用chatgpt,無縫銜接編碼過程,不需要再多個窗口中跳來跳去...
圖神經網絡的應用場景自然非常多樣。筆者在這里選擇一部分應用場景為大家做簡要的介紹,更多的還是期待我們共同發(fā)現(xiàn)和探索。...
在本文中,我們將了解深度神經網絡的基礎知識和三個最流行神經網絡:多層神經網絡(MLP),卷積神經網絡(CNN)和遞歸神經網絡(RNN)。...

boost是一個大類,含有豐富的功能,這里直接給出安裝命令'sudo apt install libboost-all-dev -y',它主要把C++各個函數(shù)和你的模塊協(xié)調起來,增強你對API的調用,實現(xiàn)功能,隨便舉個例子:多線程。...
為了能讓基于事件相機的vSLAM在事件數(shù)據(jù)上實現(xiàn)位姿估計和三維重建,研究者設計出了多種多樣針對事件相機的數(shù)據(jù)關聯(lián)、位姿估計和三維重建的解決方案。我們將主流的算法分類為四種類別,分別為特征法、直接法、運動補償法和基于深度學習的方法。...

關注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經濟技術開發(fā)區(qū)航空路6號手機智能終端產業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網安備43011202000918 工商網監(jiān)
湘ICP備2023018690號-1
工商網監(jiān)
湘ICP備2023018690號-1




